Введение
Автоматическая оценка кратких развернутых ответов относится к направлению автоматизированного оценивания кратких ответов. В общем виде задача состоит в том, чтобы по тексту ответа определить, насколько он соответствует ожидаемому содержанию и может ли быть оценен близко к экспертной проверке [1, с. 43]. Интерес к таким методам связан с тем, что образовательные системы всё чаще используют не только закрытые вопросы, но и задания, в которых студент должен самостоятельно сформулировать объяснение. Это особенно заметно при обучении программированию: студенту важно не просто выбрать правильный термин, а показать понимание области видимости переменных, типов данных, особенностей сравнения, замыканий и других базовых понятий.
Обычная автоматическая проверка хорошо работает там, где есть однозначный результат: например, выполненный код или выбранный вариант ответа. Но краткий текстовый ответ по программированию находится между тестом и полноценным эссе. Он короткий, но смысловая плотность высокая. В одном предложении студент может дать полностью правильное объяснение, а может использовать похожие слова, но пропустить ключевой критерий. Поэтому простое совпадение слов с эталоном не является надежным решением.
Развитие моделей семейства BERT сделало возможным переход от лексического сравнения к сравнению смысловых представлений текста. Для русскоязычных задач важны модели, адаптированные к русским текстам и способные формировать векторные представления предложений [6, с. 46]. Однако прямое применение таких моделей не всегда достаточно: высокая семантическая близость ещё не означает правильную педагогическую оценку. Поэтому в данной работе сравниваются два варианта: прямое оценивание через близость эмбеддингов и ансамблевое оценивание, где несколько моделей используются как признаки для регрессионной модели.
Материалы исследования
Экспериментальный набор был составлен для темы JavaScript. В него вошли 10 вопросов: от базовых понятий переменной, типов данных и функций до более сложных тем, таких как hoisting, строгий режим, IEEE 754, замыкания и различие между == и ===. На каждый вопрос было подготовлено по 50 реальных студенческих ответов, всего 500 наблюдений. Важно отметить, что ответы не являлись синтетически сгенерированными: они отражали типичные формулировки, ошибки, неполные объяснения и разные уровни понимания материала, характерные для студентов при ответе в свободной форме. Каждый ответ сопоставлялся с эталонным ответом и имел экспертную оценку по шкале 0–4, где 0 соответствует неверному или фактически отсутствующему ответу, а 4 — полному и корректному раскрытию вопроса.
Набор получился достаточно удобным для первого эксперимента: число ответов одинаковое для каждого вопроса, поэтому отдельная тема не доминирует над другими. При этом распределение оценок не является полностью равномерным: больше всего ответов получили 3 и 4 балла, но в выборке также присутствуют нулевые, неполные и частично правильные ответы. Это важно, потому что модель должна различать не только явно неверные и явно правильные формулировки, но и промежуточные варианты.
Таблица 1
Основные характеристики экспериментального набора
|
Параметр |
Значение |
|
Предметная область |
основы JavaScript |
|
Количество вопросов |
10 |
|
Количество ответов |
500 |
|
Ответов на один вопрос |
50 |
|
Шкала экспертной оценки |
0–4 балла |
|
Средняя длина ответа |
75,7 символа |
|
Медианная длина ответа |
67 символов |
Методика сравнения прямых и ансамблевых подходов
В прямом подходе эталонный ответ и ответ студента кодируются одной и той же языковой моделью. После этого между двумя векторами вычисляется косинусная близость, которая затем приводится к шкале 0–4. Такой подход прост, не требует дополнительного обучения на экспертных оценках и может быстро использоваться как базовая линия. Подобная логика сравнения эталонного и студенческого ответа через векторные представления и косинусное сходство применяется в работах по автоматизированному оцениванию коротких ответов [2, с. 282]. В исследовании прямое оценивание применялось к трем BERT-подобным моделям: DistilBERT, RoBERTa и RuBERT.
DistilBERT был выбран как компактный многоязычный вариант BERT-модели, ориентированный на более быстрый вывод. RoBERTa использовалась как сильная многоязычная модель для сопоставления текстов. RuBERT-tiny2 была включена как небольшая русскоязычная BERT-подобная модель, предназначенная в том числе для получения семантических векторных представлений текста на русском языке. Такой набор моделей позволяет сравнить многоязычные и русскоязычные представления, а также понять, насколько прямое сходство подходит для оценки ответов по программированию.
Ансамблирование в данной работе понимается как объединение результатов нескольких моделей для получения более устойчивой оценки. Были проверены два уровня ансамблей. Первый уровень — простые ансамбли: среднее значение трех оценок, медиана и взвешенное среднее. Среднее значение показывает общий результат трех моделей, медиана снижает влияние отдельной «ошибившейся» модели, а во взвешенном среднем больший вес получает модель, которая на обучающей части имеет меньшую ошибку. Второй уровень — стекинг: для каждого ответа формировался общий набор признаков из эмбеддингов эталонного и студенческого ответов, полученных тремя BERT-подобными моделями, а затем по этим признакам обучалась отдельная регрессионная модель. В качестве моделей второго уровня использовались Ridge-регрессия, SVR и LightGBM. Таким образом, ансамбль в эксперименте — это не еще одна языковая модель, а способ обучить метамодель связывать семантические признаки с экспертной шкалой 0–4.
Ridge-регрессия использовалась как линейный вариант стекинга с регуляризацией, позволяющий проверить, достаточно ли простой линейной комбинации признаков. SVR применялась как нелинейная регрессионная модель. LightGBM рассматривался как вариант градиентного бустинга над деревьями решений: такие методы последовательно строят ансамбль слабых моделей, исправляя ошибки предыдущих шагов и минимизируя итоговую ошибку [7, с. 1018]. В задачах автоматизированного оценивания также отмечается использование линейных, метрических и ансамблевых моделей, обучаемых на размеченных ответах и экспертных баллах [5, с. 21].
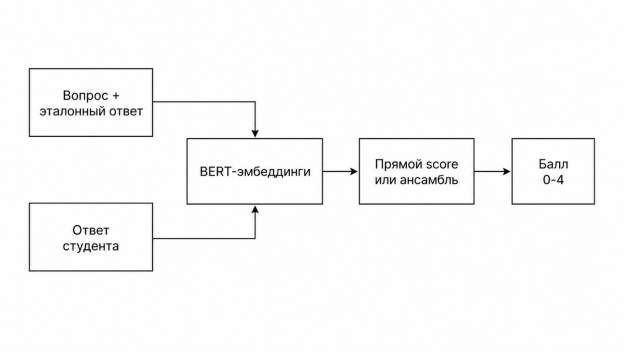
Рис. 1. Общая схема автоматической оценки ответа
Метрики и схема эксперимента
Качество оценивания измерялось несколькими метриками, так как одна метрика не показывает всю картину. В исследованиях автоматической оценки ответов используются как метрики ошибки, так и метрики согласованности с экспертными баллами [1, с. 45; 5, с. 21–22]. В данной работе экспертная оценка i-го ответа обозначалась как yᵢ, предсказание модели — как ŷᵢ, а количество ответов — как n. Pearson r показывает линейную связь между yᵢ и ŷᵢ: чем выше значение, тем лучше модель воспроизводит сами численные оценки эксперта. Spearman ρ оценивает не точные значения, а порядок ответов, то есть способность модели ранжировать ответы от слабых к сильным. MAE = (1/n)∑|yᵢ − ŷᵢ| показывает среднюю абсолютную ошибку в баллах и поэтому легко интерпретируется на шкале 0–4. RMSE = √((1/n)∑(yᵢ − ŷᵢ)²) сильнее штрафует крупные ошибки, что важно для выявления грубых промахов модели. R² показывает, какую долю вариации экспертных оценок объясняет модель. QWK (quadratic weighted kappa) отражает согласованность автоматической и экспертной оценки на порядковой шкале с учетом того, насколько сильно отличаются баллы. Accuracy ±1 показывает долю ответов, где ошибка модели не превышает одного балла, поэтому эта метрика особенно понятна для практического применения в учебной системе.
Именно такой набор метрик был выбран потому, что задача оценки кратких ответов является смешанной: с одной стороны, модель должна предсказывать численный балл, с другой — сохранять правильный порядок ответов и не допускать грубых расхождений с преподавателем. Поэтому MAE и RMSE показывают величину ошибки, Pearson r и Spearman ρ — связь с экспертной оценкой и ранжирование, R² — объясняющую способность модели, QWK — согласованность по шкале баллов, а Accuracy ±1 — практическую допустимость результата.
Для проверки устойчивости результатов были использованы три стратифицированных разбиения: 10 %, 20 % и 30 % тестовой выборки. Основным для интерпретации выбран вариант 30 %, так как в нем 150 ответов не участвовали в обучении и использовались только для проверки. Дополнительно для сложных ансамблей была проведена 5-кратная кросс-валидация. Перед обучением стекинг-моделей эмбеддинги стандартизировались, чтобы признаки разных моделей находились в сопоставимых масштабах.
Результаты эксперимента
На тестовой выборке 30 % лучший средний ранг показал ансамбль на основе LightGBM. Он занял первое место по метрикам R², QWK, Accuracy ±1, MAE и RMSE, а по корреляционным метрикам уступил только ансамблю на основе SVR. Второе место по среднему рангу занял SVR-ансамбль. Среди одиночных моделей наилучший результат показала RuBERT-tiny2: она стала третьей по среднему рангу и заметно опередила прямые подходы на основе DistilBERT и RoBERTa. Это позволяет сделать вывод, что компактная русскоязычная модель лучше подходит для обработки коротких ответов на русском языке, однако наилучшее качество всё же достигается при использовании ансамблевого подхода с дополнительной калибровкой на экспертных оценках.
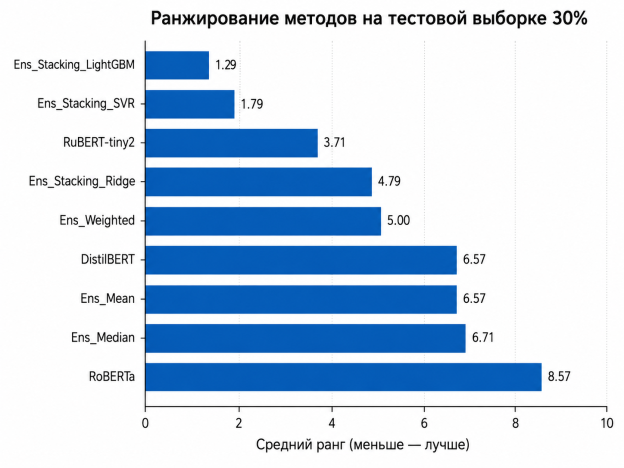
Рис. 2. Средний ранг методов на тестовой выборке 30 %
Таблица 2
Лучшие методы по результатам ранжирования на тестовой выборке 30 %
|
Место |
Метод |
Тип подхода |
Средний ранг |
|
1 |
Ens_Stacking_LightGBM |
ансамбль, стекинг |
1,29 |
|
2 |
Ens_Stacking_SVR |
ансамбль, стекинг |
1,79 |
|
3 |
RuBERT-tiny2 |
прямое оценивание |
3,71 |
|
4 |
Ens_Stacking_Ridge |
ансамбль, стекинг |
4,79 |
|
5 |
Ens_Weighted |
простой ансамбль |
5,00 |
Для лучшего метода на тесте 30 % были получены следующие значения: MAE = 0,7412, Pearson r = 0,7332, Accuracy ±1 = 0,70. Если учитывать шкалу 0–4, средняя абсолютная ошибка меньше одного балла является приемлемым результатом для первого варианта автоматического модуля, особенно если итоговая оценка не заменяет преподавателя полностью, а используется как предварительная рекомендация. Такой результат также показывает, что модель чаще ошибается в пределах соседней категории, а не делает грубые промахи.
Отдельно проверялась устойчивость сложных ансамблей. По MAE LightGBM и SVR оказались близкими: в 5-кратной кросс-валидации LightGBM получил MAE около 0,752, SVR — около 0,750. Однако на тестовой выборке 30 % LightGBM показал более высокий общий ранг, поэтому именно он был выбран как основной рабочий метод для дальнейшего внедрения в систему оценивания.
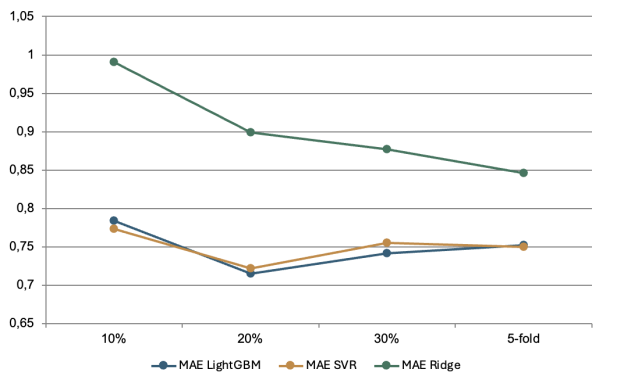
Рис. 3. Сравнение MAE сложных ансамблей на разных проверках
Обсуждение результатов
Полученные результаты можно объяснить особенностями самой задачи. Прямое сравнение эмбеддингов хорошо улавливает общую смысловую близость, но хуже различает педагогически важные детали. Например, ответ «let и var нужны для объявления переменных» будет близок к эталону по общей теме, но может не раскрывать блочную и функциональную область видимости, повторное объявление и hoisting. Для человека это частичный ответ, а для модели семантической близости он может выглядеть почти правильным.
Ансамбль решает эту проблему за счет калибровки на экспертных оценках. Он не просто измеряет близость двух текстов, а учится сопоставлять признаки с реальной шкалой 0–4. Важным является и то, что разные BERT-модели дают немного разные представления: DistilBERT лучше работает как быстрый общий базовый ориентир, RoBERTa дает многоязычное контекстное представление, RuBERT-tiny2 лучше ориентирована на русскоязычные формулировки. LightGBM может использовать эти различия и находить нелинейные сочетания признаков, поэтому по совокупности метрик он оказался устойчивее прямых подходов.
При этом результаты нельзя считать окончательным решением всей задачи автоматической проверки. Набор данных ограничен десятью вопросами по JavaScript, а ответы имеют относительно небольшой объем. Кроме того, шкала 0–4 зависит от того, насколько последовательно эксперт выставляет промежуточные баллы. Поэтому практическая система должна сохранять преподавателя в контуре: автоматическая оценка может предлагать предварительный балл, а подтвержденная или исправленная преподавателем оценка должна возвращаться в базу как новый обучающий пример.
Еще одно ограничение связано с предметной природой программирования. В коротких ответах важны не только общие смыслы, но и конкретные критерии: упоминание ключевого термина, правильное объяснение механизма, наличие примера, отсутствие фактической ошибки. Поэтому дальнейшее развитие подхода целесообразно связывать не только с увеличением обучающей выборки, но и с добавлением предметных признаков: выделением терминов JavaScript, проверкой обязательных смысловых компонентов и анализом типичных ошибок.
Заключение
В статье было проведено сравнение прямых и ансамблевых подходов к автоматической оценке кратких развернутых ответов по программированию. Эксперимент на 500 ответах по JavaScript показал, что прямое сравнение BERT-эмбеддингов может использоваться как базовый метод и как источник признаков, но само по себе недостаточно надежно для выставления итогового балла. Лучшим одиночным вариантом стала RuBERT-tiny2, что логично для русскоязычных коротких ответов.
Наиболее качественный результат был получен при использовании ансамблевого подхода со стекингом. LightGBM-ансамбль на тестовой выборке 30 % показал MAE = 0,7412, Pearson r = 0,7332 и Accuracy ±1 = 0,70. Это подтверждает, что для практической системы проверки ответов целесообразно использовать не одну языковую модель напрямую, а ансамбль, обученный на экспертных оценках. Такой подход лучше соответствует реальной образовательной задаче, где важно не только найти похожий текст, но и поставить балл, близкий к преподавательскому.
Практическая значимость исследования заключается в том, что выбранный метод может быть использован как основа модуля автоматической проверки в системе тестирования студентов. При этом наиболее безопасный сценарий внедрения — не полная замена преподавателя, а предварительная автоматическая оценка с последующим подтверждением и накоплением новых размеченных примеров.
Литература:
- Лагутина, Н. С. Обзор моделей автоматической оценки сходства ответа учащегося с эталонным ответом / Н. С. Лагутина, К. В. Лагутина. — Текст: непосредственный // Моделирование и анализ информационных систем. — 2025. — Т. 32, № 1. — С. 42–65.
- Миннегалиева, Ч. Б. Автоматизированное оценивание коротких ответов обучающихся с использованием языковых моделей / Ч. Б. Миннегалиева, И. И. Кашапов, О. Д. Морозова. — Текст: непосредственный // Электронные библиотеки. — 2024. — Т. 27, № 3. — С. 278–293.
- Кожевников, В. А. Система автоматической проверки ответов на открытые вопросы на русском языке / В. А. Кожевников, О. Ю. Сабинин. — Текст: непосредственный // Научно-технические ведомости СПбГПУ. Информатика. Телекоммуникации. Управление. — 2018. — Т. 11, № 3. — С. 57–72.
- Автоматизация проверки семантической составляющей текстовых ответов обучающихся в цифровой образовательной платформе / А. Г. Леонов, Н. С. Мартынов, К. А. Мащенко [и др.]. — Текст: непосредственный // Программные продукты и системы. — 2024. — Т. 37, № 3. — С. 440–452.
- Новые подходы к оцениванию: искусственный интеллект как драйвер изменений в образовании / Е. Ю. Карданова (науч. ред.), С. В. Тарасов, А. Е. Иванова, Э. М. Юсупова [и др.]. — Текст: непосредственный. — М.: НИУ ВШЭ, Институт образования, 2025. — 89 с. — (Современная аналитика образования; вып. № 5 (88)).
- Олисеенко, В. Д. Эмбеддинги языковой модели RuBERT в задаче многоклассовой классификации постов пользователей в социальной сети / В. Д. Олисеенко, М. В. Абрамов. — Текст: непосредственный // XXV Международная конференция по мягким вычислениям и измерениям: сборник материалов. — СПб.: Издательство СПбГЭТУ «ЛЭТИ», 2022. — С. 45–48.
- Салахутдинова, К. И. Алгоритм градиентного бустинга деревьев решений в задаче идентификации программного обеспечения / К. И. Салахутдинова, И. С. Лебедев, И. Е. Кривцова. — Текст: непосредственный // Научно-технический вестник информационных технологий, механики и оптики. — 2018. — Т. 18, № 6. — С. 1016–1022.

