





В акустико-фонетическом подходе к автоматическому распознаванию речи выделение границ фонем — одна из основных и наиболее сложных задач. Существует несколько методом для ее решения. В этой статье будет рассмотрен метод, основанный на измерении скорости изменения спектральных характеристик сигнала, для слов русского языка. Результаты применения будут сравниваться с ручной сегментацией. В качестве спектральных характеристик были использованы мел-частотные кепстральные коэффициенты (MFCC — Mel-Frequency Cepstrum Coefficients).
Вычисление мел-частотных кепстральных коэффициентов включает в себя следующие шаги:
- Необходимо разделить исходный сигнал на кадры. Их размер обычно выбирается от 10 до 40 мс, так как считается, что речевой сигнал на этом промежутке можно принять как квазистационарный. Кадры накладываются друг на друга. Для данной работы выбрана длина кадра — 10 мс, наложение — 5 мс.
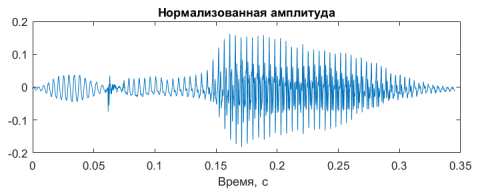
Рис.1 График зависимости амплитуды сигнала от времени для слова «два»
- Речевой сигнал конечен и не является периодическим, поэтому из-за разрывов на его концах при применении преобразования Фурье проявляется эффект утечки. Для того, чтобы снизить его влияние на результат, к каждому кадру применяется оконная функция, в данном случае было использовано окно Хемминга:
![]()
- К каждому кадру применяется преобразование Фурье — получаем спектр сигнала. Затем вычисляется периодограмма — оценку спектральной плотности мощности:
![]()
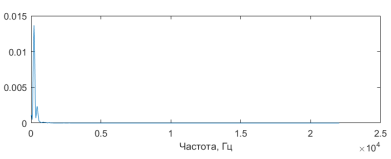
Рис. 2 Периодограмма кадра № 12
- К каждому кадру применяется блок мел-фильтров — треугольных пересекающихся фильтров, расположенных наиболее плотно в области нижних частот. Количество фильтров — 26. Для расчета фильтров выбирается верхняя и нижняя частота. Затем осуществляется переход от частотной шкалы к мел-шкале по формуле:
![]()
Между полученными значениями на мел-шкале выбираются точки, расположенные линейно, для 26 фильтров — 28 точек. После этого переход обратно в частоты по обратной формуле:
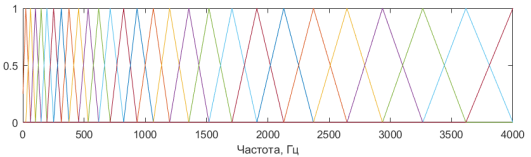
Рис. 3. Мел-фильтры
Фильтры умножаются на периодограмму кадра и вычисляется энергия для каждого фильтра, всего 26 значений для каждого кадра.
- Полученные энергии логарифмируются.
- Применяется дискретное косинусное преобразование.
Полученные 26 значений для каждого кадра — мел-частотные кепстральные коэффициенты. Из них используются первые 13 как наиболее информативные для речевого сигнала. Их можно представить в виде изображения как на рисунке 5.
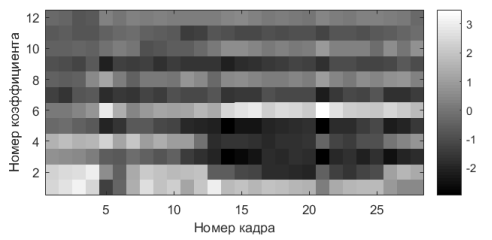
Рис. 4. Мел-частотные кепстральные коэффициенты для слова «два»
В качестве критерия определения границ фонем была выбрана скорость изменения спектральных характеристик, так как данная величина при смене звука часто является локальным максимумом. Рассчитать скорость изменения можно по формуле:
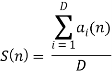 ,
,
где D — количество коэффициентов (в данной работе D=13),
i — номер коэффициента,
n — номер кадра,
![]() — коэффициент регрессии, который рассчитывается по формуле:
— коэффициент регрессии, который рассчитывается по формуле:
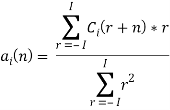 ,
,
где ![]() — вектор коэффициентов, содержащий значения коэффициента под номером i для всех кадров,
— вектор коэффициентов, содержащий значения коэффициента под номером i для всех кадров,
n — номер текущего кадра,
r — номера кадров в области I вокруг текущего кадра, используемых для расчёта коэффициента регрессии.
В данной работе I был принят равный 3.
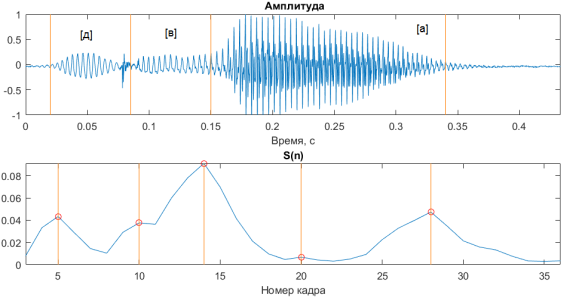
Рис. 5. Результаты нахождения границ для слова «два»
На рисунке 6 на графике амплитуды исходного сигнала вертикальными линиями обозначены расставленные вручную границы звуков. Локальные максимумы функции S(n) — границы звуков, вычисленные методом. Как видно, метод вычисления скорости измерения спектральных характеристик отобразил границы всех присутствующих звуков в слове «два» — [д в а], но для звук [а] он разделил на два. Для слова «семь» также была найдена лишняя граница звука [м’] (рис. 6). Присутствие ложных границ часто встречается в результатах применения такого метода.
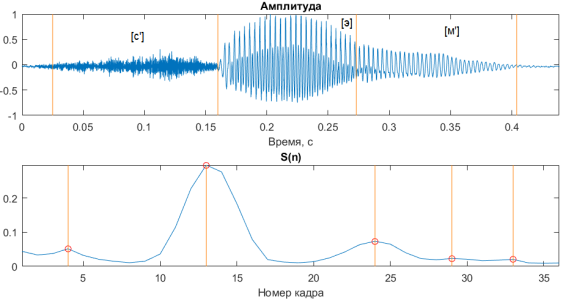
Рис. 6. Результаты нахождения границ для слова «семь»
В качестве слов для выделения звуков использовались три набора слов «ноль», «один», … «девять», для каждого слова было записано три файла одним диктором.
Всего было выделено 168 границ при их общем количестве 147. Из них 11 были пропущены, 29 границы были лишними. Процент правильно выделенных границ составил 91 %, лишних границ — 17 %. Метод имеет высокий процент выявленных границ фонем, но при этом добавляет много лишних. В зависимости от дальнейшего применения полученных результатов наличие лишних границ может не иметь большого значения. Если выделять кадры, соответствующие фонеме и распознавать их, например, с помощью нейронной сети, то на выходе может получиться последовательность фонем [д в а а] или [с’ э м’ м’]. Если соотносить эти последовательности со словарем, то найти искомые слова не будет представлять большой сложности.
Таким образом, рассматриваемый в статье метод показал хорошие результаты и может использоваться для дальнейшего распознавания речи.
Литература:
- L. Rabiner, S. Dusan. On the Relation between Maximum Spectral Transition Positions and Phone Boundaries // INTERSPEECH. — 2006
- L. Rabiner, Biing-Hwang Juang. Fundamentals of Speech Recognition.1993. — 507 с.
- Taabish Gulzar, Anand Singh. Comparative Analysis of LPCC, MFCC and BFCC // International Journal of Computer Applications. — 2014. — № 101(12). — С. 22–27.
- Рабинер Л. Р., Шафер Р. В. Цифровая обработка речевых сигналов. — М.: Радио и связь, 1981. — 496 с.
- Смит С. Цифровая обработка сигналов. Практическое руководство для инженеров и научных работников. — М.: Додэка-XXI, 2012. — 720 с.
