В данной работе представлена свёрточная нейронная сеть, которая может найти лицо человека и классифицировать эмоцию на лице в реальном времени на Raspbery Pi 3. Цель работы получить как можно хороший результат имея ограничение в виде слабого процессора.
Ключевые слова: нейронная сеть, классификация.
Задача классификации уже решена многими исследователями, но по-прежнему актуальна из-за большого разнообразия классов, к которым может относиться тот или иной объект на картинке либо на видео или даже несколько объектов. В этой работе сначала нам нужно найти лицо человека на изображении, потом только классифицировать эмоцию на лице. При разных ракурсах работают разные алгоритмы для обнаружения лица, мы рассмотрим только фронтальный случай, т. к. объективно нельзя ничего сказать про эмоцию человека в других случаях. Для нахождения лица будем пользоваться алгоритмом Виолы-Джонса, который лучший по соотношению времени нахождения и точности.
Для решения данной задачи был использован набор данных под названием Facial Expression Recognition 2013 (FER-2013) созданной Пьером Люком Кэрриером (Pierre Luc Carrier) и Аароном Курвиллем (Aaron Courville). Этот набор данных содержит 35887 изображений, разбитых на 7 классов: {“angry”, “disgust”, “fear”, “happy”, “sad”, “surprise”, “neutral”}, на которые мы и будем классифицировать эмоции на лице.
Ян Гудфеллоу (Ian Goodfellow) провел эксперимент [3] и попросил сотрудникам его компании классифицировать изображения из этого набора данных, в итоге человеческая точность на FER-2013 составила 65 ± 5 %. Нашей целью является классификация в реальном времени, поэтому архитектура нашей сети должна быть как можно маленькой. В данной работе будет представлена сеть, которая классифицирует с точностью 64 % в реальном времени работая только на Raspbery Pi 3.
Обнаружение лиц на картинке: Мы будем использовать методику, разработанную уже кажется в далеком 2001 году учеными Paul Viola и Michael Jones в своей статье [1]. Эта методика стоит на стыке таких областей, как Machine Learning и Computer Vision. Получилось так, что изначально методика разрабатывалась и применялась в области разработки алгоритмов для обнаружения лиц, но ничего не мешает обучить алгоритм на поиск других предметов: машина, запрещённые объекты на рентгене в аэропорту, опухоль на медицинских снимках.
Виола-Джонс является одним из лучших по соотношению показателей эффективность распознавания/скорость работы. Также этот детектор обладает крайне низкой вероятностью ложного обнаружения лица. Алгоритм даже хорошо работает и распознает черты лица под небольшим углом, примерно до 30 градусов. При угле наклона больше 30 градусов процент обнаружений резко падает. Данный метод в общем виде ищет лица и черты лица по общему принципу сканирующего окна. В результате своей работы, алгоритм должен определить лица и пометить их. Поиск осуществляется прямоугольными признаками (о каких признаках идет речь рассмотрим чуть позже), с помощью которых и описывается найденное лицо.
Признаки, которые мы используем называются признаками Хаара. Каждый признак представляет собой одно значение, полученное путем вычитания суммы пикселей под белым прямоугольником из суммы пикселей под черным прямоугольником. Теперь, все возможные размеры и местоположения каждого ядра используются для расчета множества признаков. Но при таком подходе даже при размере окна поиска 24x24 на изображении размера 384x288 в результате получим более 180000+ признаков.
Так как же выбрать лучшие признаки из 180000+? Это достигается с помощью алгоритма машинного обучения Adaboost (сокращение от Adaptive Boosting), предложенная Йоавом Фройндом (Freund) и Робертом Шапиром (Schapire) в 1999 году [2]. Смысл алгоритма заключается в том, что если у нас есть набор объектов, например, изображение и класс, к которому оно принадлежит (-1 — нет лица, +1 — есть лицо), кроме того, имеется множество простых классификаторов, то мы можем составить один более совершенный и мощный классификатор. При этом в процессе составления или обучения финального классификатора акцент делается на изображения, которые распознаются «хуже», в этом и заключается адаптивность алгоритма, в процессе обучения он подстраивается под наиболее «сложные» объекты.
Финальный классификатор представляет собой взвешенную сумму этих слабых классификаторов. Эти классификаторы называются слабыми, потому что они само по себе не могут классифицировать изображение, но вместе с другими образуют сильный классификатор.
После обучения, в окончательном варианте классификатор имеет около 6000 признаков. Так мы сократили количество признаков от 180000+ до 6000.
Итак, теперь мы берем изображение, берем каждое окно 24х24 в нем (а потом и другие масштабы). Применяем к ним 6000 признаков. Проверяем лицо это или нет. Но как бы хорош не был переход всего к 6000 признакам, это все равно неэффективно и требует много времени. Для решения этой проблемы рассмотрим следующее свойство.
Введем понятие каскада классификаторов. Вместо применения всех 6000 признаков к окну, признаки группируются по разным стадиям классификаторов и применяются один за другим (обычно первые несколько этапов содержат намного меньше признаков). Если окно не проходит первый этап, сразу отказываемся от него и не рассматриваем остальные признаки на нем. Если оно прошло, применяем второй этап признаков и продолжаем процесс. Окно, которое проходит все стадии, является областью, где есть лицо.
В конце детектор имеет 6000+ признаков с 38 этапами с 1, 10, 25, 25 и 50 признаками на первых пяти этапах. Согласно результатам тестовых выборок, в среднем 10 признаков из 6000+ оцениваются в каждом подокне.
В библиотеке OpenCV имеется этот детектор в виде xml файла, его мы и будем использовать.
Архитектура сети: Части сети выбраны таким образом, чтобы можно было иметь как можно меньше параметров для обучения (и собственно потом для расчетов), но при этом терять как можно меньше в эффективности. Для этого использовались все на данный момент известные способы для уменьшения параметров сети. Рассмотрим главные отличительные черта архитектуры.
Depth-wise separable convolution:
чтобы сократить количество параметров и вычислений, используется разделяемая по глубине свертка (depth-wise separable convolution). Эта идея была предложена инженерами Google в их статье [4]. Основное назначение этих слоев — отделить пространственные взаимные корреляции от канальных взаимных корреляций (т. е. отделить матрицы от глубины карты признаков). Разделяемая по глубине свертка состоит из двух разных слоев: глубинная и точечная свертка. Это делается, сначала применяя фильтр

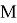
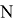
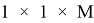
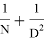
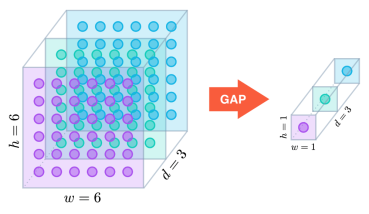
Global Average Pooling: как уже было сказано выше, использование свёрточных нейронных сетей уменьшает количество параметров в разы, но в таких сетях последние слои все равно полносвязные, чтобы можно было классифицировать объект с высокой точностью из уже полученных карт признаков. Во многих свёрточных нейронных сетях больше 90 % параметров сосредоточены именно в этих последних полносвязных слоях. Новинки архитектур уменьшили количество параметров в их последних слоях, включив операцию Global Average Pooling [6]. Эта операция сводит каждую карту признаков к скалярному значению, считывая среднее значение по всем элементам в карте признаков. Global Average Pooling вынуждает сеть извлекать глобальные особенности из входного изображения. Для использования этого метода необходимо, чтобы в последнем свёрточном слое было то же количество карт признаков, сколько и классов.
Residual Learning: Простая логика есть в том, что всегда можно получить более глубокую модель, которая не хуже менее глубокой, тупо добавив несколько identity layers, то есть уровней, которые просто пропускают сигнал дальше без изменений. Вот это наблюдение, что всегда можно сделать не хуже identity, и есть основная мысль слоев, использующих Residual Learning. Задача формулируется так, чтобы более глубокие уровни предсказывали разницу между тем, что выдают предыдущие слои и тот слой, который сейчас рассматривается, то есть, чтобы мы всегда могли увести веса в 0 и просто пропустить сигнал. Отсюда название — Deep Residual Learning, то есть обучаемся предсказывать отклонения от прошлых лееров. Более конкретно это выглядит следующим образом:
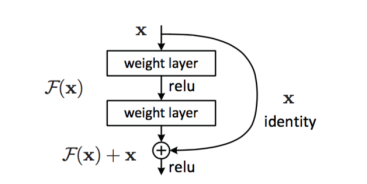
Два слоя (в основном convolution) с весами и shortcut connection, который просто identity. Результат после двух слоев добавляется к этому identity. Поэтому если в весах некого уровня будет везде 0, он просто пропустит дальше чистый сигнал. Это нововведение помогло ученым из Microsoft подняться в top5 ImageNet с ошибкой всего 3.57 % [7].
Обучение проводилось с использованием оптимизатора ADAM [8], который показывает хорошую эффективность и работает быстрее остальных оптимизаторов. С таким выбором не пришлось долго ждать результатов обучения. Стоит отметить, что машина также была хорошая, видеокарта Nvidia GeForce RTX 2080 Ti.
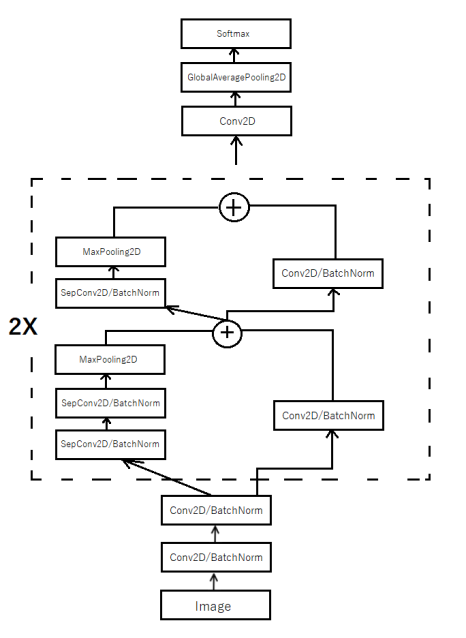
С такой скоростью обучение было время поэкспериментировать и к концу работы выбрать наилучшую из пробованных архитектур. В конечном итоге архитектура сети выглядит следующим образом:
Литература:
- Paul Viola, Michael Jones. Rapid Object Detection using a Boosted Cascade of Simple Features, 2001
- Yoav Freund, Robert E. Schapire, «A Short Introduction to Boosting», Shannon Laboratory, USA, 1999
- Ian Goodfellow et al. Challenges in Representation Learning: A report on three machine learning contests, 2013
- Franc¸ois Chollet. Xception: Deep learning with depthwise separable convolutions. CoRR, abs/1610.02357, 2016.
- Andrew G. Howard et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRR, abs/1704.04861, 2017
- Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, and Martin Riedmiller. Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806, 2014.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. arXiv preprint arXiv:1512.03385, 2015.
- Diederik P. Kingma, Jimmy Ba. Adam: A method for Stochastic Optimization. arXiv preprint arXiv:1412.6980, 2014.

