В статье рассматривается алгоритм сегментации и шумоочистки речевого сигнала, основанный на вычислении кратковременной энергии и использующий качественные пороговые оценки для идентификации пауз. Расчеты показали, что спектральные центроиды позволяют эффективно определять зашумленные участки речевого сигнала. Разработан метод формирования грамматической формы слова на основе его фонетического представления с использованием метрик Левенштейна и Дамерау-Левенштейна. По результатам распознавания можно заключить, что алгоритм Дамерау-Левенштейна лучше всего подходит для получения грамматической формы слова.
Ключевые слова: распознавание речи, сегментация, метрика Дамерау-Левенштейна, спектральный центроид.
Для повышения точности вычисления речевых признаков и уменьшения числа операций по обработке сигнала необходимо отделить «полезную» информацию от пауз. Существуют различные алгоритмы сегментации сигнала [2; 3]. Общей их чертой является разбиение сигнала на кадры и их анализ. При обработке речевых сигналов, как правило, оперируют не с исходным речевым сигналом, а с его параметрами, вычисленными на кадре. Длина кадра обычно выбирается такой, чтобы его длительность по времени составляла 10–20 мс, это обусловлено тем, что в связи с инерционностью артикуляционных органов на данном интервале параметры сигнала практически неизменны [1]. В исследовании сегментация речи производилась согласно алгоритму, предложенному в [4]. Он сочетает в себе вычисление кратковременной энергии, но в то же время использует более качественные пороговые оценки для идентификации пауз в сигнале. Для иллюстрации работы алгоритмов в среде Visual Studio на языке C# с выполнением интеграции с пакетом MATLAB был разработан модуль преобразования речи в текст (рис. 1).
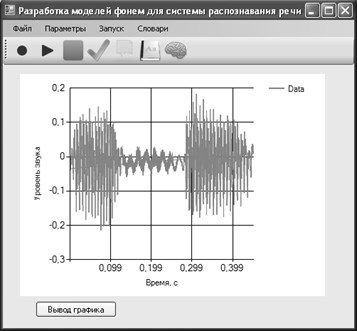
Рис. 1. Пользовательский интерфейс приложения. Записано слово «ОСА».
Пусть ![]() —
— ![]() -й фрейм сигнала длины
-й фрейм сигнала длины ![]() . Тогда его энергия будет иметь следующий вид:
. Тогда его энергия будет иметь следующий вид:
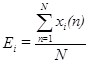 (1)
(1)
Соотношение (1) может быть использовано для того, чтобы обнаружить тихие периоды в сигналах. Ниже приведена программная реализация вычисления энергии сигнала в среде MATLAB:

Наряду с энергией в [31] вводится понятие спектрального центроида:
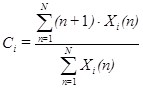 (2)
(2)
где ![]() — коэффициент дискретного Фурье-преобразования последовательности
— коэффициент дискретного Фурье-преобразования последовательности ![]() .
.
Спектральный центроид является важной характеристикой, позволяющей оценивать особенности звука. Эксперименты показали, спектральные центроиды в последовательности чрезвычайно вариативны для речевых сегментов.
Ниже приведена реализация вычисления спектрального центроида сигнала:
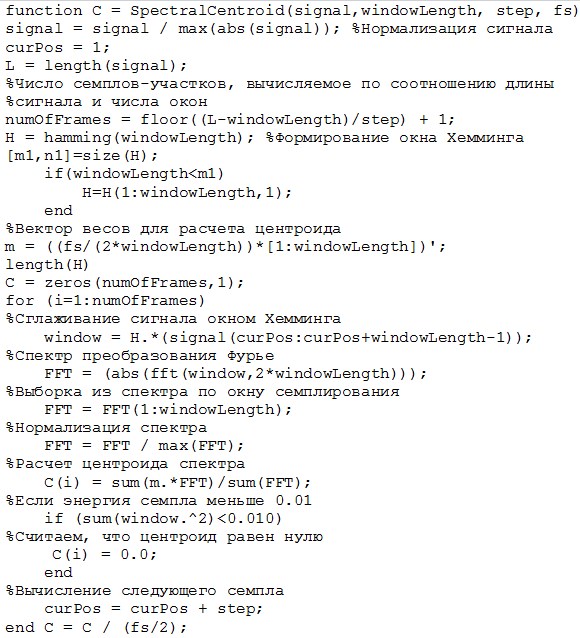
Алгоритм сегментации речи [4] заключается в следующем:
1. Вычисление гистограммы последовательностей энергий и центроидов.
2. Применение сглаживающего фильтра к гистограммам.
3. Обнаружение локальных максимумов гистограмм.
4. Пусть величины ![]() и
и ![]() являются положениями первого и второго локальных максимумов соответственно. Тогда пороговое значение составит:
являются положениями первого и второго локальных максимумов соответственно. Тогда пороговое значение составит:
![]() (3)
(3)
где ![]() — определенный пользователем параметр.
— определенный пользователем параметр.
В том случае, если значения энергии (1) и центроида (2), превышают значение своих порогов (3), то сегмент считается вокализованным, в противном случае мы будем иметь дело с шумом или невокализованным промежутком.
Чтобы наглядней показать работу алгоритма откроем речевой сигнал (слово «ОСА», произнесенное несколько раз). После задания параметров сегментации (рис. 5–6) и нажатия кнопки «Сегментация» появляется отображение сегментированного сигнала во временной области. При этом паузы, шумы в сигнале выделены одним цветом, а «полезный» сигнал, который в дальнейшем подается на блок распознавания — другим цветом (рис. 2).
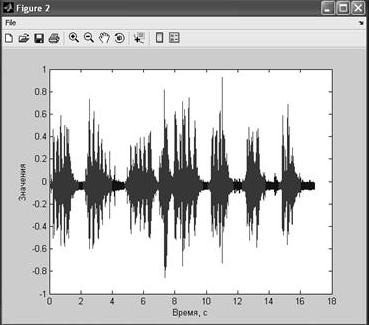
Рис. 2. Отображение сегментированного сигнала во временной области.
Наряду с графиком сегментированного сигнала выводится дополнительная информация, содержащая косвенные данные о качестве сегментации (рис. 3).
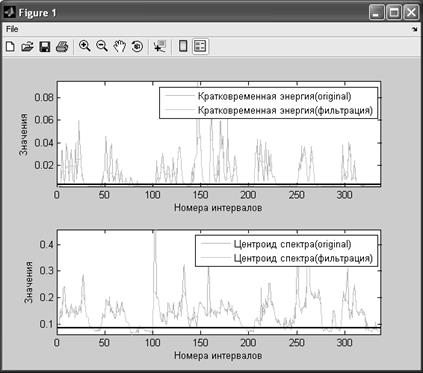
Рис. 3. Кратковременная энергия и центроид спектра.
На выходе блока распознавания после анализа всех сегментов сигнала и принятия решения об их соответствии конкретным фонемам получаем символьную строку, характеризующую последовательность сегментов фонем. Полученная цепочка поступает на вход блока формирования слов для поиска грамматической формы слова.
Выполняется следующая последовательность действий:
1. Формирование фонем из повторяющихся сегментов;
2. Формирование фонетической формы слова;
3. Поиск грамматической формы слова.
Так как временной интервал, на котором рассчитываются характеристики фонемы меньше ее средней длины, то цепочка включает повторяющиеся сегменты, из которых происходит формирование отдельных фонем. Например, из последовательности «ИИИВВВААААА» можно с учетом устранения повторяющихся фонем сформировать слово «ИВА».
Чтобы сформировать правильную фонетическую форму распознаваемого слова из полученной строки необходимо располагать информацией о наиболее вероятных сочетаниях фонем языка. В этих целях была реализована база в виде текстового файла, хранящего вероятности сочетаний фонем. Для оценки качества выбора фонем использовалась частотная вероятность их встречаемости. При этом использовались значения условных вероятностей сочетаний, рассчитанные с помощью правила Байеса:
![]() , (4)
, (4)
где ![]() — условная вероятность того, что за фонемой
— условная вероятность того, что за фонемой ![]() следует фонема
следует фонема ![]() ;
;
![]() — частотная вероятность встречаемости фонемы
— частотная вероятность встречаемости фонемы ![]() ;
;
![]() — частотные вероятности встречаемости фонем
— частотные вероятности встречаемости фонем ![]() .
.
При анализе вероятностных характеристик с применением (4), выбиралась та фонема, вероятность появления которой в слове была максимальна.
Например, для транскрибированной последовательности ВАФЗА, так как ![]() , то принималось решение: ВАФЗА → ВАЗА. На выходе блока формирования фонетического представления слова получаем строку, которая в случае правильной интерпретации и будет являться целевой формой распознаваемого слова.
, то принималось решение: ВАФЗА → ВАЗА. На выходе блока формирования фонетического представления слова получаем строку, которая в случае правильной интерпретации и будет являться целевой формой распознаваемого слова.
Данная форма, синтезированная по результатам анализа встречаемости фонем, сопоставлялась со словами, заложенными в словаре (рис. 4). Использовался алгоритм нечеткого поиска, где критериями близости слов являлись редакционные расстояния Левенштейна и Дамерау-Левенштейна.
Алгоритмы нечеткого поиска (также известные как поиск по сходству) являются основой систем проверки орфографии, а также полноценных поисковых систем (вроде Google или Yandex). Помимо этого, они применимы для получения конечной грамматической формы слова при распознавании речи.
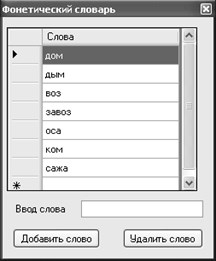
Рис. 4. Пример фонетического словаря для сравнения.
Алгоритм Левенштейна заключается в следующем. Пусть ![]() и
и ![]() — две строки длиной
— две строки длиной ![]() и
и ![]() соответственно, тогда расстояние Левенштейна
соответственно, тогда расстояние Левенштейна ![]() вычисляется по формуле
вычисляется по формуле ![]() , при этом элементы:
, при этом элементы:
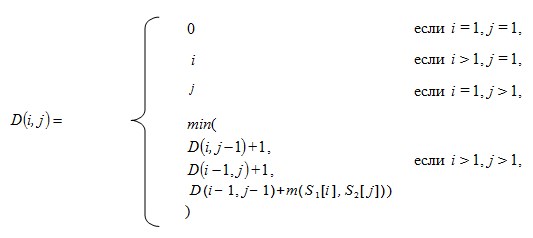
где
Рис. 5. Настройка параметров сегментации. Метрика Левенштейна.
Реализация вычисления расстояния Левенштейна была выполнена в среде MATLAB и имеет следующий вид:

Рис. 6. Настройка параметров сегментации. Метрика Дамерау-Левенштейна.
Алгоритм вычисления расстояния Левенштейна был импортирован из MATLAB в C# и встроен как часть функционала приложения для поиска наиболее близкой словарной формы. Исходный код реализации нечеткого поиска с применением алгоритма Левенштейна на C#:


Рис. 7. Результат распознавания слова «ОСА». Метрика Левенштейна.
Для расстояния Левенштейна набор элементарных операций состоит из операции замены, вставки и удаления одной буквы. Если расширить этот набор операцией перестановки соседних символов (при условии, что эти символы являются смежными в обоих словах), то получим расстояние Дамерау-Левенштейна.
Алгоритм Дамерау-Левенштейна учитывает транспозицию (перестановку) как одну операцию, наряду со вставками, удалениями и заменами. Большинство ошибок при наборе текста являются транспозициями, поэтому именно данная метрика в ряде случаев дает наилучшие результаты на практике (пример приведен на рис. 7–8). Код представлен ниже:




Рис. 8. Результат распознавания слова «ОСА». Метрика Дамерау-Левенштейна.
В процессе работы была построена база данных признаков эталонов фонем, взят небольшой набор слов для тестирования (20 слов по 4–5 образцов). Некоторые образцы были целенаправленно зашумлены. Метод сегментации и шумоочистки, описанный ранее, показал высокую эффективность. Это обусловлено тем, что введение спектральных центроидов позволяет более качественно определять сегменты, содержащие шум, поскольку уровень центроида на зашумленных участках сигнала существенно ниже, чем на тех, которые несут «полезную» информацию. Средний коэффициент распознавания слов при использовании метрики Левенштейна составил 91,5 %, Дамерау-Левенштейна — 96 %. Отсюда можно заключить, что алгоритм Дамерау-Левенштейна в целях формирования грамматической формы слова наиболее предпочтительней.
Литература:
1. Михайлов В. Г., Златоустова Л. В. Измерение параметров речи. — М.: Радио и связь, 1987. — 168 с.
2. Фланаган Дж.Л. Анализ, синтез и восприятие речи / пер. с англ. А. А. Пирогова. М.: Связь, 1968. 397 с.
3. Вишнякова О. А., Лавров Д. Н. Применение преобразования Гильберта-хуанга к задаче сегментации речи // Математические структуры и моделирование. — 2011. вып. 24. — с. 12–18
4. T. Giannakopoulos, “Study and application of acoustic information for the detection of harmful content, and fusion with visual information,” Ph.D. dissertation, Dpt of Informatics and Telecommunications, University of Athens, Greece, 2009.

