




Разработка программного продукта для определения авторства текста

Авторы: Обухова Алина Дмитриевна, Дроздова Ирина Игоревна
Рубрика: 1. Информатика и кибернетика
Опубликовано в
Дата публикации: 05.11.2017
Статья просмотрена: 200 раз
Библиографическое описание:
Обухова, А. Д. Разработка программного продукта для определения авторства текста / А. Д. Обухова, И. И. Дроздова. — Текст : непосредственный // Технические науки в России и за рубежом : материалы VII Междунар. науч. конф. (г. Москва, ноябрь 2017 г.). — Москва : Буки-Веди, 2017. — С. 34-39. — URL: https://moluch.ru/conf/tech/archive/286/13238/ (дата обращения: 26.04.2024).
В предыдущей работе нами были рассмотрены основные понятия и методики, необходимые для определения авторства текста. В данной статье описан алгоритм работы программного продукта, реализованного с целью идентификации автора анонимного документа, на основании данных, приведенных ранее, а также проведены исследования степени точности каждой из мер по определению авторства текста. Проведён сравнительный анализ зависимости качества идентификации создателя текста от его стилистической принадлежности.
Задача об определении авторства анонимного текста, в данном программном продукте, решается с помощью четырёх мер, описанных в предыдущей статье. Для вычисления каждой из них необходимы следующий параметры: частотный анализ по тексту (граммы, биграммы), общее количество символов в тексте, размерность алфавита. Эти параметры необходимы для текста анонимного автора и для библиотеки известных авторов.
Для построения библиотеки авторов предварительно были рассчитаны все необходимые параметры для каждого из них. Всего в библиотеке данного программного продукта представлено 16 авторов художественной литературы (был выбран 19–20 век русской литературы, в библиотеке представленные классические авторы), а также 8 текстов научного стиля. Частотные анализы по текстам этих авторов были подсчитаны заранее и хранятся в отдельных файлах, в корневой папке проекта.
В самом начале работы программы пользователю необходимо выбрать режим работы: определение автора анонимного текста или добавление в библиотеку ещё одного автора. Опишем работу каждого из этих режимов.
Для наилучшей работы данного программного продукта на первом этапе необходимо произвести предварительную обработку текста анонимного автора. Следует привести к одному регистру все буквы, исключить из текста все символы, не принадлежащие кириллическому алфавиту, числа и специальные знаки, кроме того, существует возможность удаления пробелов между словами. Рекомендуемыми параметрами для очистки входного текста являются: удаление сторонних символов, замена заглавных букв на строчные и наличие пробелов между словами. Однако, параметры очистки каждый пользователь может выбрать на своё усмотрение. Панель выбора представлена на рисунке 1.
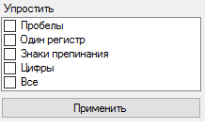
Рис. 1. Панель выбора предварительной обработки текста
Также в программе предусмотрено добавление нового автора к уже имеющимся или обновление текущей библиотеки. После нажатия данной кнопки пользователю необходимо указать, в какое литературное направление он желает добавить автора: научное или художественное. В каждом из этих разделов существуют идентичные функции: дополнение уже существующего автора, либо же добавление совершенного нового автора в библиотеку. При обновлении или дополнении сведений об уже известном авторе необходимо выбрать нужную фамилию в выпадающем списке и указать путь к файлу с новым текстом этого автора. После проведения этих действия этот документ допишется к уже существующему и проведётся новый частотный анализ, и данные будут обновлены.
Если же пользователь желает добавить нового автора, то ему необходимо указать его фамилию и путь к файлу с его произведением. По тексту этого автора будет проведён частотный анализ, новые файлы будут сохранены в корневом каталоге проекта, и он добавится в библиотечный список программы.
Для определения авторства текста по частотам биграмм прежде всего необходимо знать количество символов во входном документе. Это значение определяется на стадии считывания текста из файла. Также необходимо знать мощность алфавита, т. е. количество букв в алфавите. Изначально задаются массивы для хранения значений биграмм и количества их повторений в тексте. Опишем алгоритм работы.
Шаг 1. До начала общего цикла по всему тексту необходимо произвести сохранение значения первой пары букв текста в массив значений, а количество повторений данной биграммы задать равным 1.
Шаг 2. Организация общего цикла по всему тексту, начиная со второго элемента
Шаг 3. Если очередная пара (текущая и следующая за ней буква) присутствует в соответствующем массиве, то её количество увеличивается на 1, а алгоритм переходит на Шаг 2. Если же такой биграммы нет в массиве, то она сохраняется в нём, а её количество в необходимом массиве становится равным 1, алгоритм переходит на Шаг 2.
Алгоритм завершает свою работу, когда цикл дойдёт до последней пары букв.
Проводится сортировка по частоте биграмм, таким образом, чтобы самая часто встречающаяся биграмма стояла в массиве на первом месте.
Аналогичным образом происходит частотный анализ текста на основе грамм, только работа ведётся не с парами букв, а с каждой из них в отдельности.
Далее происходит подсчёт каждой из четырёх мер. Для их вычисления необходимы значения по текущему известному автору и анонимному. Значения биграмм и частотный анализ по анонимному тексту составляется один раз для одного текста, в соответствии с описанными выше алгоритмами.
Далее организуется цикл по всем имеющимся известным авторам и проводится подсчёт мер Хмелёва, дивергенции Кульбака и меры ![]() .
.
Шаг 1. Значения частотного анализа и значений биграмм текущего известного автора считываются из соответствующего файла и сохраняются в необходимый массив.
Шаг 2. Происходит поиск необходимой по алгоритму работы биграммы, её частоты и частотной характеристики необходимой одиночной буквы.
Шаг 3. Вычисление промежуточного значения каждой из мер и переход на Шаг 2.
Шаг 4. После подсчёта конечного значения мер происходит сравнение значения текущей меры и минимального значения. Если текущее значение меньше минимального, то необходимо переприсвоить значения, а также сохранить фамилию известного автора, по которому производилось сравнение. Переход на Шаг 1 до тех пор, пока не будет произведено сравнение по всему списку известных авторов из базы данных программы.
Шаг 5. Вывод результатов атрибуции текста на экран.
Пример изображен на рисунке 2.
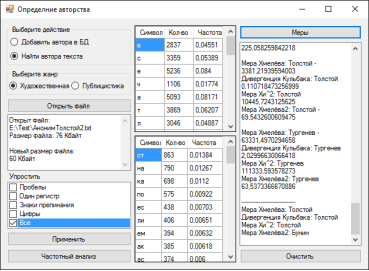
Рис. 2. Пример работы процедуры по определению авторства
Далее в работе представлены результаты экспериментов по выявлению эффективности работы методов определения авторов художественной и научной литературы различных размеров входного (анонимного) файла, а также разных объемов известных авторов, чьи тексты хранятся в базе данных программы.
Следует отметить, что на период написания данной статьи в базе данных программы находится 16 авторов художественной и 8 — научной литературы.
Проведём сравнительную оценку эффективности методов определения авторов художественной и научной стилистики. В качестве неизвестного автора художественной литературы для данного эксперимента был выбран Л. Н. Толстой, а среди научных — Роджер Пенроуз (английский академик, активно работающий в различных областях математики, общей теории относительности и квантовой теории).
В таблице 1 и на рисунке 3 представлены результаты сравнительного анализа по мере Хмелёва (с использованием частотам биграмм).
Таблица 1
|
Автор |
Размер анонимного текста |
|||||
|
25 Кб |
50 Кб |
75 Кб |
100 Кб |
125 Кб |
150 Кб |
|
|
Толстой |
4406 |
3732 |
3381 |
3046 |
2759 |
2732 |
|
Пенроуз |
4393 |
3879 |
3896 |
3614 |
3373 |
2940 |
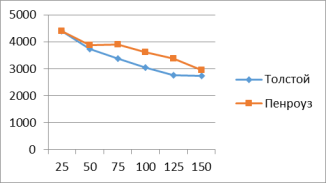
Рис. 3. График по результатам сравнительного анализа по мере Хмелёва
Значения данной меры Хмелёва с использованием биграмм становятся точнее с увеличением размера анонимного текста. В результате всех экспериментов с данной мерой был правильно определен истинный автор текста.
В таблице 2 и на рисунке 4 представлены результаты сравнительного анализа по второй мере Хмелёва (без использования биграмм).
Таблица 2
|
Автор |
Размер анонимного текста |
|||||
|
25 Кб |
50 Кб |
75 Кб |
100 Кб |
125 Кб |
150 Кб |
|
|
Толстой |
124 |
109 |
70 |
8 |
67 |
65 |
|
Пенроуз |
71 |
17 |
41 |
81 |
89 |
146 |
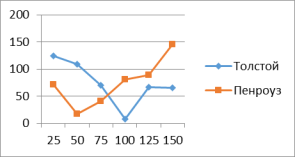
Рис. 4. График по результатам сравнительного анализа по мере Хмелёва
Нельзя не отметить тот факт, что данная мера весьма нестабильна в своих результатах и имеет очень низкий процент правильности определения автора (1 из 12 опытов).
В таблице 3 и на рисунке 5 представлены результаты сравнительного анализа по значениям дивергенции Кульбака.
Таблица 3
|
Автор |
Размер анонимного текста |
|||||
|
25 Кб |
50 Кб |
75 Кб |
100 Кб |
125 Кб |
150 Кб |
|
|
Толстой |
0,434 |
0,189 |
0,111 |
0,073 |
0,051 |
0,045 |
|
Пенроуз |
0,394 |
0,171 |
0,116 |
0,079 |
0,062 |
0,043 |
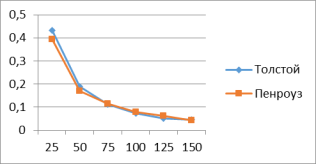
Рис. 5. График по результатам сравнительного анализа по дивергенции Кульбака
Значения дивергенции Кульбака становятся точнее при увеличении размера анонимного текста. В результате всех экспериментов с данной мерой был правильно определен автор текста.
В таблице 4 и на рисунке 6 представлены результаты сравнительного анализа по значениям меры Х2.
Таблица 4
|
Автор |
Размер анонимного текста |
|||||
|
25 Кб |
50 Кб |
75 Кб |
100 Кб |
125 Кб |
150 Кб |
|
|
Толстой |
32917 |
16458 |
10445 |
7607 |
5863 |
5035 |
|
Пенроуз |
23556 |
11441 |
7982 |
5759 |
4706 |
3638 |
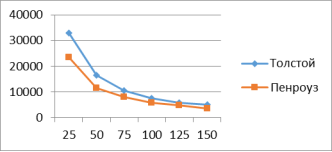
Рис. 6. График по результатам сравнительного анализа по мере Х2
Значения меры Х2 становятся точнее при увеличении размера анонимного текста. В результате всех экспериментов с данной мерой, кроме художественного текста размером 25Кб, был правильно определен автор текста.
На основе данных, полученных в результате сравнительного анализа в этой статье, можно сделать выводы о том, что все рассмотренные меры, кроме второй меры Хмелёва (без использования биграмм), обладают большой эффективностью на файлах размером от 25Кбайт. А также в значении мер нет значительной разницы в том, какой стиль использован для определения авторства: художественный или научно-популярный. Однако художественный все же имеет большую степень узнаваемости.
Литература:
- Романов, А. С. Методика и программный комплекс для идентификации автора неизвестного текста / А. С. Романов. — Томск, 2010. — 26 с.
- Поддубный, В. В. Классификация текстов по авторству с помощью метода Хмелева и его модификаций / В. В. Поддубный, О. Г. Шевелев; Материалы X Всероссийской научно-практической конференции ч. 1. — Томск: ТГУ, 2006. — С. 175–177.
- Хмелев, Д. В. Распознавание автора текста с использованием цепей А. А. Маркова / Д. В. Хмелев. — Москва: Вестник МГУ. Сер. 9: Филология. 2000. — С. 115–126.
- Кукушкина, О. В. Определение авторства текста с использованием буквенной и грамматической информации // Проблемы передачи информации / О. В. Кукушкина, А. А. Поликарпов, Д. В. Хмелев. 2001. Т. 37. Вып. 2. С. 96–109.
- Мощенкова, Д. С. Обзор программных продуктов, разработанных для атрибуции художественных текстов / Мощенкова Д. С., Кривицкая Д. А., Амосова Н. С. — Молодежь и наука: сборник материалов Х Юбилейной Всероссийской научно-технической конференции студентов, аспирантов и молодых ученых с международным участием, посвященной 80-летию образования Красноярского края. 2014. — 3 с.
Похожие статьи
Определение авторства текста по частотным характеристикам
анонимный текст, автор, авторство текста, текст, система, мера, математическая статистика, атрибуция текстов, анализируемый текст, теория вероятностей.
Сравнение методов оценки тональности текста | Статья...
Ключевые слова:классификация текста, машинное обучение, обработка естественного языка, тональность текста. Анализ мнений — это тип обработки естественного языка для отслеживания настроения общественности о конкретном продукте.
Анализ тональности отзывов пользователей в мета-области...
Анализ тональности текста — это раздел интеллектуального анализа данных, направленный на выявление.
Сравнительный анализ методов синтеза речи | Статья в журнале... Вопрос — ответ. Отзывы и защиты наших авторов.
Сравнительный анализ публикационной активности ИрГУПС...
Автор: Черная Елизавета Кирилловна.
Теперь на основе данных взятых из РИНЦа произведем построение и анализ по трем университетам
Программный продукт MS Excel позволяет построить следующие виды регрессии
Анализ методов тематического моделирования текстов на...
Наиболее популярным направлением извлечения информации из текстов на данный момент является использование различных статистических методов для
Вероятностный латентно-семантический анализ — это статистический метод анализа корреляций двух типов данных.
Использование прогнозной аналитики...
Методы интеллектуального анализа данных. Автор: Певченко Светлана Сергеевна.
Программное обеспечение многомерного статистического анализа.
Сравнительный анализ алгоритмов нейронной сети и деревьев принятия решений модели интеллектуального анализа...
Применение методов text mining для классификации информации...
Определение авторства текста по частотным характеристикам.
Анализ тональности текста — это сложный процесс, касающийся выделение полезной субъективной информации из текста.
На основе всех этих данных исходный текст последовательно, предложение за.
Сравнительный анализ методов представления информации...
Результаты сравнительного анализа представлены в таблице 1. Таблица 1. Сравнительный анализ адаптивного сайта имобильного приложения.
Бизнес-журнал, 2014/06 — Тюменская область. [Текст]. —
Обзор систем анализа тональности текста на русском языке
Анализ тональности текста позволяет извлекать из текста эмоционально окрашенную лексику и эмоциональное отношение авторов по отношению к объектам, о которых идет речь в тексте.
Похожие статьи
Определение авторства текста по частотным характеристикам
анонимный текст, автор, авторство текста, текст, система, мера, математическая статистика, атрибуция текстов, анализируемый текст, теория вероятностей.
Сравнение методов оценки тональности текста | Статья...
Ключевые слова:классификация текста, машинное обучение, обработка естественного языка, тональность текста. Анализ мнений — это тип обработки естественного языка для отслеживания настроения общественности о конкретном продукте.
Анализ тональности отзывов пользователей в мета-области...
Анализ тональности текста — это раздел интеллектуального анализа данных, направленный на выявление.
Сравнительный анализ методов синтеза речи | Статья в журнале... Вопрос — ответ. Отзывы и защиты наших авторов.
Сравнительный анализ публикационной активности ИрГУПС...
Автор: Черная Елизавета Кирилловна.
Теперь на основе данных взятых из РИНЦа произведем построение и анализ по трем университетам
Программный продукт MS Excel позволяет построить следующие виды регрессии
Анализ методов тематического моделирования текстов на...
Наиболее популярным направлением извлечения информации из текстов на данный момент является использование различных статистических методов для
Вероятностный латентно-семантический анализ — это статистический метод анализа корреляций двух типов данных.
Использование прогнозной аналитики...
Методы интеллектуального анализа данных. Автор: Певченко Светлана Сергеевна.
Программное обеспечение многомерного статистического анализа.
Сравнительный анализ алгоритмов нейронной сети и деревьев принятия решений модели интеллектуального анализа...
Применение методов text mining для классификации информации...
Определение авторства текста по частотным характеристикам.
Анализ тональности текста — это сложный процесс, касающийся выделение полезной субъективной информации из текста.
На основе всех этих данных исходный текст последовательно, предложение за.
Сравнительный анализ методов представления информации...
Результаты сравнительного анализа представлены в таблице 1. Таблица 1. Сравнительный анализ адаптивного сайта имобильного приложения.
Бизнес-журнал, 2014/06 — Тюменская область. [Текст]. —
Обзор систем анализа тональности текста на русском языке
Анализ тональности текста позволяет извлекать из текста эмоционально окрашенную лексику и эмоциональное отношение авторов по отношению к объектам, о которых идет речь в тексте.




