В данной работе рассматривается архитектуры сети с обходными путями. При этом ключевые моменты исследуются отдельно. И в итоге на основании полученных знаний делается вывод об эффективности использования данного алгоритма.
Ключевые слова: сверточные нейронные сети, CNN, ReLu-функции, свертка, архитектура с обходными путями.
В последние несколько лет в области распознавания изображений достигнуты существенные успехи. Большая часть из них связана с применением глубоких (многослойных) свёрточных нейронных сетей (CNN), начиная с 2012 года, когда первая широко известная сеть подобной архитектуры AlexNet [1] выиграла ImageNet Large Scale Visual Recognition Challenge c 10-процентным отрывом в точности по сравнению с существовавшими до этого решений. Ключевыми причинами подобного отрыва являлись:
- Использование ReLu-функции активации нейронов, используя уравнение при (1)
![]() (1)
(1)
Это дало большой прирост в скорости по сравнению с распространёнными до этого и вычислительно более сложными логистической функцией и гиперболическим тангенсом.
- Использование операции свёртки для уменьшения количества весов. С увеличением числа слоёв в нейросети количество весов, требующих вычисления производной по каждому из них на каждой итерации обучения, стало бы огромным даже по меркам сегодняшних компьютеров. Решением стало использование набора фильтров (ядер свёртки), повторно применяющихся к каждой части изображения. Операция свертки записывается в виде <здесь формула из твоего документа>, при условии, что входное изображение двумерное, где I — входные данные, K — соответственно двумерное ядро. У обычных нейронных сетей на выходе каждое выходное значение — это результат всех входных значений. CNN имеют разреженную связь. Такое свойство экономит память на реализацию.
- Отсутствие ручного выбора особенностей изображения. Конкуренты AlexNet использовали неглубокие нейросети или другие методы машинного обучения на конечном этапе. На вход они получали характеристики изображения, созданные с помощью таких алгоритмов, как SIFT, SURF и т. д. Машинное обучение нижних слоёв свёрточных сетей показало своё превосходство по сравнению с этими и любыми другими методами, созданными людьми.
Дальнейшее развитие свёрточных нейронных сетей пошло в сторону увеличения числа слоёв. Возник вопрос: достаточно ли просто увеличить число слоёв для увеличения точности предсказания? В задачах машинного обучения оценка точности производится на двух наборах данных: тренировочном — том, на котором модель обучается, и тестовом — том, который модель ни разу не видела. Зачастую модель показывает почти идеальный результат на тренировочном наборе, но очень плохо работает на тестовом — это признак переобучения: модель выучила тестовый набор, но не умеет обобщать на неизвестные данные. Ожидалось, что именно так себя поведут очень глубокие нейросети. Однако относительно недавно в работе [2] было показано, что подобное наращивание мощности «в лоб» начинает приводить к ухудшению точности даже на тренировочном наборе. Причина заключается в том, что даже если модель идеально описывает данные, при добавлении нового слоя она испытывает проблемы с обучением функции идентичности. То есть при достаточно глубокой архитектуре оказывается сложным обучить слой, для которого выход строго (или даже приближенно) равен входу. Авторы [2] предлагают решать эту проблему добавлением short-cut-ов — обходных путей, проиллюстрированных на рисунке 1.
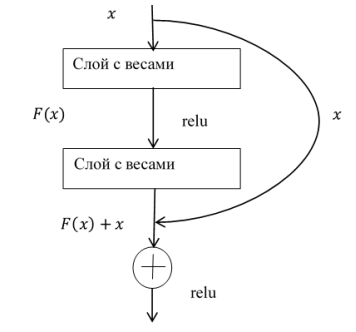
Рис. 1. Схема архитектура с обходными путями
Если на рис. 1 — Отображение, лежащее в основе, обозначить, как ![]() , то получается другое отображение
, то получается другое отображение ![]() . Тогда оригинал изображения записывается в виде:
. Тогда оригинал изображения записывается в виде: ![]() . Считается, что легче оптимизировать остаточное отображение, чем оригинальное. Такое отображение может быть реализовано с помощью прямых нейронных сетей с добавлением “shortcut connections”. Их суть заключается в выполнении отображения идентичности, а также в добавлении полученных выходов к выходу слоя [3].
. Считается, что легче оптимизировать остаточное отображение, чем оригинальное. Такое отображение может быть реализовано с помощью прямых нейронных сетей с добавлением “shortcut connections”. Их суть заключается в выполнении отображения идентичности, а также в добавлении полученных выходов к выходу слоя [3].
Комбинация таких блоков из двух слоёв, где выход и вход блока соединены обходным путём, позволила модели легко выучивать функцию идентичности — для этого достаточно приравнять все веса внутри блока к 0. При такой архитектуре результат на тренировочном наборе не может стать хуже при увеличении числа слоёв, а значит, может стать только лучше.
Литература:
- Alex Krizhevsky Ilya Sutskever, Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks // Digital Library. — 2017. — № 10.1145/3065386. — С. 84–90.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition // Cornell University. — 2015. — № 1512.03385. — С. 1–12.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition [Электронный ресурс] // Cornell University Library. URL: https://www.arxiv.org/abs/1512.03385v1(20.11.2019)].

