В статье автор рассматривает сортировку файла при помощи битового массива на C++. А также сравнивает затраты оперативной памяти без использования битового массива.
Ключевые слова: алгоритм, сортировка, оперативная память, C++, битовое сжатие
Многие люди знают, как отсортировать массив, но довольно часто к этой задаче добавляются ограничения такие как малый объем памяти. Для эффективного использования памяти часто используются специфические типы данных или специальные алгоритмы. Цель данной статьи — показать один из методов оптимизации памяти при сортировке одномерного массива.
Постановка задачи:
Входные данные: Файл, содержащий не более n (n=
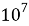
Результат: упорядоченный по возрастанию список чисел.
Ограничения:
- Оперативной памяти — приблизительно 2 Мб
- Дисковая память неограниченна
- Время выполнения программы — 10 секунд
Доказательство эффективности по памяти неформального алгоритма решения задачи:
Для начала рассмотрим алгоритм на небольшом количестве чисел.
Пусть имеется 20 целых чисел и их можно значения в диапазоне от 1 до 20 и их надо представить 20 битами. Последовательность чисел, вставляемая в битовую последовательность из 20 бит, будет такой {1, 2, 5, 9, 12, 8}. Сначала вся последовательность бит заполнена нулями. Биты в последовательности нумеруются с нуля.
Теперь создадим отображение, которое вставляет 1 в бит с номером, равным значению вставляемого числа, тогда получим следующую битовую последовательность: 011001001100100000000
Проведем небольшой сравнительный анализ приведенного примера:
Возьмем int8 как тип данных, в котором хранятся числа до обработки. Int8 имеет объем в 1 байт или 8 бит, чисел использовано 6 => 8*6 = 48 бит использовано в общем. Битовая строка, как описано выше, состоит из 20 бит и имеет такой же объем в оперативной памяти. Чем больше используется чисел и чем меньше строка, тем меньше памяти нам потребуется.
Докажем рентабельность этого алгоритма для поставленной задачи:
Изначальный тип данных для чисел будет int32, int16 слишком мал. Каждое число занимает 4 байта в памяти =>
Рассмотрим строку из
Алгоритм решения:
В качестве файла с данными будет использован файл gen.txt, в качестве выходного файла будет out.txt. Сама сортировка будет происходить уже при выводе информации т. к. будут рассматриваться ненулевые элементы битовой строки от наименьшего индекса к наибольшему. Для дополнительного понимания информации код будет прокомментирован в важных участках
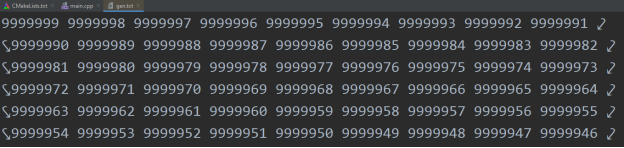
Рис. 1. Часть содержимого файла gen.txt до сортировки
Код программы будет выглядеть так:
#include
#include
#include
#include
using namespace std;
const int N = 10000000;
int main() {
//строка битов
auto * bitset = new std::bitset
//поток ввода-вывода
fstream inout;
inout.open(«gen.txt»);
int k;
for (int i = 0; i < N; i++){
inout >> k;
//назначение индексу равному вводимому в битовой строке значения 1
bitset->set(k); }
inout.close();
inout.open(«out.txt»);
for (int i = 0; i < N; i++){
//вывод индекса в файл, если значение бита равно 1
if (bitset->test(i) == 1)
inout << i << " ";
}
inout.close();
}
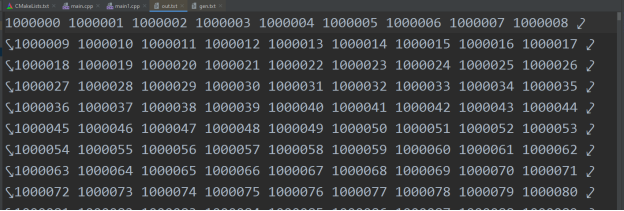
Рис. 2. Часть содержимого файла out.txt после сортировки
Вывод:
Исследовав метод хранения информации битовым сжатием и проведя сравнительный анализ с обычным методом хранения информации, была доказана большая эффективность использования памяти во время сортировки массива, несмотря на простоту реализации.
Литература:
- bitset: класс-контейнер для хранения битов. — Текст: электронный // cppstudio: [сайт]. — URL: http://cppstudio.com/post/5765/ (дата обращения: 08.01.2021).
- Битовые маски. Динамическое программирование по маскам. — Текст: электронный // brestprog: [сайт]. — URL: https://brestprog.by/topics/bitmasks/ (дата обращения: 08.01.2021).
- Примеры использования битового сжатия. — Текст: электронный // acm.math.spbu: [сайт]. — URL: http://acm.math.spbu.ru/~sk1/mm/lections/2014–08–20-bits.pdf (дата обращения: 08.01.2021).

