Ключевые слова: обработка естественного языка, компьютерная лингвистика, интеллектуальный анализ данных, модели векторизации слов.
Впоследние десятилетия разительно увеличились объемы накопленной текстовой информации и возросли потребности практической реализации эффективных средствах ее анализа. При этом наибольший прирост наблюдается в области научно-технических данных. С целью структурирования массивов текстовых документов и сокращения информационной нагрузки на пользователя возобновились работы по созданию алгоритма классификации текстовых данных, способного обеспечивать высокоточную классификацию документов по заданным классам. Немаловажную роль здесь играет выбор оптимальной модели векторного представления слов. Несмотря на интенсификацию работ в этом направлении, попытки создать универсальные методы обработки документов не увенчались успехом, ведь результаты классификации во многом зависят от конкретной задачи, в частности, объема обучающих выборок, количества классов, размера текстов, предметной области.
Изучение и сравнительный анализ существующих моделей векторного представления данных представляют собой достаточно сложную задачу, поскольку результат напрямую зависит от количества и качества входного потока данных. Текстовая информация поступает на многих языках, с использованием различных стилей изложения материала.
- Формализация задачи. Текстовая классификация — это отнесение текстовых документов к одной или нескольким заранее заданным категориям (классам, рубрикам) по определенным признакам [1]. Существует набор размеченных данных, содержащий 10000 записей о научных исследованиях с охватом всех мировых журналов. Для обучения и тестовых испытаний модели классификатора необходимо перевести текстовое содержимое в числовой вектор признаков.
- Обзор моделей векторного представления. Вданном разделе приводится обзор некоторых алгоритмов для построения распределенных векторных представлений слов естественного языка с учетом последних разработок в данном направлении.
Данные методы базируются на дистрибутивной гипотезе, которая утверждает, что лингвистические единицы, встречающиеся в схожих контекстах, имеют близкие значения [2].
Word2Vec: В данной модели для получения хороших векторов используется машинное обучение. Одним из популярных методов является построение искусственных нейронных сетей. Изначально задается размерность векторов, которые заполняются случайными величинами. Во время обучения вектор каждого слова будет максимально схож с векторами типичных соседей, и максимально отличаться от векторов слов, которые соседями данному слову не являются. Но и здесь не все так гладко, при обучении нейронных сетей требуется очень много времени и огромные вычислительные затраты.
В 2013 Tomas Mikolov вместе с соавторами опубликовал статью «Efficient Estimation of Word Representations in Vector Space» [3], а позже выложил код утилиты Word2Vec, которая позволяет тренировать нейронные языковые модели на больших словарях. Word2Vec обучается на порядок быстрее, чем нейронные языковые модели до него.
Каждому слову ставится в соответствие ровно один уникальный вектор (one-hot-encoding, биекция между лексиконом и входным слоем). Модель строит векторные представления в процессе прохода по словам входного корпуса скользящим окном и максимизации своей целевой функции. Авторы модели определяют размер скользящего окна
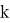
Основные свойства данных моделей:
– простая архитектура;
– устойчивость к входным данным;
– высокое качество выходных представлений;
– большое количество гиперпараметров.
На рис. 1 представлены архитектуры модели Word2Vec. Архитектура CBOW аналогична нейронной сети прямого распространения, где нелинейный скрытый слой удаляют, а проекция слоя является общей для всех слов, таким образом, все слова находятся в одинаковом положении. Задача архитектуры при обучении модели — предсказать слово по имеющемуся контексту.
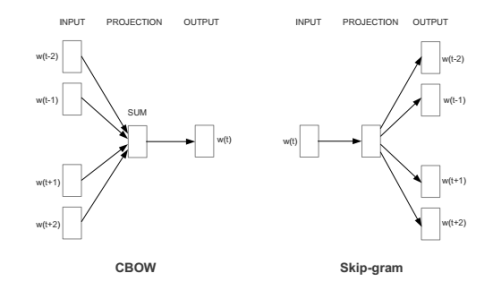
Рис. 1. Архитектуры модели Word2Vec: CBOW и Skip-gram
Далее приводится детальная характеристика CBOW и Skip-gram.
Continuous Bag-of-Words:
Continuous Bag-of-Words — предсказывает слово
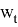
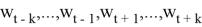
Обучение сети заключается в минимизации штрафной функции следующего вида:
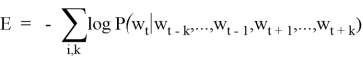
Архитектура представленной нейронной сети (рис. 2) состоит из 3-х полносвязных слоев, которые называются input, projection(hidden) и output слои соответственно. В синаптических весах input-слоя размера
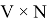
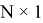
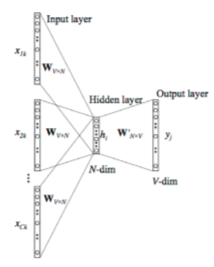
Рис. 2. Архитектура Continuous Bag-of-Words
Skip-gram
: вторая представленная модель называется Skipgram и отличается от ContinuousBag-of-Words тем, что предсказывает контекст
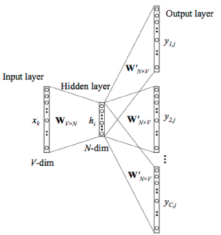
Рис. 3. Архитектура Skip-gram
Hidden-слой архитектуры нейронной сети представляет из себя копию строки input-слоя, которая соответствует рассматриваемому слову. Ключевое отличие в том, что слово
Выводы. Сравнительный анализ существующих моделей векторного представления помог выяснить, что в задаче тестовой классификации с учетом объема записей в наборе данных и различных приемов предварительной обработки оптимальным вариантом является модель Continuous Bag-of-Words.
Литература:
- Sebastiani, F. Machine learning in automated text categorization / F. Sebastiani. ACM Computing Surveys, 34 (1), 2002. — Pp. 1–47.
- Harris, Z. Distributional structure. 1954
- Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at International Conference on Learning Representations (ICLP) — 2013.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5–8, 2013, Lake Tahoe, Nevada, United States., pages 3111–3119.

