Статья посвящена рассмотрению существующих на сегодняшний день вариантов решения проблемы распознавания символов печатного текста. В процессе исследования отдельное внимание уделено системе оптического распознавания символов, а именно специализированным алгоритмам. В частности, рассмотрен алгоритм на основе грамматик, алгоритм линейного распределения, алгоритм контурного анализа, алгоритм на основе нейронных сетей. Также выделены возможности этих алгоритмов, особенности их работы, достоинства и недостатки.
Ключевые слова : алгоритм, текст, символ, распознавание, грамматика, контур, анализ, обработка, нейронная сеть.
The article is devoted to the consideration of the currently existing options for solving the problem of recognizing characters in printed text. In the process of research, special attention is paid to the system of optical character recognition, namely, specialized algorithms. In particular, an algorithm based on grammars, a linear distribution algorithm, and a contour analysis algorithm are considered. The possibilities of these algorithms, the features of their work, advantages and disadvantages are also highlighted.
Keywords: algorithm, text, symbol, recognition, grammar, contour, analysis, processing, neural network.
Сегодня существует большой спрос на хранение в цифровом виде текстовой информации, размещенной в печатных, графических или рукописных документах, с целью дальнейшей ее обработки, редактирования и анализа. Кроме того, обширное распространение инструментов сканирования и оцифровки способствовало стремительному развитию методов и способов детектирования текста, которые в целом получили название системы оптического распознавания символов (OCR). Эти системы дают возможность в автоматическом режиме проводить анализ различных документов, подготавливать текстовые данные в редактируемых форматах для их дальнейшей обработки [3].
Необходимо отметить, что в последние годы системы распознавания печатного текста стали достаточно эффективными. В тоже время, текущие технологии все еще имеют ряд ограничений, чтобы распознавать текстовые изображения разных стилей и языков ввода. Также актуальной остается проблема обеспечения качества обработки в зависимости от таких факторов как: цвет, шрифт, расстояние между символами.
Обозначенные обстоятельства обуславливают необходимость проведения дальнейших исследования в данной предметной области, что и предопределило выбор темы этой статьи.
Описанию технологии оптического распознавания символов уделяется большое внимание в работах отечественных и зарубежных авторов. Так, в трудах Коноваленко И. А., Полевого Д. В., Николаева Д. П., Qamar, Faizan; Al-Sheikh, Idris исследуются этапы и методы распознавания текста.
Однако, несмотря на активные разработки и внимание к исследуемым вопросам, появление новых цифровых технологий и возможностей предопределяет необходимость актуализации имеющихся наработок и их регулярного пересмотра.
Таким образом, с учетом вышеизложенного, цель статьи заключается в проведении анализа современных алгоритмов распознавания символов печатного текста.
На сегодняшний день создан уже достаточно широкий спектр разнообразных алгоритмов (шаблонные, структурные, признаковые, статистические), которые незначительно отличаются по функционалу, но могут существенно различаться по качеству обработки текста. Некоторые допускают довольно много ошибок в распознавании, тогда как другие идентифицируют символы практически идеально.
Рассмотрим некоторые алгоритмы более подробно.
Алгоритм на основе грамматик . Грамматики представляют собой набор определенных правил распознавания символов.
Можно выделить следующие методы создания грамматик:
– использование теории графов. Текст представлен в виде размеченного графа. Задачи распознавания символов ставятся как задачи нахождения изоморфизма эталонного и входного графов, или изоморфизма их подграфов;
– методы теории формальных языков и грамматик. Символ рассматривается в некотором формальном языке, который задается с помощью конструкций, являющихся обобщениями грамматик Хомского. Распознавание заключается в отыскании лучшего в определенном смысле вывода изображения в заданной грамматике [1].
Особую популярность сегодня получили двумерные контекстно-свободные грамматики. В тоже время заложенная в них постановка задачи на точное совпадение, очевидно, имеет ряд недостатков, существенно ограничивающих их практическое применение для распознавания символов:
– с точки зрения распознавания символов формализм двумерных контекстно-свободных грамматик не всегда позволяет найти реальное изображение, которое можно разделить на прямоугольные фрагменты;
– чрезмерная детализация правил грамматики: для каждого символа следует указывать, каким образом он состоит из меньших частей вплоть до уровня отдельных пикселей.
Алгоритм линейного распределения . Процедура линейного разделения текста разбивает строки на слова, а слова — на отдельные буквы. После этого, по принципу IPA (integrity, purposefulness, adaptability) формируется набор гипотез (т. е. возможных вариантов идентификации каждого символа) и, обеспечив оценку вероятности, результат передается на вход системы распознавания [2].
В соответствии с первым принципом целостности (integrity) объект (символ) рассматривается как единое целое, которое состоит из нескольких взаимосвязанных частей. Принцип целеполагания (purposefulness): любая интерпретация данных должна иметь некую цель. Т. е. распознавание представляет собой процесс формулировки гипотез об объекте и их подтверждение или опровержение. Третий принцип — адаптивность (adaptability) — предполагает способность системы самостоятельно обучаться и использовать в дальнейшем ранее собранную информацию. Полученные в ходе распознавания данные упорядочиваются, хранятся и используются впоследствии для решения аналогичных задач.
Алгоритм контурного анализа . Основным преимуществом алгоритмов данной группы является их простота и скорость работы, а также минимальное влияние внешних факторов на результаты работы программных систем с элементами контурного анализа. Суть алгоритма контурного анализа при распознавании символов сводится к точному представлению границ для чего используется четыре модели кривых и методы подгонки моделей к краевым точкам. Модели включают: отрезки линий; круговые дуги; конические сечения; кубические сплайны. Алгоритм в процессе распознавания решает два вопроса: какой метод применяется для подгонки кривой к краям и как измеряется точность передачи контура.
Алгоритм на основе нейронной сети . Алгоритм распознавания текста с использованием нейронной сети заключается в следующем: на вход нейронной сети подается растровое изображение текста. В начале по входному тексту рассчитываются определенные признаки. Результатом расчетов является некоторый вектор значений признаков. Каждый выход нейронной сети соответствует определенной букве алфавита, а получаемое в итоге значение представляет собой уровень принадлежности буквы конкретному нечеткому множеству.
Задачей алгоритма является обобщение информации, поступающей в виде нечетких входных множеств и вычисление на их основе исходного нечеткого подмножества множественного числа распознавания символов. На последнем этапе принимается решение о выборе наиболее правдоподобного варианта прочтения слова.
Проанализируем на конкретном примере особенности работы нейронной сети для распознавания печатного текста.
Рассмотрим сверточную нейронную сеть, которая обучается по методу обратного распространения ошибки (back propagation) см. рис. 1.
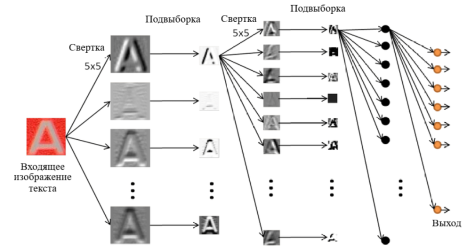
Рис. 1. Архитектура сверточной нейронной сети для распознавания текста
Такая архитектура предполагает прохождение трех взаимосвязанных этапов распознавания текста.
- Обработка изображения и распознавание текста в целом. Этот этап необходим для обнаружения границ текста. Данная процедура происходит с помощью фильтров изображения для обнаружения того, где находится текст, а где изображены обычные «шумовые» предметы (ручка, карандаш, точки на изображении и др.).
Каждый фрагмент изображения текста поэлементно умножается на матрицу весов (ядро), после чего результат суммируется. Эта сумма является пикселем исходного изображения, называемого картой признаков. После этого взвешенная сумма входов пропускается через функцию активации:
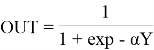
где
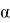
- Обработка каждого отдельного слова посредством определения отступлений между словами. Главной проблемой этого этапа может быть перепутывание буквы в слове с отдельным словом. Для решения этой проблемы нейронная сеть должна научиться приспосабливаться к отдельным шрифтам и языкам.
- Выявление отдельных букв в слове и определения, на какие из алфавита они больше всего похожи (см. рис. 2).

Рис. 2. Пример распознанных текстов
Зеленые дуги обозначают символы, расположенные между последовательными «точными» сегментациями, а красные дуги представляют различные возможные конфигурации, связанные с «рискованными сегментациями», синие — кадрированные символы.
Таким образом, в процессе исследования рассмотрены различные алгоритмы распознавания символов в печатном тексте. Для распознавания текстовых документов с высоким качеством (низкий процент шумов, четкий шрифт и т. д.) целесообразно использовать алгоритмы на основе грамматик, линейного распределения. Структурные алгоритмы (алгоритмы контурного анализа, алгоритмы на основе нейронной сети) будут эффективны при распознавании сложных символов.
Литература:
- Text analytics: an introduction to the science and applications of unstructured information analysis / John Atkinson-Abutridy. Boca Raton: Chapman & Hall/CRC, 2022. 287 p.
- Гринченков Д. В. Решение задачи построения запросов в системе тематического поиска на основе распознавания частично структурированных текстов // Известия высших учебных заведений. Северо-Кавказский регион. Технические науки. 2019. № 1 (201). С. 10–16.
- Шакиров И. Ш., Калаков Б. А. Использование нейронных сетей в архитектуре машинного распознавания текста // Естественные и технические науки. 2019. № 11 (137). С. 363–367.

