В статье рассматриваются стратегии для применения различных инструментов машинного обучения и компьютерного зрения в медицине и ключевые инструменты, необходимые для этого, применительно к анализу данных с медицинскими снимками.
Ключевые слова: нейронная сеть, машинное обучение, трансферное обучение, визуализация данных, компьютерное зрение, процесс обучения.
Импорт необходимых библиотек и датасета
Для работы с датасетом в первую очередь необходимо импортировать библиотеки и сам датасет.
Модуль python os для работы с пространством имён на текущей операционной системей. С помощью него осуществляется доступ к различным файлам хранящимся в памяти компьютера.
Библиотека numpy для работы с числовыми данными имеет основные операции по работе с массивами и поддерживает математические действия для массивов.
Pandas библиотека для работы с большими объёмами данных предоставляет множество инструментов, удобных для индексации реструктуризации и предобработки данных
Matplotlib, seaborn библиотеки python, которые предоставляют возможность выводить данные в виде графиков, диаграмм и других различных средств визуализации информации.
Zipfile — это модуль python, который даёт возможность работать со стандартным форматом файлов для архивированных данных.
Cv2 библиотека, предназначенная для работы с изображениями, имеет ряд преимуществ по выполнению параллельных вычислений и работы с массивами, имеет реализацию на нескольких востребованных языках программирования, в том числе и на python.
Skimage — модуль python для предобработки изображений с открытым исходным кодом.
Random — модуль генератор псевдослучайных чисел.
Glob — модуль, предназначенный для нахождения пути файлов в директории, так же как и модуль os используется для работы с файлами
Sklearn — библиотека, предназначенная специально для решения проблем data science, содержит в себе большое количество инструментов от предобработки данных до кластерного анализа.
Данные библиотеки необходимы для работы с данными, по большей части они имеют второстепенное значение при составлении непосредственно модели машинного обучения. При этом следует осознавать их важность, так как без правильной подготовки и предобработки данных дальнейший результат невозможен.
Для создания модели машинного обучения в данном примере использован пакет TensorFlow и входящий в него Keras.
TensorFlow библиотека для машинного обучения, которая является проектом компании Google, благодаря своему удобству и оптимизации используется не только в частных проектах компании, но так же в различных исследованиях. TensorFlow имеет реализации как для python, так и для других языков, таких как R, C++, Java и др. С помощью архитектуры CUDA имеет возможность проводить параллельные вычисления как на процессорах CPU, так и GPU.
В данном примере использованы следующие модули.
Keras.sequential — позволяет преобразовать список существующих слоев в модель для обучения.
Keras.layers — используется для обозначения слоя внутри keras.sequential.
Keras.optimizers — открывает доступ к различным оптимизаторам применяемым для обучения нейронной сети, таким как SGD, Adam.
Keras.model — позволяет группировать слои в модель с признаками для обучения.
keras.initializers — предназначен для инициализации параметров нейронной сети, открывает пользователю доступ к разного вида алгоритмам инициализации данных, таких как: Xavier initialization, glorot_uniform.
Keras.utils.plot — преобразовывает тип файла модели для сохранения и работы с ним.
tf.keras.callbacks — используется для построения callback функции.
tf.keras.backend — бэкенд API для использования с другими приложениями.
Использование функции pd.read_csv создает датафрейм на основе csv файла [1].
Визуализация данных
Для полноценной обработки данных необходимо визуализировать изображения для восприятия ключевых особенностей визуализируемой информации. Так же необходимо для анализа соотношения классов и сбалансированности примеров, поступающих на вход обучаемой модели, провести визуализацию данных в разрезе классифицируемых типов. Машинное обучение при том, что существует большое количество библиотек, нуждается в четкой регулировке со стороны профессионала.
Именно на стадии визуализации данных принимается решение о стратегии развитии нейронной сети. Процесс развития нейронной сети носит циклический итерационный характер. Этот процесс состоит из анализа ошибок, изменение кода на основе выявленных ошибок, тестирование.
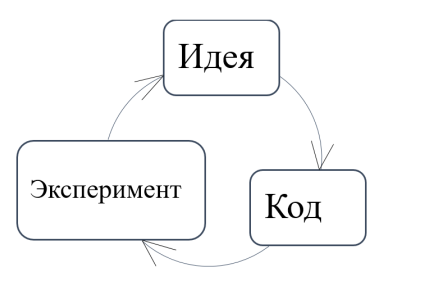
Рис. 1. Итерационная структура процесса машинного обучения
Качественная визуализация данных и их осмысление — важный этап, ведь именно данные — это та основа на которой будет строится вся нейронная сеть. Основные факторы, которые следует рассмотреть.
- Достаточность объёма данных при тренировке нейронной сети.
- Соотношение классов в датасете. Имеется ли значителььный перекос в сторону одного из классов.
- Соответствие обучающего материала целям исследования. На сколько имеющийся материал схож с тем на котором классификационной модели предстоит работать в будущем [2].
При существовании проблем с обучающим датасетом даже самые передовые модели будут давать значительный процент ошибки. Поэтому одна из первых проблем исследователя — обеспечить процесс обучения необходимым количеством данных.
При создании нейронной сети глубокого обучения на первых слоях нейронной сети как правило, идёт анализ примитивных структур изображений, таких как линии, точки и т. д. И лишь на последних слоях нейронной сети исследуются сложные понятия. За счёт этого есть возможность применения метода трансферного обучения. Суть его состоит в том, что на первых слоях нейронная сеть может обучаться на материале, не относящемся к целевому датасету, например, можно использовать слои из уже обученной сети, с готовыми коэффициентами, и лишь на последний слоях произвести процесс обучения, который будет опираться на целевой датасет. Это можно сравнить с обучением специальным навыкам у человека, например, имея опыт классификации зрительных образов, человеку не требуется учиться заново, он лишь различает основные паттерны на рентгеновском снимке и в последствии лишь применяет уже имеющиеся у него знания.
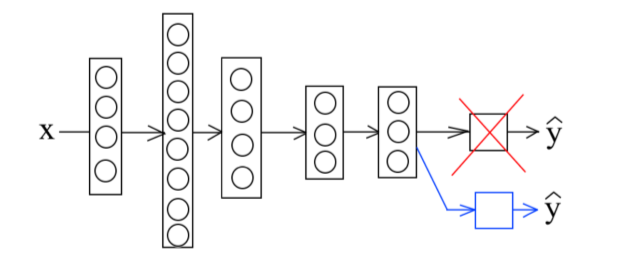
Рис. 2. Схематичное изображение трансферного обучения
Допустим, есть определенная задача А и задача Б из сходной области, к примеру распознавание изображений. Трансферное обучение подразумевает импорт низкоуровневых слоев задания А и применение их при создании классификатора Б. Подобный подход можно применить только в случае, если:
- Задачи А и Б имеют одинаковый вид входных данных х .
- У вас есть большое количество данных для задания А и при этом недостаёт данных для задания Б.
- Низкоуровневые признаки из исследования А, могут быть полезны при обучении Б.
В данном примере при визуализации данных
Рассмотрели интерактивные графики соотношения
import plotly.graph_objects as go # using plotly to create interactive plots
fig = go.Figure([go.Bar(x=brain_df ['mask'].value_counts().index,
y=brain_df ['mask'].value_counts(),
width= [.4,.4]
)
])
fig.update_traces(marker_color='rgb(158,202,225)', marker_line_color='rgb(8,48,107)',
marker_line_width=4, opacity=0.4
)
fig.update_layout(title_text=«Mask Count Plot»,
width=700,
height=550,
yaxis=dict(
title_text=«Count»,
tickmode=«array»,
titlefont=dict(size=20)
)
)
fig.update_yaxes(automargin=True)
fig.show()
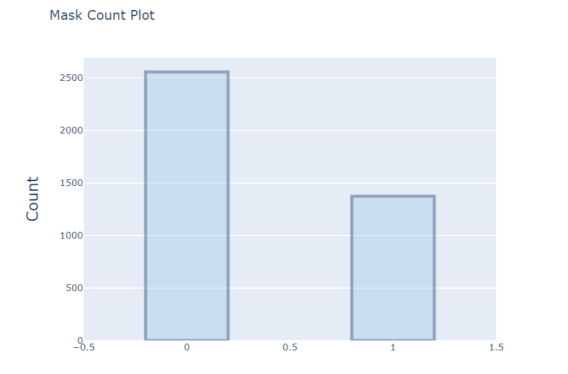
Рис. 3. Соотношение отрицательных (0) и положительных (1) результатов исследования
В нашем случае присутствует МРТ мозга, каждому МРТ соответствует маска, определяющая изменения в мозге, сделанная вручную врачами, наша цель создать нейронную сеть, которая могла бы выделять данную маску автоматически.

Рис. 4. Пример маски, которая является конечным результатом исследуемой модели
Создание тренировочного, валидационного и тестового сета.
Во-первых, необходимо конвертировать данные в столбце mask, в строковый формат.
brain_df_train ['mask'] = brain_df_train ['mask'].apply(lambda x: str(x))
RangeIndex: 3929 entries, 0 to 3928
Data columns (total 3 columns):
# Column Non-Null Count Dtype
—-- ------ -------------- -----
0 image_path 3929 non-null object
1 mask_path 3929 non-null object
2 mask 3929 non-null object
dtypes: object(3)
memory usage: 92.2+ KB
В результате мы получаем датасет общим объёмом 3929 ненулевых объектов.
Данный датасет следует разделить на три части.
Одним из удобных способов разделение является использование модуля sklearn и его встроенном методе train_test_split().
from sklearn.model_selection import train_test_split
train, test = train_test_split(brain_df_train, test_size=0.15)
Затем для создания из изображений в директории датасета, в нужном для обработки нейросетью виде используем функцию TensorFlow ImageDataGenerator.
Литература:
- Mateusz, Buda Brain MRI images together with manual FLAIR abnormality segmentation masks / Buda Mateusz. — Текст: электронный // kaggle.com: [сайт]. — URL: https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation (дата обращения: 24.03.2021).
- Hidden Technical Debt in Machine Learning Systems / D. Sculley, Holt Gary, Golovin Daniel [и др.]. — Текст: непосредственный // Advances in Neural Information Processing Systems. — 2015. — № 28. — С. 202–211.
- Pınar, CİHAN A Review of Machine Learning Applications in Veterinary Field / CİHAN Pınar, GÖKÇE Erhan, KALIPSIZ Oya. — Текст: непосредственный // Kafkas Universitesi Veteriner Fakultesi Dergisi. — 2017. — № 23. — С. 673–680.
- Jonathan, Waring Automated machine learning: Review of the state-of-the-art and opportunities for healthcare / Waring Jonathan, Lindvall Charlotta, Umeton Renato. — Текст: непосредственный // Artificial Intelligence in Medicine. — 2020. — № 104.

