В данной статье рассмотрены основные подходы к разработке систем рекомендаций на основе Big Data, включая коллаборативную фильтрацию, контентную фильтрацию и гибридные методы, а также представлены примеры реализации алгоритмов на языке программирования Python.
Ключевые слова: системы рекомендаций, большие данные, алгоритмы рекомендаций, рекламные алгоритмы, прогнозирование.
This article examines the main approaches to developing recommendation systems based on Big Data, including collaborative filtering, content-based filtering, and hybrid methods. It also presents examples of algorithm implementations in the Python programming language.
Keywords: recommendation systems, big data, recommendation algorithms, advertising algorithms, forecasting.
Введение
В эпоху цифровизации и увеличения объемов данных, создание эффективных систем рекомендаций становится ключевым аспектом для улучшения пользовательского опыта в различных сферах, включая электронную коммерцию, потоковое вещание и социальные сети. Системы рекомендаций используют алгоритмы машинного обучения для анализа поведения пользователей, их предпочтений и взаимодействий с продуктами или услугами, чтобы предложить наиболее релевантный и персонализированный контент.
Коллаборативная фильтрация
Коллаборативная фильтрация — это метод, основанный на анализе и сравнении предпочтений пользователя с предпочтениями других пользователей для выявления схожих вкусов. Этот метод можно реализовать с использованием двух основных подходов: основанного на пользователях (user-based) и основанного на объектах (item-based) [1].
Пример реализации user-based коллаборативной фильтрации на Python представлен на рисунке 1.
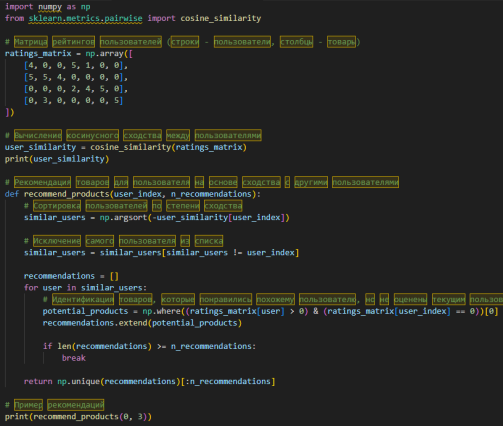
Рис. 1. Пример реализации user-based коллаборативной фильтрации
В данном примере используется матрица рейтингов пользователей для вычисления косинусного сходства между ними. Функция recommend_products генерирует рекомендации на основе анализа предпочтений похожих пользователей.
Контентная фильтрация
Контентная фильтрация фокусируется на атрибутах объектов, используя описание продукта и профиль предпочтений пользователя для выявления наилучшего соответствия. Этот подход позволяет рекомендовать объекты, даже если между пользователями нет существенной взаимосвязи, основываясь на их уникальных предпочтениях в содержании [1].
Пример реализации контентной фильтрации на Python представлен на рисунке 2.
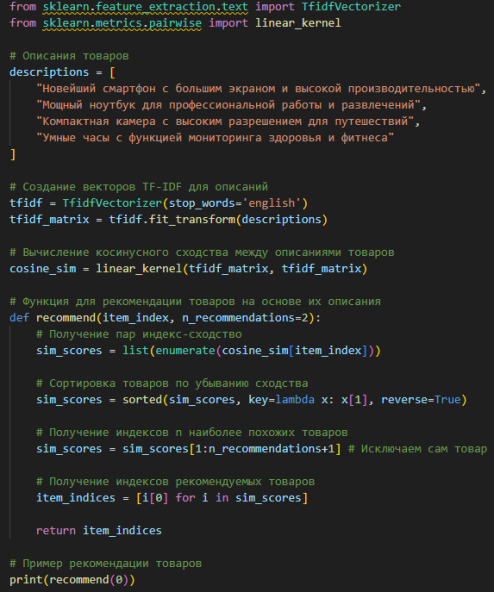
Рис. 2. Пример реализации контентной фильтрации на Python
В данном фрагменте кода используется TF-IDF векторизация для преобразования текстовых описаний товаров в числовые векторы. Затем, на основе косинусного сходства между этими векторами, функция recommend выдает индексы товаров, наиболее похожих на заданный товар.
Гибридные методы
Гибридные системы рекомендаций комбинируют подходы коллаборативной и контентной фильтрации для улучшения качества рекомендаций и преодоления их ограничений. Преимуществом гибридных систем является их способность использовать разнообразные источники данных для более точного предсказания предпочтений пользователей [2].
Пример простого гибридного подхода представлен на рисунке 3.
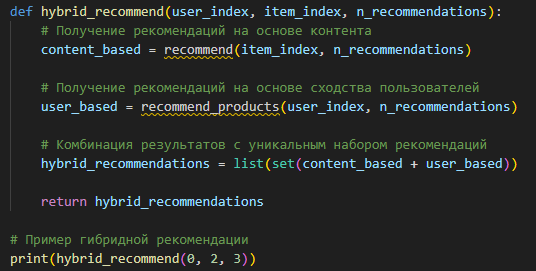
Рис. 3. Пример простого гибридного подхода
В данном примере гибридной системы рекомендаций комбинируются результаты из контентной фильтрации и коллаборативной фильтрации, чтобы предоставить пользователю наиболее релевантные и персонализированные рекомендации.
Литература:
- Data Mining. Извлечение информации из Facebook[*], Twitter, LinkedIn, Instagram, GitHub. — СПб.: Питер, 2020. — 464 с.: ил.
- Data Science. Наука о данных с нуля: Пер. с англ. — 2-е изд., перераб. и доп. — СПб.: БХВ-Петербурr, 2021. — 416 с.: ил.
[*]Instagram и Facebook, продукты компании Meta, которая признана экстремистской организацией в Росси

