В статье рассматривается логистическая регрессия, как один из методов машинного обучения. И применяется на основе данных больных раком.
Ключевые слова: логистическая регрессия, машинное обучение, классификация.
В современном мире неуклонно растет число людей, которые заболевают онкологическими заболеваниями. Поэтому наиболее остро стоит вопрос о преждевременном прогнозировании данного рода заболеваний. С развитием научно-технического прогресса появились методы, в частности, на основе машинного обучения, которые помогают прогнозировать эти заболевания на основе некоторых параметров.
Основная часть
Машинное обучение (англ. machine learning, ML) — класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение за счёт применения решений множества сходных задач [1].
Одной из задач, в которых может применяться машинное обучение, является классификация. В терминологии машинного обучения данная задача относится к обучению с учителем. То есть подразумевается, что данные уже разделены на классы, а признаки разделены на отдельные категории. Данные, на которых будет обучаться модель, называют обучающей выборкой.
Одним из методов классификации является логистическая регрессия. Логистическая регрессия — статистическая модель, используемая для прогнозирования вероятности возникновения некоторого события путём его сравнения с логистической кривой. [2]
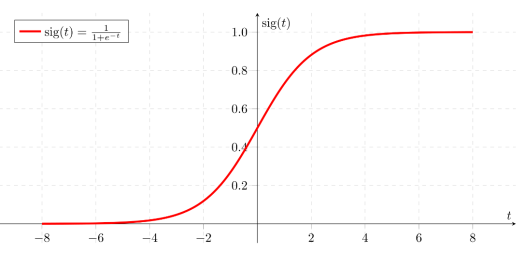
Рис. 1. График логистической кривой
Логистическая регрессия подходит только для задач бинарной классификации. Другими словами, с помощью логистической регрессии можно оценивать вероятность того, что событие наступит для конкретного испытуемого (больной/здоровый, возврат кредита/дефолт и т. д.). В случае прогнозирования рака данная задача относится как раз к случаю бинарной классификации, так как необходимо разделять пациентов на две категории: болен раком или нет.
Набор данных был собран в «Университетской больнице Каракаса», Венесуэла. Данные включают в себя демографическую информацию, привычки и историю болезни 858 пациентов. Несколько пациентов решили не отвечать на некоторые вопросы из соображений конфиденциальности (пропущенные значения) [3].
Среди столбцов содержится переменная логического типа Dx:Cancer, которая содержит информацию о том, болен ли пациент раком. Данная переменная будет взята в качестве целевой. Модели необходимо будет «предугадывать» ее значение на основе остальных 35 признаков.
Из описания набора данных известно, что в нем содержатся пропущенные значения. Для применения метода логистической регрессии эти данные необходимо предварительно обработать.
Для машинного обучения и обработки данных будет использован язык программирования Python. А также библиотеки:
- Pandas
- Numpy
- scikit-learn
Первым шагом в обработке имеющегося набора данных будет удаление из него всех значений с пропусками.

После удаления всех строк, содержащих пропуски, необходимо разделить набор признаков для обучения и значения целевой переменной. А также на обучающую и тестовую выборки. Это нужно, чтобы обучение модели происходило на одних данных, а тестирование модели — на других, причем эти данные не должны пересекаться.

После выполнения обработки на выходе получится 4 множества с данными: Обучающие и тестовые выборки без ответов (X_train, X_test) и 2 множества ответов (y_train, y_test), которые разделены в том же соотношении, что и X_train, X_test. Соотношение, в котором будут разделены данные на обучающую и тестовую выборки, задается в параметре test_size.
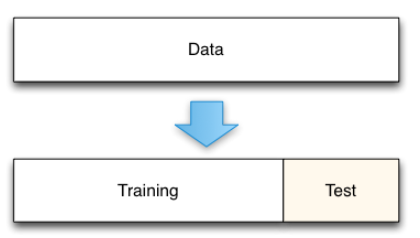
Рис. 2. Разделение данных на обучающую и тестовую выборки
Теперь данные готовы к применению метода логистической регрессии. Для этого нужно применить библиотеку scikit-learn.

После обучения был получен массив данных predict, в котором содержится результат работы предсказания модели для тестовой выборки. Чтобы узнать, насколько точно модель справилась с предсказанием, нужно узнать значение метрик. Для этого можно применить функцию classification_report библиотеки scikit-learn.
Таблица 1
Основные метрики классификации.
|
precision |
recall |
f1-score |
support | |
|
0 |
0.99 |
1.00 |
1.00 |
215 |
|
1 |
1.00 |
0.67 |
0.80 |
6 |
|
accuracy |
0.99 |
221 | ||
|
macro avg |
1.00 |
0.83 |
0.90 |
221 |
|
weighted avg |
0.99 |
0.99 |
0.99 |
221 |
На основании полученных метрик можно сделать вывод, что модель верно определила всех тех людей, которых пометила как больных раком. Об этом свидетельствует метрика precision, которая определяет фактическую точность модели (долю совпавших ответов с фактическими). Однако ошибочно не дала этот диагноз некоторым людям, которые по итогу раком также больны. Данный вывод можно сделать по метрике recall, которая говорит о полноте правильных ответов, то есть о доле правильных ответов.
Заключение
В ходе данной статьи был рассмотрен один из методов машинного обучения — логистическая регрессия, применяемый для решения задачи классификации. Выполнена обработка данных, и на их основе было произведено машинное обучение. По полученным результатам предсказания модели вычислено значение метрик. Из них можно сделать вывод, что модель показала отличный результат. Это можно объяснить тем, что была взята малая выборка. Для более корректной оценки нужно рассматривать выборки с большим объемом данных.
Литература:
1. Машинное обучение. — Текст: электронный // Wikipedia: [сайт]. — URL: https://ru.wikipedia.org/wiki/ %D0 %9C %D0 %B0 %D1 %88 %D0 %B8 %D0 %BD %D0 %BD %D0 %BE %D0 %B5_ %D0 %BE %D0 %B1 %D1 %83 %D1 %87 %D0 %B5 %D0 %BD %D0 %B8 %D0 %B5 (дата обращения: 05.04.2023).
2. Логистическая регрессия. — Текст: электронный // Wikipedia: [сайт]. — URL: https://ru.wikipedia.org/wiki/ %D0 %9B %D0 %BE %D0 %B3 %D0 %B8 %D1 %81 %D1 %82 %D0 %B8 %D1 %87 %D0 %B5 %D1 %81 %D0 %BA %D0 %B0 %D1 %8F_ %D1 %80 %D0 %B5 %D0 %B3 %D1 %80 %D0 %B5 %D1 %81 %D1 %81 %D0 %B8 %D1 %8F (дата обращения: 05.04.2023).
3. Cervical cancer (Risk Factors) Data Set. — Текст: электронный // UCI Machine Learning Repository: [сайт]. — URL: https://archive.ics.uci.edu/ml/datasets/Cervical+cancer+ %28Risk+Factors %29 (дата обращения: 05.04.2023).

