Рассмотрено использование методов машинного обучения для анализа данных, с целью предсказания остаточных средств в банкомате. Разработаны и протестированы несколько моделей для предсказания количества денежных средств в банкомате.
Ключевые слова: машинное обучение, банкоматы, регрессионный анализ, искусственные нейронные сети.
The use of machine learning methods for data analysis in order to predict the remaining funds in an ATM is considered. Several models have been developed and tested to predict the amount of cash in an ATM.
Keywords: machine learning, ATMs, regression analysis, artificial neural networks.
Потребность в наличных деньгах в банкоматах требует точного прогноза. Здесь наличные деньги — это товар, который необходимо пополнять в течение заранее установленного периода времени. Неверный прогноз влечет за собой значительные расходы для бизнеса. Например, если прогнозируется, что наличные деньги превышают фактическую потребность, то неиспользованные наличные, хранящиеся в банкомате, приводят к расходам для банка. Банк оплачивает разные расходы на повторное наполнение в зависимости от своей политики с логистической компанией. Значительная сумма обычно оплачивается фиксированными сборами за повторное наполнение, дополнительные расходы на транспортировку с обеспечением безопасности. Некоторые банки могут хранить в банкоматах на 40 % больше наличных, чем фактический спрос, и у банков могут быть тысячи банкоматов по всей стране. Таким образом, небольшая оптимизация бизнес-операций будет способствовать увеличению прибыли.
Цель нашего исследования — создание и сравнение моделей машинного обучения, для возможности предсказания остатка денежных средств в банкомате, на основе имеющихся факторов.
Для построения моделей машинного обучения используется язык программирования Python. Python — высокоуровневый язык программирования, ориентированный на повышение производительности разработчика, читаемости кода и его качества, а также на обеспечение переносимости написанных на нём программ. Язык является полностью объектно-ориентированным в том плане, что всё является объектами. Сам же язык известен как интерпретируемый и используется в том числе для написания скриптов [1].
Данные для анализа взяты с сайта kaggle.com. [2] Входные данные представлены в виде файла формата csv, содержащего данные о банкоматах. Файл с входными данными содержит 2244 строки и 10 показателей (Рисунок 1).
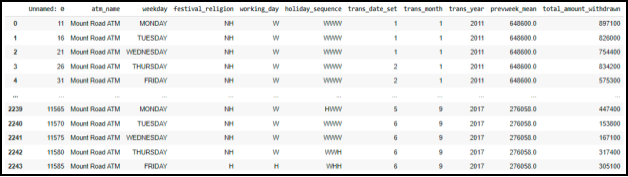
Рис. 1. формат входных данных
Входные переменные csv файла, содержащего рейтинг университетов по версии Times:
- Atm_name — название банкомата (Mount Road ATM у всех записей);
- Weekday — день недели (Понедельник, Вторник и т. д.);
- Festival_religion — религиозные праздники (NH, H, N, C, M);
- Working_day — рабочий или выходной день (Праздник H или Рабочий день W);
- Holiday_sequence — последовательность праздников (Рабочий-рабочий-праздник, рабочий-праздник-праздник и т. д.);
- Trans_date_set — день отправки данных (1–7);
- Trans_month — месяц (1–12);
- Trans_year — год (2011–2017);
- Prevweek_mean — среднее за предыдущую неделю (число);
- Total_amount_withdrawn — количество снятых денег (число).
Проведем статистический анализ данного файла. Основную информацию о выборке можно получить, используя функцию “ data.describe()” языка Python. Эта функция сообщает минимальное и максимальное значения, медиану, среднее, первый, и третий квартиль задаваемого параметра (Рисунок 2).
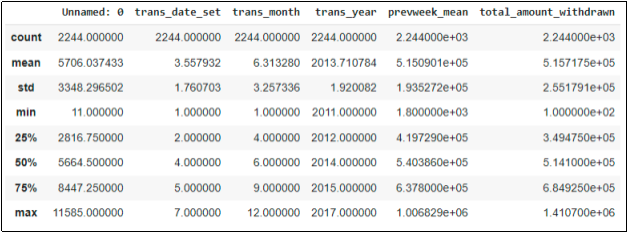
Рис. 2. Статистический анализ данных
Для анализа будем использовать несколько моделей машинного обучения. Первый из них это «Регрессионный анализ».
Регрессионный анализ — это метод изучения статистической взаимосвязи между одной зависимой количественной зависимой переменной от одной или нескольких независимых количественных переменных. Зависимая переменная в регрессионном анализе называется результирующей, а переменные факторы — предикторами или объясняющими переменными.
Взаимосвязь между средним значением результирующей переменной и средними значениями предикторов выражается в виде уравнения регрессии. Уравнение регрессии — математическая функция, которая подбирается на основе исходных статистических данных зависимой и объясняющих переменных. Чаще всего используется линейная функция. В этом случае говорят о линейном регрессионном анализе. Линейная регрессия определяется как (1):
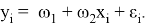
Регрессионный анализ очень тесно связан с корреляционным анализом. В корреляционном анализе исследуется направление и теснота связи между количественными переменными. В регрессионном анализе исследуется форма зависимости между количественными переменными. Т. е. фактически оба метода изучают одну и ту же взаимосвязь, но с разных сторон, и дополняют друг друга. На практике корреляционный анализ выполняется перед регрессионным анализом. После доказательства наличия взаимосвязи методом корреляционного анализа можно выразить форму этой связи с помощью регрессионного анализа.
Цель регрессионного анализа — с помощью уравнения регрессии предсказать ожидаемое среднее значение результирующей переменной [3].
Построенная регрессионная модель показывает следующие результаты (Таблица 1).
Таблица 1
Сравнение значений модели линейной регрессии
|
Исходные данные |
Предсказанные данные |
|
350500 |
409523.807458 |
|
18000 |
522710.984967 |
|
233600 |
498080.579307 |
|
28400 |
510485.354513 |
|
199900 |
490057.036124 |
Следующим исследуемым методом будет «Метод Опорных Векторов». Метод Опорных Векторов или SVM — это линейный алгоритм, используемый в задачах классификации и регрессии. Данный алгоритм имеет широкое применение на практике и может решать как линейные, так и нелинейные задачи. Суть работы “Машин” Опорных Векторов проста: алгоритм создает линию или гиперплоскость, которая разделяет данные на классы [4].
Построенная модель метода опорных векторов показывает следующие результаты (Таблица 2).
Таблица 2
Сравнение значений модели метода опорных векторов
|
Исходные данные |
Предсказанные данные |
|
350500 |
567539.582491 |
|
18000 |
567531.544301 |
|
233600 |
567531.544320 |
|
28400 |
567531.544339 |
|
199900 |
567531.544358 |
Третьей моделью будет модель, основанная на библиотеке CatBoost. CatBoost — это библиотека градиентного бустинга, созданная Яндексом. Она использует небрежные (oblivious) деревья решений, чтобы вырастить сбалансированное дерево. Одни и те же функции используются для создания левых и правых разделений (split) на каждом уровне дерева. По сравнению с классическими деревьями, небрежные деревья более эффективны при реализации на процессоре и просты в обучении [5].
Построенная модель CatBoost показывает следующие результаты (Таблица 3).
Таблица 3
Сравнение значений модели CatBoost
|
Исходные данные |
Предсказанные данные |
|
350500 |
219906.513913 |
|
18000 |
211564.694508 |
|
233600 |
243652.151435 |
|
28400 |
220958.999594 |
|
199900 |
244945.611943 |
Последним рассматриваемым методом будет «Искусственная нейронная сеть». Искусственная нейронная сеть (ИНС) — математическая модель, а также ее программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма [6].
Для сравнения результата работа алгоритмов между собой будем использовать следующие метрики:
MAE или средняя абсолютная ошибка — метрика, которая сообщает нам среднюю абсолютную разницу между прогнозируемыми значениями и фактическими значениями в наборе данных. Чем ниже MAE, тем лучше модель соответствует набору данных.
MSE или среднеквадратичная ошибка — метрика, которая сообщает нам среднеквадратичную разницу между прогнозируемыми значениями и фактическими значениями в наборе данных. Чем ниже MSE, тем лучше модель соответствует набору данных.
RMSE или среднеквадратическая ошибка — метрика, которая сообщает нам квадратный корень из средней квадратичной разницы между прогнозируемыми значениями и фактическими значениями в наборе данных. Чем ниже RMSE, тем лучше модель соответствует набору данных [7].
Сравним полученные результаты работы алгоритмов между собой. Метрики точности алгоритмов представлены в таблице 4.
Таблица 4
Метрики точности алгоритмов
|
MAE |
MSE |
RMSE | |
|
Linear regression |
287904.290086 |
1.024406e+11 |
320063.437406 |
|
Support Vector Regression |
340966.751477 |
1.381435e+11 |
371676.673995 |
|
CatBoost |
144506.732664 |
3.568416e+10 |
380.140412 |
|
ANN |
157991.103964 |
4.215589e+10 |
205319.002441 |
Исходя из метрики MAE, чем ниже ее значение, тем лучше модель, то самой лучшей моделью является CatBoost, а самой худшей — Support Vector Regression. Такие же результаты показывает и метрика RMSE.
В ходе работы был исследован набор данных ATM Transaction dataset, хранящий в себе данные об остатке денежных средств в банкоматах.
Кроме того, были построены модели машинного обучения, которые предсказывают остаток денежных средств в банкоматах. Проверена работоспособность моделей и проведено их сравнение.
Литература:
- Python [Электронный ресурс] // — Режим доступа: https://ru.wikipedia.org/wiki/Python (дата обращ. 15.06.2023).
- ATM-transaction dataset [Электронный ресурс] // — Режим доступа: https://www.kaggle.com/khyeh0719/atm-transaction-train-test (дата обращ. 15.06.2023).
- Линейный регрессионный анализ [Электронный ресурс] // — Режим доступа: https://www.statmethods.ru/statistics-metody/regressionnyj-analiz/ (дата обращ. 15.06.2023).
- Краткий обзор алгоритма машинного обучения Метод Опорных Векторов (SVM). [Электронный ресурс] // — Режим доступа: https://habr.com/ru/post/428503/ (дата обращ. 15.06.2023).
- Быстрый градиентный бустинг с CatBoost. [Электронный ресурс] // — Режим доступа: https://habr.com/ru/company/otus/blog/527554/ (дата обращ. 15.06.2023).
- Искусственные нейронные сети (ИНС) [Электронный ресурс] // — Режим доступа: https://neurohive.io/ru/osnovy-data-science/ansamblevye-metody-begging-busting-i-steking/ (дата обращ. 15.06.2023).
- MSE против RMSE: какую метрику следует использовать? [Электронный ресурс] // — Режим доступа: https://www.codecamp.ru/blog/mse-vs-rmse/ (дата обращ. 15.06.2023).

