В статье автор рассматривает деревья решений как один из методов машинного обучения для решения задачи классификации. Метод применяется на наборе данных пациентов, больных раком шейки матки. С помощью деревьев решений производится оценка важности признаков, влияющих на развитие рака.
Ключевые слова: машинное обучение, классификация, деревья решений.
Введение
С каждым днем количество людей, которые заболевают различными онкологическими заболеваниями, продолжает увеличиваться. На передний план выходит задача определения конкретных признаков, которые провоцируют развитие болезни. Определение данных признаков может помочь при профилактике болезни. Для определения подобных признаков могут применяться различные методы, в том числе и на основе машинного обучения. С его помощью можно изучать влияние различных признаков на факт наличия заболевания.
Основная часть
Для того чтобы оценить влияние конкретных признаков, можно использовать деревья решений. Деревья решений — это иерархический метод, который можно применить для задач классификации и прогнозирования. Иерархические методы сводятся к построению иерархических структур, самой простой из которых является древовидная.
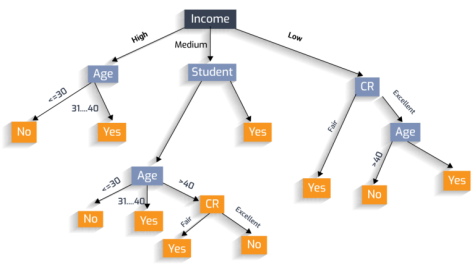
Рис. 1. Пример дерева решений
Датасет для исследования содержит информацию о больных раком шейки матки. Набор данных был собран в «Университетской больнице Каракаса» в Каракасе, Венесуэла. Данные включают в себя демографическую информацию, привычки и историю болезни 858 пациентов. Несколько пациентов решили не отвечать на некоторые вопросы из соображений конфиденциальности (пропущенные значения). [1]
Таблица 1
Свойства параметров датасета
|
Название параметра |
Тип данных |
Количество ненулевых строк |
|
Age |
int |
858 |
|
Number of sexual partners |
int |
832 |
|
First sexual intercourse (age) |
int |
851 |
|
Num of pregnancies |
int |
802 |
|
Smokes |
bool |
845 |
|
Smokes (years) |
int |
845 |
|
Smokes (packs/year) |
int |
845 |
|
Hormonal Contraceptives |
bool |
750 |
|
Hormonal Contraceptives (years) |
int |
750 |
|
IUD |
bool |
741 |
|
IUD (years) |
int |
741 |
|
STDs |
bool |
753 |
|
STDs (number) |
int |
753 |
|
STDs:condylomatosis |
bool |
753 |
|
STDs:cervical condylomatosis |
bool |
753 |
|
STDs:vaginal condylomatosis |
bool |
753 |
|
STDs:vulvo-perineal condylomatosis |
bool |
753 |
|
STDs:syphilis |
bool |
753 |
|
STDs:pelvic inflammatory disease |
bool |
753 |
|
STDs:genital herpes |
bool |
753 |
|
STDs:molluscum contagiosum |
bool |
753 |
|
STDs:AIDS |
bool |
753 |
|
STDs:HIV |
bool |
753 |
|
STDs:Hepatitis B |
bool |
753 |
|
STDs:HPV |
bool |
753 |
|
Number of diagnosis |
int |
858 |
|
Time since first diagnosis |
int |
71 |
|
Time since last diagnosis |
int |
71 |
|
Dx:Cancer |
bool |
858 |
|
Dx:CIN |
bool |
858 |
|
Dx:HPV |
bool |
858 |
|
Dx |
bool |
858 |
|
Hinselmann |
bool |
858 |
|
Schiller |
bool |
858 |
|
Cytology |
bool |
858 |
|
Biopsy |
bool |
858 |
Среди этих параметров содержится переменная «Dx:Cancer» логического типа, в которой хранится информация о том, болен пациент раком или нет. Модели необходимо будет оценить степень влияния каждого из остальных 35 признаков на переменную «Dx:Cancer»
Для данной задачи будет использован язык программирования Python. А также следующие библиотеки:
- Pandas
- Numpy
- scikit-learn
- matplotlib
Прежде чем к имеющемуся набору данных применять машинное обучение, их необходимо предварительно подготовить. Вначале необходимо удалить все значения строки с неопределенными значениями.
Следует обратить внимание, что переменные «Time since first diagnosis» и «Time since last diagnosis» имеют ненулевые значения лишь в 71 строке. Так как это весьма мало относительно общих размеров выборки, данные параметры стоит исключить из датасета.
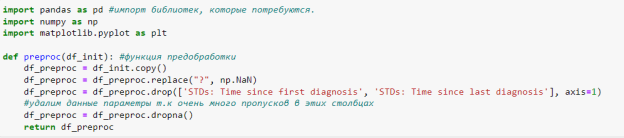
После первичной предобработки данных осталось 668 строк с пациентами, каждая из которых содержит ненулевые параметры. Дальнейшим шагом будет разделение набора данных на 2 множества: данные для обучения и ответы. Где переменная «X» — множество признаков, а «y» — множество ответов (целевая переменная)

Для эффективного применения деревьев решений нужно подобрать для нее значения гиперпараметров. Гиперпараметр — параметр в машинном обучении, значение которого используется для управления процессом обучения. [2]
Один из гиперпараметров деревьев решений — это глубина дерева. Для оценки его эффективности при различных значениях будет использована ROC-кривая.
ROC-кривая (англ. receiver operating characteristic, рабочая характеристика приёмника) — график, позволяющий оценить качество бинарной классификации, отображает соотношение между долей объектов от общего количества носителей признака, верно классифицированных как несущие признак (англ. true positive rate, TPR, называемой чувствительностью алгоритма классификации), и долей объектов от общего количества объектов, не несущих признака, ошибочно классифицированных как несущие признак(англ. false positive rate, FPR, величина 1-FPR называется специфичностью алгоритма классификации) при варьировании порога решающего правила. [3]

Для инициализации модели используется классификатор DecisionTreeClassifier из библиотеки scikit-learn. Далее формируется валидационная кривая. При ее создании ей передаются следующие параметры: model — исследуемая модель; X, y — множества признаков и ответов; param_name — имя параметра, который будет варьироваться; param_range — диапазон значений, которые будет оцениваться; cv — параметры кросс-валидации.
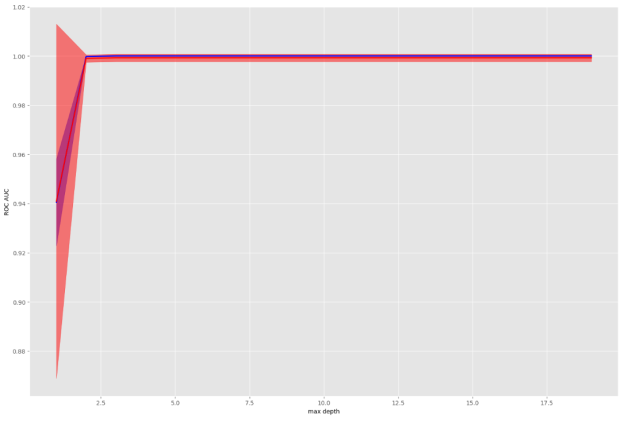
Рис. 2. ROC-кривая для параметра max_depth
Согласно ROC-кривой, оптимальное значение глубины дерева равно 2. При значениях глубины больше 2 результат эквивалентен.
Обычно подбирают гиперпараметры целыми группами. Это делается для того, чтобы ускорить процедуру поиска и сразу найти оптимальное сочетание параметров. Есть несколько способов это сделать:
— Полный перебор (Grid Search) — явно задаются все возможные значения параметров. Далее перебираются все возможные комбинации этих параметров.
— Случайный перебор (Random Search) — для некоторых параметров задается распределение через функцию распределения. Задается количество случайных комбинаций, которых требуется перебрать.
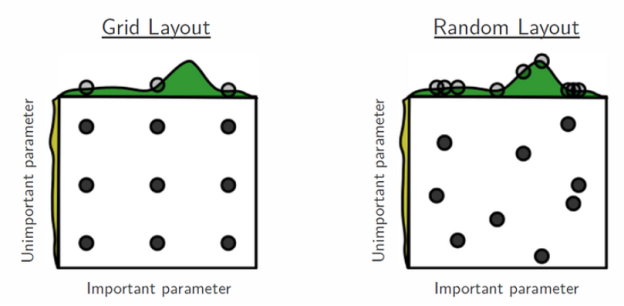
Рис. 3. Принцип работы полного и случайного переборов
Для подбора оптимальных параметров модели будет использован случайный поиск. Чтобы его использовать, необходимо воспользоваться классом RandomizedSearchCV из библиотеки scikit-learn.
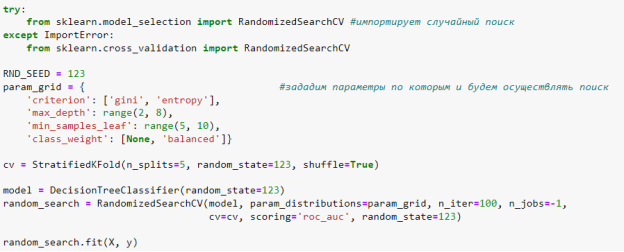
После выполнения случайного поиска в переменной random_search будут храниться результаты проделанного поиска. При обращении к атрибуту «best_estimator_» можно получить модель, полученную из тех гиперпараметров, которые дали наилучший результат. А при обращении к атрибуту «feature_importances_» самой модели можно извлечь степень влияния признаков на результат.
Таблица 2
Важность признаков исходного датасета
|
Название параметра |
Тип данных |
Важность признака |
|
Age |
int |
0.000000 |
|
Number of sexual partners |
int |
0.000000 |
|
First sexual intercourse (age) |
int |
0.000000 |
|
Num of pregnancies |
int |
0.000000 |
|
Smokes |
bool |
0.000000 |
|
Smokes (years) |
int |
0.000000 |
|
Smokes (packs/year) |
int |
0.000000 |
|
Hormonal Contraceptives |
bool |
0.000000 |
|
Hormonal Contraceptives (years) |
int |
0.000000 |
|
IUD |
bool |
0.000000 |
|
IUD (years) |
int |
0.012155 |
|
STDs |
bool |
0.000000 |
|
STDs (number) |
int |
0.000000 |
|
STDs:condylomatosis |
bool |
0.000000 |
|
STDs:cervical condylomatosis |
bool |
0.000000 |
|
STDs:vaginal condylomatosis |
bool |
0.000000 |
|
STDs:vulvo-perineal condylomatosis |
bool |
0.000000 |
|
STDs:syphilis |
bool |
0.000000 |
|
STDs:pelvic inflammatory disease |
bool |
0.000000 |
|
STDs:genital herpes |
bool |
0.000000 |
|
STDs:molluscum contagiosum |
bool |
0.000000 |
|
STDs:AIDS |
bool |
0.000000 |
|
STDs:HIV |
bool |
0.000000 |
|
STDs:Hepatitis B |
bool |
0.000000 |
|
STDs:HPV |
bool |
0.000000 |
|
Number of diagnosis |
int |
0.000000 |
|
Dx:CIN |
bool |
0.000000 |
|
Dx:HPV |
bool |
0.987845 |
|
Dx |
bool |
0.000000 |
|
Hinselmann |
bool |
0.000000 |
|
Schiller |
bool |
0.000000 |
|
Cytology |
bool |
0.000000 |
|
Biopsy |
bool |
0.000000 |
Заключение
В ходе данной статьи был рассмотрен иерархический метод машинного обучения для задачи классификации. С помощью случайного поиска были подобраны оптимальные гиперпараметры для создания модели деревьев решений. С помощью этой модели было выявлено два наиболее влияющих признака на заболевание раком шейкой матки среди пациентов данной выборки. Это «Dx:HPV» (вирусы папилломы человека) и «IUD (years)» (внутриматочная спираль).
Литература:
1. Cervical cancer (Risk Factors) Data Set. — Текст: электронный // UCI Machine Learning Repository: [сайт]. — URL: https://archive.ics.uci.edu/ml/datasets/Cervical+cancer+ %28Risk+Factors %29 (дата обращения: 29.04.2023).
2. Гиперпараметр (машинное обучение). — Текст: электронный // Wikipedia: [сайт]. — URL: https://ru.wikipedia.org/wiki/ %D0 %93 %D0 %B8 %D0 %BF %D0 %B5 %D1 %80 %D0 %BF %D0 %B0 %D1 %80 %D0 %B0 %D0 %BC %D0 %B5 %D1 %82 %D1 %80_(%D0 %BC %D0 %B0 %D1 %88 %D0 %B8 %D0 %BD %D0 %BD %D0 %BE %D0 %B5_ %D0 %BE %D0 %B1 %D1 %83 %D1 %87 %D0 %B5 %D0 %BD %D0 %B8 %D0 %B5) (дата обращения: 30.04.2023).
3. ROC-кривая. — Текст: электронный // Wikipedia: [сайт]. — URL:https://ru.wikipedia.org/wiki/ROC- %D0 %BA %D1 %80 %D0 %B8 %D0 %B2 %D0 %B0 %D1 %8F (дата обращения: 30.04.2023).

