В данной работе предлагается метод для извлечения SAO структур из текстовых данных на основе семантических правил. Предложен алгоритм, который адаптирован для русского языка.
Ключевые слова: SAO-структура, сжатие термов, семантический анализ, семантические деревья.
1. Введение
SAO (субъект, объект, действие) структура — это семантическая структура, которая может быть извлечена из текстовых данных. Объекты и субъекты — это слова или фразы, которые связаны с тематикой текста. Действия — это глаголы, связывающие субъекты и объекты. В данной статье предлагается подход к извлечению SAO структур из текстовых данных, основанный на семантических правилах. Предложен алгоритм для русского языка.
2. Методика идентификации SАО структур
Методика идентификации SАО структур состоит из следующих шагов:
− извлечение основных компонентов SАО на основе алгоритма смежности слов и сжатия термов;
− извлечение SАО на основе древовидной структуры;
− модель взвешивания SАО для ранжирования САО структур.
2.1 Извлечение основных компонентов SАО
Процесс извлечения компонент SАО включает три шага:
− Сжатие термов;
− Ранжирование результатов шага 1, в основе лежит алгоритм смежности слов;
− Комбинирование основных результатов с ключевыми словами.
Сжатие термов
Сжатие термов представляет собой алгоритм для группировки и очистки большого количества слов в документах. Этот алгоритм описан в статье [2]. Ниже приведены основные шаги:
− Удаление тегов, общих слов и т. д., не имеющие ценности.
− Удаление однокоренных слов, названий и т. д.
− Комбинирование связанных слов в отдельные фразы.
− Удаление редких слов.
− Использование метода главных компонент для сжатия текста.
Ранжирование результатов шага сжатия термов на основе алгоритма смежности слов
Данный алгоритм подсчитывает частоту встречаемости слова вместе с ключевыми словами документа и считает его важность. Например, если слово или фраза редко встречаются в документе, но встречается часто с ключевым словом, то мера важности этого слова повышается.
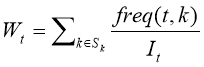 ,
,
t — терм, полученный при шаге сжатия термов, ![]() ;
;
![]() — вес терма t, определяющий его меру важности;
— вес терма t, определяющий его меру важности;
![]() — общее количество экземпляра терма t в наборе;
— общее количество экземпляра терма t в наборе;
![]() — набор ключевых слов;
— набор ключевых слов;
![]() — частота появления терма t и ключевого слова k.
— частота появления терма t и ключевого слова k.
Комбинирование основных результатов группировки и ранжирования термов с ключевыми словами.
Комбинирования результатов:
Sc = Sk + {t | t — первые x из St, проранжированных по мере Wt}.
St — набор термов из результатов группировки.
Sc — набор ключевых компонентов SАО.
В конце происходит проверка результатов и удаление ненужных термов и фраз вручную.
2.2 Извлечение SАО на основе древовидной структуры
Модель извлечения SАО структур, предложенная в [1] является иерархической и основана на определенных синтаксических правилах.
Согласно алгоритму, сначала выбираются объекты в предложении согласно синтаксическим деревьям. Действия комбинируются с объектами в фразу объект-действие. После этого выделяются субъекты, которые комбинируются с полученными результатами в структуру SAO. Из полученных SАО с помощью словаря соответствия удаляются общие и ненужные.
2.3 Модель взвешивания SАО для ранжирования SАО структур
Модель взвешивания необходима для отбора важных структур SAO и их ранжирования [2].
Вес САО структуры рассчитывается по формуле:
![]()
![]() — вес САО;
— вес САО;
![]() — вес субъекта;
— вес субъекта;
![]() — вес объекта;
— вес объекта;
![]() — вес действия;
— вес действия;
![]() — начальный вес САО.
— начальный вес САО.
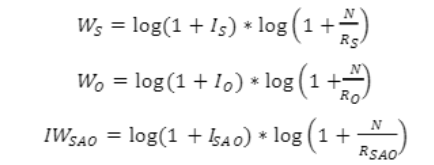
Is — кол-во появлений субъекта;
Rs — кол-во документов, содержащий субъект.
Iо — кол-во появлений объекта;
Rsо — кол-во документов, содержащий объект.
Isao — кол-во SАО в документах.
Rsao — кол-во документов, содержащих SАО. N — общее кол-во документов.
Подсчет Ws, Wo, IWsao базируется на TFIDF.
Для идентификации веса Действия привлекаются эксперты. Wa определяется на основе статистики.
Заключение
В данной работе представлен подход к извлечению SAO структур из текстовых документов. Предоставлен пример для извлечения SAO структуры из русскоязычного текстового документа из поля описания патентного документа. Также был предложен подход к «очистке» текста для фильтрации от малозначащих слов, словосочетаний и комбинирования фраз.
Литература:
- SAO Semantic Information Identification for Text Mining (PDF Download Available). Available from: https://www.researchgate.net/publication/312619671_SAO_Semantic_Information_Identification_for_Text_Mining [accessed May 14, 2017].
- Y. Zhang, A. L. Porter, Z. Hu, Y. Guo, N. C. Newman, “Term clumping” for technical intelligence: a case study on dye-sensitized solar cells, Technological Forecasting and Social Change. 85 (2014) 26–39.
- Y. Kim, Y. Tian, Y. Jeong, R. Jihee, S.-H. Myaeng, Automatic discovery of technology trends from patent text. 2009 ACM Symposium on Applied Computing. (ACM, Honolulu, Hawaii, 2009), 1480–1487.
- A multy-stage algorithm for text documents filtering based on physical knowledge / Korobkin D. M., Fomenkov S. A., Kolesnikov S. G., Orlova Y. A. // World Applied Sciences Journal. — 2013. — V. 24. № 24. P. 91–97.

