Ключевые слова:классификация текста, машинное обучение, обработка естественного языка, тональность текста
Анализ мнений — это тип обработки естественного языка для отслеживания настроения общественности о конкретном продукте. Анализ мнений, который также называют анализом тональности, включает в себя сбор и категоризацию мнений о продукте. Автоматизированный анализ тональности часто использует такой тип искусственного интеллекта как машинное обучение.
Анализ мнений может быть очень полезен во многих случаях. Например, он может помочь крупным компаниям оценить успех новых выпускаемых продуктов; понять, какие версии продуктов популярны; распознать, каким пользователям нравятся функции продукта, каким нет.
Кроме того, есть некоторые сложности анализа тональности. Например, слово, которое считается позитивным в одной ситуации, может быть негативным в другой. Возьмем для примера слово «долгий». Если пользователь говорит, что заряд батареи у ноутбука долгий, то это будет позитивное мнение. Если он говорит, что загрузка операционной системы была долгой, то это мнение будет негативным. Это означает, что система, обученная анализу мнений на одной функции продукта, не обязательно будет правильно работать на другой.
Количество отзывов пользователей в интернете достигает нескольких сотен тысяч. Очевидно, что оценка и обработка отзывов вручную становится невозможной.
В данной статье рассматривалась задача классификации тональности текстов.
Целью работы являлось сравнение методов оценки окраса и тональности текста, программная реализация системы классификации, оценка точности алгоритма.
- Классификация тональности текста
Классификация — это соотношение некоторых входных данных с одним или несколькими классами. Классификация текста в исходном виде является невозможной, для начала надо разбить текст на некоторое понятное классификатору представление. Эта операция называется индексацией текста. Документ можно представить в виде вектора терминов, называемого векторной моделью [1].
Тональность — это эмоциональное отношение автора высказывания к некоторому объекту (объекту реального мира, событию, процессу или их свойствам/атрибутам), выраженное в тексте [2].
Основной целью анализа тональности является нахождение мнений в тексте и выявление их свойств. Какие именно свойства будут исследоваться, зависит уже от поставленной задачи.
В компьютерных программах автоматизированного анализа тональности применяют алгоритмы машинного обучения, инструменты статистики и обработки естественного языка, что позволяет обрабатывать большие массивы текста, включая веб-страницы, онлайн-новости, тексты дискуссионных групп в сети Интернет, онлайн-обзоры, веб-блоги и социальные медиа [2].
Существует множество методов классификации текстовых документов. Далее приведены только те, которые будут использованы в настоящей работе:
– логистическая регрессия (Logistic Regression);
– деревья решений (Decision tree);
– наивный байесовский классификатор (Naive Bayes Classifier);
– Random Forest;
– стохастический градиентный спуск (StochasticGradientDescent).
- Выбор размеченного корпуса документов
В свободном доступе найден размеченный корпус документов на основе микроблоггинг-платформы twitter [3].
Для разметки на два класса (положительные и отрицательные), тестовая выборка отфильтрована, согласно следующим критериям:
– удалены все твиты, содержащие одновременно и положительные и отрицательные эмоции;
– как выяснилось, API twitter отдает в результатах выдачи копии twitter-постов, в связи с этим удалены одинаковые посты из выборки;
– удалены малоинформативные твиты, длина которых составляла менее 40 символов.
В результате получен тренировочный корпус, состоящий из 114911 положительных, 111923 отрицательных записей.
- Основные этапы работы системы
Работа системы была разделена на три основных этапа:
– индексация документа;
– обучение классификатора;
– оценка качества работы классификатора.
- Индексация документа
Первый этап предобработки корпуса документов — это приведение всех слов к начальной форме (лемматизация). Это позволит реализовать и использовать векторную модель документа, в которой каждое слово уникально. Для решения этой задачи использовался морфологический анализатор pymorphy2 [4].
При индексации необходимо избавиться от слов, не несущих тональности текста. Это могут быть предлоги, союзы, знаки препинания. Они могут часто встречаться, при этом не нести никакой полезной нагрузки.
Затем необходимо выделить из корпуса документов ключевые слова. Для этого используется модель TFIDF, описанная ниже.
Иногда слова могут встречаться во многих документах текстовой коллекции. Следовательно, они не могут характеризовать принадлежность документа тому или иному классу, так как не являются ключевыми. Поэтому вводится так называемая мера IDF (обратная частота документа), которая понижает значимость частотных слов.
![]() (1)
(1)
где D — количество всех документов, d — количество документов, в которых содержится данное слово. Таким образом, чем чаще слово встречается, тем меньше его IDF.
Мера TF (term frequency) — отношение частоты некоторого слова к общему числу слов в документе. Мера оценивает важность слов в пределах документа.
TFIDF равен произведению TF и IDF. Таким образом, TF является повышающим множителем, а IDF — понижающим. Больший вес получат слова, которые часто встречаются в одном документе, но редко в других.
На выходе получается список вида:
 ,
,
посмотрев на который, можно отсеять термы с заведомо низким tfidf.
- Обучение классификатора
В алгоритмах классификации происходит сравнение текста, поступающего на вход, с ранее размеченным корпусом документов по мере близости. Далее происходит классификация текста какому-либо известному классу на основании результатов сравнения.
Обучение состоит в выборе общей формы классифицирующего правила с множеством различных параметров. Предварительно производится выбор параметров на обучающем наборе документов.
Для обучения классификатора использовались готовые методы из библиотеки scikit-learn [5].
- Оценка результатов классификации
Как оценивать качество алгоритма? Допустим, вы хотите внести изменения в алгоритм. Откуда вы знаете, что эти изменения сделают алгоритм лучше? Конечно же, надо проверять алгоритм на реальных данных. Качество построенного классификатора оценивается по его ошибке на тестовом подмножестве обучающего множества документов. Ошибка — это доля неправильных решений классификатора. Решения классификатора сравнивают с решениями экспертов, формирующих обучающее множество [6].
Для расчета качества в задачах анализа данных необходимо составить таблицу категорий принятых решений (табл. 1).
Таблица 1
Таблица категорий
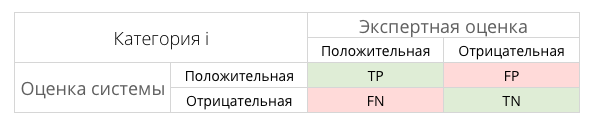
В таблице содержится информация о том, сколько раз система приняла верное и неверное решения по заданным классам:
– TP — истинно-положительное решение;
– FP — ложно-положительное решение;
– FN — ложно-отрицательное решение;
– TN — истинно-отрицательное решение.
Точность (precision) — доля документов, являющихся положительными от общего числа примеров, классифицированных как положительные.
![]() (2)
(2)
Полнота (recall) — доля правильно классифицированных положительных примеров от общего числа положительных примеров.
![]() (3)
(3)
F-мера (F-measure) — мера, комбинирующая точность и полноту.
![]() (4)
(4)
Оценить качество классификации — сложная задача. Даже опытные эксперты иногда не могут соотнести конкретный документ с какой-либо категорией. Возникает вопрос: чего в таком случае можно ожидать от компьютера?
Существуют два подхода к оценке качества классификации. Первый основан на сравнении классификаторов между собой. Второй является абсолютной оценкой.
В данной работе используется абсолютная оценка качества, которая включает в себя оценку таких метрик, как точность, полнота и F-мера. Метрики вычисляются путем кросс-валидации обучающего множества.
- Рассчитанные метрики иматрицы неточностей
В этом разделе выполнялось тестирование классификатора на разных алгоритмах машинного обучения. По каждому тесту приведены матрицы неточностей и таблицы с рассчитанными метриками. Также приведена сводная таблица по всем методам классификации.
Наивный байесовский классификатор
Таблица 2
Отчет по метрикам
|
class |
precision |
recall |
f1-score |
|
0 |
0.63 |
0.73 |
0.67 |
|
1 |
0.68 |
0.56 |
0.61 |
|
avg/total |
0.65 |
0.65 |
0.64 |
Таблица 3
Матрица неточностей
|
Экспертная оценка | |||
|
Положительная |
Отрицательная | ||
|
Оценка системы |
Положительная |
14637 |
5363 |
|
Отрицательная |
8738 |
11262 | |
Логистическая регрессия
Таблица 4
Отчет по метрикам
|
class |
precision |
recall |
f1-score |
|
0 |
0.7 |
0.64 |
0.67 |
|
1 |
0.67 |
0.73 |
0.7 |
|
avg/total |
0.68 |
0.68 |
0.68 |
Таблица 5
Матрица неточностей
|
Экспертная оценка | |||
|
Положительная |
Отрицательная | ||
|
Оценка системы |
Положительная |
12762 |
7238 |
|
Отрицательная |
5425 |
14575 | |
Random forest
Таблица 6
Отчет по метрикам
|
class |
precision |
recall |
f1-score |
|
0 |
0.64 |
0.57 |
0.61 |
|
1 |
0.62 |
0.68 |
0.65 |
|
avg/total |
0.63 |
0.63 |
0.63 |
Таблица 7
Матрица неточностей
|
Экспертная оценка | |||
|
Положительная |
Отрицательная | ||
|
Оценка системы |
Положительная |
11462 |
8538 |
|
Отрицательная |
6318 |
13682 | |
Деревья решений
Таблица 8
Отчет по метрикам
|
class |
precision |
recall |
f1-score |
|
0 |
0.64 |
0.65 |
0.65 |
|
1 |
0.65 |
0.64 |
0.64 |
|
avg/total |
0.64 |
0.64 |
0.64 |
Таблица 9
Матрица неточностей
|
Экспертная оценка | |||
|
Положительная |
Отрицательная | ||
|
Оценка системы |
Положительная |
13052 |
6948 |
|
Отрицательная |
7279 |
12721 | |
СТОХАСТИЧЕСКИЙ ГРАДИЕНТНЫЙ СПУСК
Таблица 10
Отчет по метрикам
|
class |
precision |
recall |
f1-score |
|
0 |
0.7 |
0.44 |
0.54 |
|
1 |
0.59 |
0.81 |
0.68 |
|
avg/total |
0.64 |
0.63 |
0.61 |
Таблица 11
Матрица неточностей
|
Экспертная оценка | |||
|
Положительная |
Отрицательная | ||
|
Оценка системы |
Положительная |
8893 |
11107 |
|
Отрицательная |
3879 |
16121 | |
Сводная таблица по всем методам
Таблица 12
Сводная таблица
|
Algorithm |
precision |
recall |
F-measure |
|
Naïve Bayes |
0.65 |
0.65 |
0.64 |
|
Logistic Regression |
0.68 |
0.68 |
0.68 |
|
Random Forest |
0.63 |
0.63 |
0.63 |
|
Decision Tree |
0.64 |
0.64 |
0.64 |
|
Stochastic Gradient Descent |
0.64 |
0.63 |
0.61 |
Из таблицы видно, что логистическая регрессия показывает самое лучшее и вполне достойное качество классификации из всех выбранных алгоритмов.
Заключение
В данной работе рассматривалась задача классификации тональности текстов постов, распаршенных из социальной сети Twitter.
Рассмотрены несколько алгоритмов машинного обучения, рассмотрена модель TFIDF. Проанализированы подходы к классификации тональности корпуса документов. Расписана методика тестирования качества классификации, а именно:
– расчет точности;
– расчет полноты;
– расчет f-меры, комбинирующей точность и полноту.
Выбран размеченный корпус документов на основе микроблоггинг-платформы twitter. Расписаны этапы работы классификатора:
– индексация документа;
– обучение классификатора;
– оценка качества работы классификатора.
Корпус документов был отлемматизирован и были найдены ключевые слова. Приведена сводная таблица оценки качества по пяти алгоритмам машинного обучения, на которых классификатор был обучен. Выбран алгоритм, показывающий самую высокую точность классификации.
Литература:
- Задача классификации — Википедия: [Электронный ресурс]. URL: http://ru.wikipedia.org/wiki/Задача_классификации (дата обращения: 15.11.2015).
- Анализ тональности текста — Википедия: [Электронный ресурс]. URL: http://ru.wikipedia.org/wiki/Анализ_тональности_текста (дата обращения: 15.11.2015).
- Ю. В. Рубцова. Построение корпуса текстов для настройки тонового классификатора // Программные продукты и системы, 2015, № 1(109), –С.72–78.
- Korobov M.: Morphological Analyzer and Generator for Russian and Ukrainian Languages // Analysis of Images, Social Networks and Texts, pp 320–332 (2015).
- scikit-learn: machine learning in Python: [Электронныйресурс]. URL: http://scikit-learn.org (дата обращения: 30.11.2015).
- Боярский К. К. Введение в компьютерную лингвистику. Учебное пособие. — СПб: НИУ ИТМО, 2013. — 72 с.

