




Towards a corpus methodology in translation studies

Автор: Шичкина Мария Геннадьевна
Рубрика: 7. Вопросы переводоведения
Опубликовано в
IV международная научная конференция «Актуальные вопросы филологических наук» (Казань, октябрь 2016)
Дата публикации: 20.08.2016
Статья просмотрена: 104 раза
Библиографическое описание:
Шичкина, М. Г. Towards a corpus methodology in translation studies / М. Г. Шичкина. — Текст : непосредственный // Актуальные вопросы филологических наук : материалы IV Междунар. науч. конф. (г. Казань, октябрь 2016 г.). — Казань : Бук, 2016. — С. 73-77. — URL: https://moluch.ru/conf/phil/archive/232/10959/ (дата обращения: 27.04.2024).
Использование корпусной методологии при переводе и в процессе обучения переводу имеет существенную специфику, которая связана с лингвистическими различиями между языковыми системами и сравнительно недавним началом исследований в этой области.
Ключевые слова: корпус, корпусная методология, переводоведение.
From the time Translation Studies stopped being viewed as a rather idiosyncratic area of science and became acknowledged as something worth studying and dissecting, we have been trying to devise ways of finding out which techniques we could implement for optimizing the translation process. Now, a major shift in priorities has occurred and translation methodology features high on the research agenda. This trend has been greatly facilitated by the computer revolution, and involving thinking machines in translation studies was originally a purely applied enterprise, aiming to produce more efficient methods and tools. Advances in the understanding of translation methodology mechanisms led to a questioning of the very basis of Translation Studies (TS), and under the impetus of Mona Baker (1993; 243) it made analysts search for another approach that would be more appropriate to the call of the new computerization era. Therefore, the corpora-based discipline started developing rapidly, and we have certainly come a long way since the appearance of the very first works based on this issue (Gellerstam, 1986; Lindquist, 1989), which evaluated the quality of translational versus original text. Since the 90s, it has become fully integrated in TS, and what is even more important, “it has grown so rapidly and has influenced so significantly the way we conceptualize that we can no longer restrict its importance to the sphere of methodological research, nor can we limit the impact of this new area…to the linguistic approaches to translation because of its links with corpus linguistics” (Sara Laviosa, 121).
As we intend to discuss the corpus methodology, it would be best to give the definitions for these terms. There is no unanimous agreement on the necessary and sufficient conditions for a collection of texts to be a corpus. The EAGLES defined the term as “a collection of pieces of language that are selected and ordered according to explicit linguistic criteria in order to be used as a sample of the language” (EAGLES, 1996). As for corpus characteristics, we know that it is always raw, and it can be either tagged or annotated, which includes automatic tagging, human annotation and a hybrid approach: an automated system refers cases it is unsure of to human annotation. Meanwhile, corpus linguistics is the study of language as expressed in samples (corpora) of “real world” text, and now corpora are largely derived by an automated process. Some scholars consider it to be a research paradigm in its own right (Tognini-Bonnelli, 2001; Laviosa, 2002), on the basis that doing research using corpora generally entails some basic assumptions as to what is the object of enquiry and how it should be studied. Its usage in translation studies research was first proposed as particularly adapted to the purposes of empirical descriptive translation studies (Baker, 1993). Some of the principles underlying corpus linguistics are shared by descriptive translation studies, and this has been, as Laviosa (2004) points out, key to the success story of corpora in Translation Studies.
What is a corpus methodology? It is a methodology that uses corpus evidence mainly as a repository of examples to test, expound or exemplify given theoretical statements. But even before they gave the names to the subjects, they had already been using these. From 1876 to 1926 there were studies of the language of children with a lot of examples, and in 1897 there was the study of the frequency distribution of letters and letter sequences in German (stenography). In 1940 researchers started expanding comparative linguistics, the comparison of word sense in different languages, and in 1956 there appeared a grammar textbook by Georges Gougenheim and Sauvageot describing a grammar based on choices and frequency calculated from 275 French speakers. From the 50s to the 80s there was less work done, particularly because of Chomsky’s criticism, which can be described with three sentences:
1) Using a corpus, what is being analysed? A property of the grammar or a “social” phenomenon?
2) Theoretical linguists study competence, and corpora reflect performance. Hence, competence is not in corpus.
3) Competence is introspection.
Some exceptions are: a) the study of language learning by children (because it requires meta-knowledge on the language); b) languages that are not spoken anymore; c) phonetics; d) historical linguistics.
However, this methodology has intrinsic advantages because there are obvious cases when introspection fails, and they are related to phonology, acquisition, language variations (regional expressions, sociolects, register…). Also, data can be observed and checked with it, and we should take into account usefulness of the frequency measure (unavailable from introspection). It has been said that the “corpus is a more powerful methodology from the point of view of the scientific method” [Leech, 1992].
An accessible introduction to the topic is offered by Douglas Biber, Susan Conrad and Randi Reppen (1998) in their book “Corpus Linguistics: Investigating Language Structure and Use”. It focuses on analyzing the use of various features, and the characteristics of varieties, with discussion of research and methodological questions and examples on the subject. Although, what interests us is the perspectives on the issue in TS, and we find it best to mention the three focal points in corpus-based translation research brought up by Maria Tymoczko (1998: 657): (i) the interest in integrating linguistic and cultural-studies approaches to translation; (ii) investigation of how ideology affects translation; and (iii) methodological issues of applying and adapting technology to the needs of translation studies. The third point stresses methodological issues, and the first two points are clearly related to the contextualization and a tracing of the link between text and context. Tymoczko (1998: 658) also cautions against overemphasis on the ‘scientific’ nature of this research, and on quantification, particularly on its use to ‘prove the obvious’. She is, however, generally positive about the benefits of developing TS using corpora. And if we transfer to TS the aims, aspirations and applications of corpus linguistics, we can outline the major point for doing research in TS using corpus methodology, which is its application to different types of translation, that is to say, in various sociocultural settings, etc.
Thus, using a corpus is the same as using a tool: figures can be easily bent or ignored depending on our initial ideas and interpretations, therefore, our theoretical framework must be tight and our qualitative input must also be valuable.
Stubbs said: ‘Quantitative work with large corpora automatically excludes single and idiosyncratic instances, in favor of what is central and typical” (1983: 233).
For example, A1 — B1 — C1... Here the letters correspond to certain source texts, whereas the numbers correspond to their translations done by students working on the texts. According to Rafal Uzar (2012: 241), there may be as many numbers as there are people involved in translating: B1 — … — B12 — … — B60.
A1 — … — A60,
B1 — … — B60,
C1 — … — C60,
which means there are sixty translators producing completely divergent renditions of the same text, which definitely proves Stubbs’ point in the above quotation. At the same time several corpus methods can be employed to analyze a translation product.
We did our own research in this field and asked several respondents to translate the very same piece of text and our results turned out to be as follows:
A…: Children showing growth failure were assisted individually with a view to identifying underlying causes and providing appropriate case management.
A1: Детям, страдающим замедленным ростом, оказывалась помощь на индивидуальной основе в целях выявления исходных причин и обеспечения надлежащего ухода.
A2: Дети, страдающие проблемами с ростом, получали помощь на индивидуальной основе в целях обнаружения исходных причин и обеспечения соответствующего ухода.
A3: Детям, демонстрирующим рост неудач, помогали индивидуально с целью выявить исходные причины и обеспечить правильное управление.
Some of these translations are obviously not correct, but a simple skim through a few sentences can give us a list of possible lexical or even phrasal equivalents, and this kind of analysis can lead to:
a) An easier and more effective method of obtaining a more accurate qualitative assessment of the product;
b) A better understanding of the process of translation.
As we are speaking of the best way to render the original text, we undoubtedly should mention the third code tightly related to the term ‘corpus’. William Frawley (1984:168) maintains that the confrontation between source language and target language during the translation process results in creating a “third code”. In other words, the code (or language) that evolves during translation and in which the target text is expressed is unique. It is a kind of compromise between the norms or patterns of the source language and those of the target language. Concrete examples abound of, for example, borrowings which cause “foreign” lexical patterning in translated texts, i.e. patterning that would not normally occur in the source language nor in the target language. The notion of the third code provides a useful starting point for explaining some of the concerns of translation scholars who are attempting to apply the techniques of corpus linguistics to investigating the language of translation. Baker (1998) points out that this unique language is not so-called “translationese”, a pejorative term that is used when an unusual distribution of features is clearly the result of the translator’s inexperience or lack of competence in the target language; on the contrary, translation results in the creation of a third code because it is a unique form of communication, not because it is a faulty, deviant or sub-standard form of communication (Baker 1993:248).
For a better understanding of how the corpus methodology works, it is essential to use proportions because simple frequency counts are a useful approach to quantifying linguistic data. For example, we need to know how often a given word is used in the language for choosing its best analogue in translation. We may find that, in the corpus of spoken English, the word ‘boot’ occurs 500 times, so at first glance it seems more frequent in written than in spoken English. However, if we look at these data in a different way and do the following calculations (checking the typical occurrence frequency as a percentage of the total number of tokens in the corpus), we will see that
1) spoken English: 50 / 50,000 x 100 = 0.1 %
2) written English: 500 / 500,000 x 100 = 0.1 %
Comparing these figures, we see that, far from being ten times more frequent in written English than in spoken English, this token has the same frequency of occurrence in both varieties: it makes up 0.1 per cent of the total number of tokens in each sample. It should be noted, therefore, that if the sample sizes on which a count is based are different, then simple arithmetical counts cannot be compared directly, it is necessary in those cases to normalize the data using some indicator of proportion. What we should always take into account is that some word and its foreign analogue may always change, and this is caused by the fact that each language has its own distinct, unique path of development, so the emergence of the third code is not an inconsistent whim, but an expedient way of long-term problem solving.
Translating is one way of helping to control mother-tongue interference by being more aware of its nature; and not only that, but also to become more aware of our own language and understand that it is not more natural or more logical than any other one– simply a different system. Doing exercises can also display differences in structural patterns and pragmatic strategies between languages as well as the close relationship between system and culture (Zabalbeascoa, 1997: 122).
Using the methodology in which various styles are places under scrutiny provides insight into this close link that the above-mentioned author describes. We have done other research to see how the respondents cope with a range of complications (namely, changes in register) in the translation process as shown below:
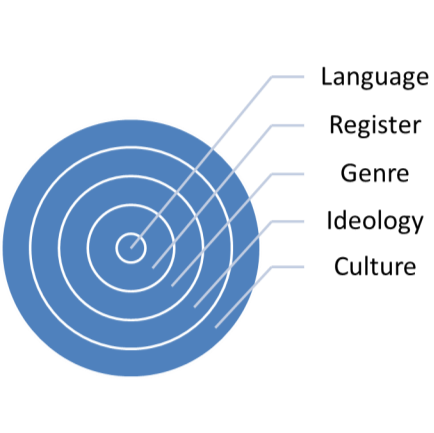
Picture 1. The results of the investigation
The style of each text was different, but all these sections appeared problematic to the respondents because they couldn’t properly classify the presented texts; it would have been very useful for them to start collecting corpora of translated texts with a view to uncovering the distinctive patterns of translation: this way they would find it easier to learn how to differentiate these. We should draw a conclusion that for avoiding mistakes in the translation process our task is:
a) Compare the source text against a batch of translations using collocations,
i. Compare how one word is translated across the whole group,
ii. Compare how phrases are translated across the whole group,
a) Compare source and batch translation wordlists,
b) Compare source and batch translation wordlists with reference corpora wordlists,
c) Compare wordlists of individual translations,
d) Compare statistics across genres
As linguists we need to observe and understand both the product and the process. This can only be undertaken through the analysis of what is tangible, in other words, the product. Our goal is to improve the quality of translation, and this can be analysed quantitatively using the corpus. The diagram shows two concurrent phenomena:
a) What is assessed
b) How it is analysed.
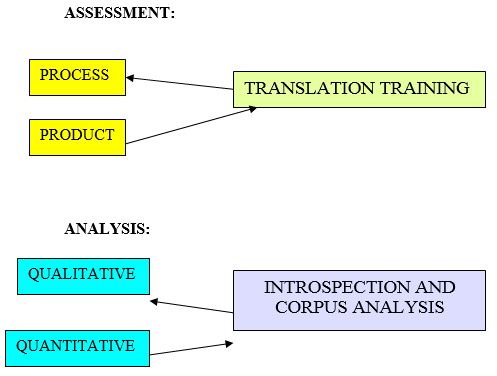
Picture 2. Assessment and analysis of translation
A range of simple corpus methods have been put to use, which not only aid the translator trainee in producing a translation but also help the trainer assess the techniques. This work is supported by the addition of error tags to the corpus allowing us to pinpoint problematic hotspots in the translations. The corpus will eventually be fully annotated with error tags and positive tags, which will also highlight interesting translations of certain source phrases or sentences. The translations have already been aligned with the source texts to make life easier for the translator trainer. With these steps completed we hope to move on and produce a language-independent concordance tool for the translator, which would allow us to view the concordance lists of source texts, comparable texts and translations together on one screen. It is often difficult to ascertain what exactly makes a particular translation good. This approach allows the translator or the translator trainer (or even the translation student) to quickly verify his or her intuitions through corpus evidence. We can then use these learner statistics to predict what might happen when students work with other texts and in other languages. It is our hope that work in translation corpora will be produced in other languages so that translators might have a better idea of the universal problems faced in translation much the same way that learner corpora across the world are giving us ideas about the universal problems of learners of foreign languages.
References:
- Baker, Mona (1993): «Corpus Linguistics and Translation Studies: Implications and Applications», Baker, Philadelphia, 356 p.
- Biber, D., Conrad, S., Reppen, R., Byrd, P. and Helt, M. (2002), Speaking and Writing in the University: A Multidimensional Comparison. TESOL Quarterly, 36: 9–48.
- Gellerstam, M. (1986). Translationese in Swedish novels translated from English. In W L. & LINDQUIST, H. (eds.) Translation studies in Scandinavia, 243 p.
- Gougenheim Georges and A, Sauvageot Prononciation du frangais (1956)Reflections on language. N Chomsky — 1976 — Temple Smith London
- Laviosa, Sara (2002). Corpus-based Translation Studies. Approaches to Translation Studies, Rodopi B. V., Amsterdam — New York; 121 p.
- Leach, G., Eagles -- Recommendations for the Syntactic Annotation of Corpora (1996).
- Tognini-Bonelli, E. Text and Technology. 137–156, Amsterdam: John Benjamins. 8.Tymoczko, M. (1998). “Computerized corpora and the future of translation studies.” Meta 43(4), 652–659.
- Tymoczko, M. (2002). “Connecting the two infinite orders: Research methods in translation studies.” T. Hermans (ed.) (2002). Crosscultural Transgressions. Research models in translation Studies II: Historical and ideological issues. Manchester: St. Jerome, 9–25.
- Uzar Rafal (2012). On the corpus methodology analysis, University of Lodz, 241 pages.
- Zabalbeascoa, P. (1997). Dubbing and the nonverbal dimension of translation. In. F. Poyatos (Ed.) Nonverbal communication and translation (pp. 327–342). Amsterdam: John Benjamins B. V.
Похожие статьи
Современные методы и технологии преподавания иностранных...
Конструктивистский метод. Учебная цель: в основе метода находится собственно активное обучение студентов.
Под понятием альтернативные методы группируется целый ряд различных подходов, приемов, способов передачи языка.
Из опыта индивидуализации обучения иностранным языкам
На основе проведенного нами анализа соответствующей литературы, а также опыта работы считаем, что принцип индивидуального подхода (индивидуализации обучения)...
Методологии проектирования мультиагентных систем
В основе мультиагентного подхода лежит понятие программного агента, который реализован и функционирует как самостоятельная элемент программного обеспечения или элемент искусственного интеллекта.
Методология создания МАС на основе онтологии.
Теоретические основы метода Case study в обучении...
Ввиду динамичного протекания глобализационных процессов отчетливо прослеживается интенсификация международного, межкультурного взаимодействия в профессиональной сфере. Обширное поле возможностей для участия в международном сотрудничестве в свою очередь...
Использование языка-посредника в обучении русскому языку...
и в целях контроля. Положив в основу этот теоретическим образом полученный перечень ситуаций, мы решили наложить его на учебный процесс и выявить реальные ситуации использования английского...
Использование методики CLIL на уроках со вторым языком...
Согласно Интегрированной образовательной программе, разработанной на основе модели трехъязычного обучения, язык изучается не ради самого языка, а ради получения конкретных знаний.
Преимущества использования системы Moodle в преподавании...
Система Moodle для преподавателя даёт возможность разработки методики индивидуального обучения на основе новых технологий, создания усовершенствованных онлайн-курсов, позволяющих решать задачи
Innovations in learning technologies for English language teaching.
Метод Case study в обучении английскому языку для специальных...
Кейс-метод нередко называют методом анализа конкретных ситуаций. Основой для создания задания для исследовательского кейса также может являться и содержательная олимпиадная задача.
Похожие статьи
Современные методы и технологии преподавания иностранных...
Конструктивистский метод. Учебная цель: в основе метода находится собственно активное обучение студентов.
Под понятием альтернативные методы группируется целый ряд различных подходов, приемов, способов передачи языка.
Из опыта индивидуализации обучения иностранным языкам
На основе проведенного нами анализа соответствующей литературы, а также опыта работы считаем, что принцип индивидуального подхода (индивидуализации обучения)...
Методологии проектирования мультиагентных систем
В основе мультиагентного подхода лежит понятие программного агента, который реализован и функционирует как самостоятельная элемент программного обеспечения или элемент искусственного интеллекта.
Методология создания МАС на основе онтологии.
Теоретические основы метода Case study в обучении...
Ввиду динамичного протекания глобализационных процессов отчетливо прослеживается интенсификация международного, межкультурного взаимодействия в профессиональной сфере. Обширное поле возможностей для участия в международном сотрудничестве в свою очередь...
Использование языка-посредника в обучении русскому языку...
и в целях контроля. Положив в основу этот теоретическим образом полученный перечень ситуаций, мы решили наложить его на учебный процесс и выявить реальные ситуации использования английского...
Использование методики CLIL на уроках со вторым языком...
Согласно Интегрированной образовательной программе, разработанной на основе модели трехъязычного обучения, язык изучается не ради самого языка, а ради получения конкретных знаний.
Преимущества использования системы Moodle в преподавании...
Система Moodle для преподавателя даёт возможность разработки методики индивидуального обучения на основе новых технологий, создания усовершенствованных онлайн-курсов, позволяющих решать задачи
Innovations in learning technologies for English language teaching.
Метод Case study в обучении английскому языку для специальных...
Кейс-метод нередко называют методом анализа конкретных ситуаций. Основой для создания задания для исследовательского кейса также может являться и содержательная олимпиадная задача.




