При разработке программного обеспечения в высоконагруженных системах требуется определить стратегии при одновременных обновлениях. Множество запросов от одинаковых пользователей приводят к конфликтам транзакций на уровне базы данных. Для предотвращения или смягчения конфликтов рассмотрены основные подходы реализации на уровне приложений на Java и базы данных. Произведен сравнительный анализ между разными видами блокировок и представлены варианты их использования. Представлен альтернативный вариант разрешения конфликтов при интенсивной нагрузке входящих запросов в случае асинхронного взаимодействия.
Ключевые слова: конкурентные транзакции, распределенная блокировка, кеширование входных запросов, асинхронная обработка запросов, оптимистическая и пессимистическая блокировки, высоконагруженные системы, Spring Retry, Java.
Software development in highly loaded systems requires determining strategies for concurrent updates. Multiple requests from identical users lead to transaction conflicts at the database level. The main implementation approaches at the Java application and database level are reviewed to prevent or mitigate conflicts. A comparative analysis between different types of locks is made and options for their use are presented. An alternative variant of conflict resolution in case of an intensive load of incoming requests in the case of asynchronous communication is presented.
Keywords: concurrent transactions, distributed locking, incoming request caching, asynchronous request processing, optimistic and pessimistic locking, highly loaded systems, Spring Retry, Java.
Ситуации, когда различные пользователи или процессы одновременно или почти одновременно пытаются внести изменения в одну и ту же запись, или данные в базе данных, называются одновременными обновлениями. В средах, где работает множество пользователей или процессов, такие обновления могут возникать, когда несколько сущностей, например, пользователи или программы, одновременно пытаются получить и модифицировать одни и те же данные. Это может привести к ряду проблем и вызвать трудности при обработке данных:
— Несогласованность данных: Одновременные обновления могут привести к ситуации, когда база данных отражает противоречивые или некорректные данные, что подрывает ее целостность.
— Потеря обновлений: В случае, когда одно обновление накладывается на другое, предыдущие изменения могут быть безвозвратно потеряны.
— Грязное чтение: Транзакция может получить доступ к данным, которые в данный момент модифицируются другой транзакцией, что приводит к извлечению неполных или искаженных данных.
— Неповторяемые чтения: Когда транзакция выполняет повторное чтение одних и тех же данных и получает различные результаты из-за параллельно происходящих обновлений в других транзакциях, возникает проблема неповторяющихся чтений.
Уровни изоляции в базах данных определяют, насколько транзакции, выполняемые одновременно, изолированы друг от друга, то есть какие данные одна транзакция может видеть и изменять во время выполнения другой транзакции. Уровни изоляции помогают управлять различными проблемами, связанными с одновременным выполнением, такими как грязное чтение, неповторяемое чтение и потерянное обновление. Выбор уровня изоляции зависит от требований к точности данных и производительности в конкретном приложении. Высокие уровни изоляции, например SERIALIZABLE, уменьшают риск аномалий в данных за счет снижения параллельности и производительности, в то время как низкие уровни изоляции могут увеличивать производительность за счет риска возникновения аномалий данных [1, с. 222–226].
Рассмотрим оптимистическую и пессимистическую блокировки [2] для предотвращения конкурентных обновлений.
Пессимистическая блокировка
Используется SQL-запрос, включающий конструкцию FOR UPDATE, которая позволяет осуществить явную блокировку определенной записи в базе данных с целью ее обновления. Такой подход предполагает, что любые другие транзакции, стремящиеся модифицировать эту же запись во время действия блокировки, будут приостановлены до момента ее снятия. Это обеспечивает сохранение согласованности данных за счет предотвращения одновременного доступа к записи. Для использования данной стратегии в Spring Boot приложении с модулем spring-data-jpa достаточно добавить аннотацию org.springframework.data.jpa.repository.Lock на метод репозитория извлечения данных с указанием типа блокировки:
@Lock(LockModeType.PESSIMISTIC_WRITE)
Оптимистическая блокировка
Каждая запись в базе данных имеет атрибут версии. При обновлении записи, проверяется, соответствует ли версия в базе данных версии в запросе. Если версии не совпадают, возникает конфликт (Optimistic Lock Exception), и обновление не выполняется. Для использования в Spring boot приложении достаточно добавить поле version с соответствующей аннотацией:
@Entity
public class User {
@Id
private Long id;
private String name;
@Version
private Integer version;
}
Этот механизм применяется для повышения отзывчивости системы, избегая эксклюзивных блокировок, как в случае использования пессимистической блокировки.
Сравнительный анализ блокировок
На рис. 1 продемонстрирована разница в скорости обработки запросов при оптимистической и пессимистической блокировках. Установлен лимит пула соединений к базе данных в размере 10 и таймаут в 100 миллисекунд для демонстрирования незначительной бизнес манипуляции внутри транзакции. При обработке транзакции наблюдается почти идентично затраченное время на 10 параллельных запросов обновления данных к одной уникальной записи. Увеличение количества конкурентных запросов показывает, как запросы с оптимистической блокировкой выполняются быстрее, тогда как только 10 % от поступающего трафика будет обработано успешно.
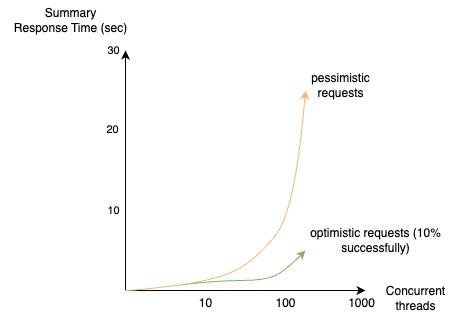
Рис. 1. Сравнительный анализ оптимистической и пессимистической блокировки
Клиент принимает решение повторить запрос, игнорировать или получить ошибку, в случае выбора логики повторной отправки нагрузка на ресурсы будет возрастать, так как необходимо снова получать данные и производить дополнительные операции.
Оптимистическая блокировка используется, когда:
— Конфликты редки: Сценарии, где конкурентные обновления данных происходят нечасто, так как предполагается, что конфликты при доступе к данным — исключение, а не правило.
— Высокие требования к производительности и масштабируемости: Минимизирует накладные расходы на управление блокировками, что положительно сказывается на производительности и масштабируемости системы.
— Кратковременные транзакции: Для систем с большим объемом коротких транзакций, где вероятность конфликта минимальна.
— Распределенные системы: Преобладает в распределенных системах, где пессимистические блокировки могут сильно ухудшить производительность и вызвать проблемы с мертвыми блокировками.
Пессимистическая блокировка используется, когда:
— Конфликты часты: Для приложений, где конкурентные обновления происходят часто, и вероятность конфликта высока.
— Критически важна согласованность данных: Приоритетом является предотвращение любых конфликтов данных и гарантирование их согласованности.
— Длительные транзакции: Транзакции могут занимать продолжительное время, и необходимо гарантировать, что данные не будут изменены другими операциями во время их выполнения.
— Критические операции: Например, в банковских системах, где необходимо обеспечить абсолютную точность и надежность при выполнении транзакций.
В целом, выбор между оптимистической и пессимистической блокировками зависит от специфики бизнес-логики, требований к согласованности данных и ожидаемой нагрузки на систему. Оптимистическая блокировка предпочтительнее в средах с низким уровнем конкуренции за данные и высокими требованиями к производительности, тогда как пессимистическая блокировка лучше подходит для сценариев с высокой конкуренцией и строгими требованиями к согласованности данных.
Повторные отправки запросов
Переотправку запроса возможно переложить на внутренний механизм, например, использовать Spring retry библиотеку для повторного вызова исполняемого кода [3]. Spring Retry рекомендуется тогда, когда необходимо обеспечить надежность выполнения операций в условиях возможных временных сбоев, таких как сбой при отправке запроса на внешний веб-сервис, конфликта при сохранении данных базы данных или deadlock конфликт [4, c 500–502]. Ошибки имеют временный характер и при повторном обращении запросов могут не повторятся.
Распределенная блокировка
Другим подходом является распределенная блокировка [5], которая действует на уровне приложения, представленная на рис. 2. Как правило, блокировка необходима для изменения состояния общего ресурса. Таким образом, когда приложение запущено в нескольких экземплярах, то только один из них имеет доступ к выполнению функции. Блокируется ресурс в экземпляре приложения, и потоки в других узлах ожидают выполнения первого.
Для реализации данного подхода подходит Spring Integration модуль с клиентом Redis, который предоставляет взаимодействие с Lettuce — неблокирующим, на основе Netty, асинхронным и синхронным доступом к данным. Создается org.springframework.integration.redis.util.RedisLockRegistry bean-компонент, с помощью которого устанавливается и снимается блокировка с указанием имени ключа и времени жизни (TTL).
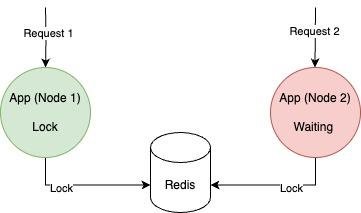
Рис. 2. Распределенная блокировка
Существует два типа блокировок:
— RedisLockType.SPIN_LOCK — блокировка устанавливается периодическим циклом (100 мс), проверяющим, можно ли получить блокировку. По умолчанию.
— RedisLockType.PUB_SUB_LOCK — блокировка приобретается по подписке Redis pub-sub.
Pub-sub является предпочтительным режимом — меньше сетевых помех между клиентским сервером Redis и более производительным — блокировка устанавливается немедленно, когда подписка уведомляется о разблокировке в другом процессе. Однако Redis не поддерживает публикацию-подписку в соединениях Master/Replica (например, в среде AWS ElastiCache), поэтому по умолчанию выбирается режим busy-spin, чтобы реестр работал в любой среде.
Основными недостатками вышеуказанной распределенной блокировки, является поддержка и конфигурация сервера Redis. Если Redis становится недоступным или происходят сбои в его работе, это может повлиять на надежность механизма блокировок. Если приложение не корректно освобождает блокировку после завершения работы, это может привести к ситуации, когда блокировка сохраняется на длительное время. В этом случае все другие узлы приложения могут столкнуться с проблемой доступа к ресурсу, защищенному блокировкой.
Асинхронное взаимодействие
При сценарии, когда происходит асинхронная обработка сообщений [6] существует ряд подходов для снижения конкурентости, например, с использованием кэширования входных сообщений на уровне экземпляра приложения. Сообщения с одинаковыми идентификаторами пользователя складываются в локальную очередь, где по настроенном промежутку времени происходит проверка на время задержки. Для хранения данных предлагается воспользоваться реализацией класса java.util.concurrent.DelayQueue [7]. Приходящие сообщения складываются в локальную очередь, а созданный экземпляр класса java.util.concurrent.ScheduledExecutorService производит периодический опрос на содержание элементов в очереди. Далее производится обработка и обновление в базе данных. Таким образом создается буфер входных сообщений, который обрабатывается через небольшой промежуток времени, тем самым утилизируя или соединения дубликаты, в рамках одного узла. Это способствует сокращению конфликтов с одинаковыми идентификаторами. Также по необходимости добавляется поддержка повторов при помощи Spring Retry в случае возникновения Optimistic Lock Exception. Здесь стоит отметить, что в случае увеличения узлов приложения для сокращения повторных попыток выполнения разумно использовать кэширующий сервер (например, Redis), вместо локального DelayQueue для аккумулирования общих идентификаторов пользователей и дальнейшей обработки уникальных записей среди всех узлов приложения через установленный промежуток времени.
Заключение
Проблема одновременных обновлений в базах данных является ключевым вызовом в современных информационных системах, где множество пользователей и процессов работают с данными одновременно. Стратегии, такие как пессимистическая и оптимистическая блокировки, предлагают различные подходы к обеспечению целостности данных. Пессимистическая блокировка предотвращает конкурентный доступ к данным за счет явной блокировки, что обеспечивает согласованность, но может снизить производительность из-за ожидания освобождения блокировок. Оптимистическая блокировка, с другой стороны, позволяет избежать блокировок за счет проверки версий данных перед обновлением, что уменьшает вероятность конфликтов при одновременных обновлениях, но требует дополнительной логики для обработки возможных исключений при обновлении данных.
Распределенные блокировки и другие подходы, такие как использование кэширования и повторные попытки, дополняют эти стратегии, предлагая дополнительные возможности для управления конкурентным доступом в распределенных и масштабируемых системах. Эти механизмы обеспечивают баланс между надежностью и производительностью, позволяя системам поддерживать согласованность данных при одновременном обеспечении высокой доступности и отзывчивости. Стоит отметить, что транзакции следует максимально ограждать от бизнес-логики, для повышения производительности транзакций и предотвращения конфликтных ситуаций с устаревшими данными.
Выбор между различными стратегиями управления конкуренцией зависит от специфических требований приложения, включая требования к согласованности данных, производительности и масштабируемости. Важно тщательно анализировать потребности бизнеса и характеристики рабочей нагрузки для определения наиболее подходящего подхода, который будет способствовать оптимизации производительности и надежности системы при обработке одновременных обновлений данных.
Литература:
- Kleppmann, M. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems / M. Kleppmann.: O'Reilly Media, 2017. — 590 c.
- Pessimistic and Optimistic Locking in JPA and Hibernate. — Текст: электронный // Serengeti: [сайт]. URL: https://serengetitech.com/tech/pessimistic-and-optimistic-locking-in-jpa-and-hibernate/ (дата обращения: 20.02.2024).
- Guide to Spring Retry. — Текст: электронный // Baeldung: [сайт]. URL: https://www.baeldung.com/spring-retry (дата обращения: 20.02.2024).
- Carlos, C. Database Systems: Design, Implementation, & Management / C. Carlos, M. Steven. — 13th.: Cengage Learning, 2018. — 816 c.
- How to implement a Spring Distributed Lock. — Текст: электронный // Tanzu Developer Center: [сайт]. URL: https://tanzu.vmware.com/developer/guides/spring-integration-lock/ (дата обращения: 20.02.2024).
- Introduction to Asynchronous Processing and Message Queues. — Текст: электронный // Dev: [сайт]. URL: https://dev.to/apoorvtyagi/introduction-to-asynchronous-processing-and-message-queues-27od (дата обращения: 20.02.2024).
- DelayQueue Class in Java with Example. — Текст: электронный // Geeksforgeeks: [сайт]. URL: https://www.geeksforgeeks.org/delayqueue-class-in-java-with-example/ (дата обращения: 20.02.2024).

