Ключевые слова: анализ тональности текста, анализ данных, векторное представление слов, машинное обучение, глубокое обучение
Введение
Подобного рода исследования в последнее время пользуются большим спросом. Изначально для реализации анализа негативных отзывов необходимо провести классификацию отзывов, что приводит нас в сферу сентиментального анализа, который находится в области NLP. Обработка естественного языка (Natural Language Processing, NLP) изучает проблемы, связанные с синтезом естественных языков.
В последние годы в данной области семантическому анализу уделяется много внимания из-за возможности его применения в различных областях — от бизнеса до политических исследований. Благодаря этому инструменту компании могут отслеживать репутацию своего бренда. Анализируя отзывы в социальных сетях, можно судить об их отношении к интересующему нас продукту.
В современных реалиях одной из популярных платформ пользователей интернета для высказывания своего мнения является Твиттер. В данной социальной сети люди открыто и свободно обсуждают происходящие с ними события, говоря о том, что им нравится или не нравится. Популярность Твиттера, влияние, которое пользователи оказывают своими высказываниями, доступность данных привлекают исследователей и ведет к постановке различных задач.
Постановка задачи
Таким образом, целью данной работы является проведение анализа и выявление причин возникновения отрицательной тональности в коротких негативных высказываниях социальной сети Twitter для улучшения качества товара или предоставляемых услуг.
Для достижения цели были поставлены следующие задачи :
− Рассмотреть наиболее популярные методы классификации тональности;
− Разработать классификатор тональностей;
− Произвести анализ негативных твитов и представить полученные результаты с помощью графических интерпретаций;
В качестве входных данных использовались общедоступные отзывы пользователей американских авиалиний о качестве полетов [1].
Данные были собраны из социальной сети Twitter за февраль 2015 года. Язык используемых твитов английский. Корпус данных был поделен на обучающую и тестовую выборки в соотношении 70 %-30 %. Классификация производилась на 3 класса: негативные, нейтральные и положительные.
Полученные тексты отзывов были подвергнуты препроцессингу: были удалены специальные символы, цифры и стоп-слова, было произведено приведение к нижнему регистру.
Для реализации алгоритмов использовался следующий стек технологий: основной язык для реализации Python 3, библиотеки Numpy, Pandas Keras, Matplolib. Для разработки использовались Jupyter Notebook и Google Colab.
Наивный Байесовский классификатор
Первым классификатором, который был реализован в данной работе, является — Наивный Байесовский. В его основе лежит одноимённая теорема.
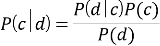
где
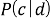
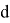
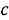
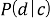
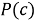

Для определения класса с наибольшей вероятностью появления Байесовский классификатор использует оценку апостериорного максимума.
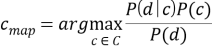
Классификатор называется наивным ввиду того факта, что документ представляется как набор условно независящих друг от друга вероятностей. Исходя из этого предположения условная вероятность документа аппроксимируется произведением условных вероятностей всех слов входящих в документ.
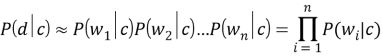
Полученные значения метрик представлены в таблице 1.
Таблица 1
|
Accuracy |
Precision |
Recall |
|
0.7521 |
0.7516 |
0.9205 |
LSTM
Long Short-Term Memory это разновидность архитектуры рекуррентных нейронных сетей.
В сети LSTM элементом является не один нейрон, а ячейка или модуль. Модуль состоит из нескольких слоёв, которые комбинируются посредством поэлементного умножения или сложения. На рисунке 1 продемонстрирован повторяющийся модуль сети.
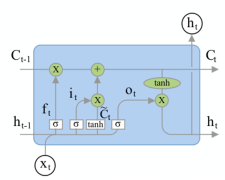
Рис. 1: Пример повторяющегося модуля LSTM
Ключевым для LSTM является состояние ячейки
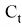
В сетях LSTM используются 3 вида гейтов:
− Гейт забвения (forget gate)
− Входной гейт (input gate)
− Выходной гейт (output gate)
Подробный принцип работы сети описан в работе Хохрейтера [2]. Существуют и более популярные схемы, например описанная Джерсом и Шмидхубером [3], где состояние ячейки также подается на каждый
Была реализована сеть, состоящая из слоев векторных представлений слов, LSTM-слоя, содержащего 10 ячеек, и выходного слоя c функцией активации Softmax.
В модуле в качестве функции активации используется гиперболический тангенс, а в качестве функции, используемой для активации повторного шага — сигмоид.
Количество эпох — 4
Ниже приведены таблицы 2 и 3 значений метрик в зависимости от размера батча обучения и словаря.
Таблица 2
|
loss |
Accuracy |
Recall |
Precision | |
|
Batch = 32 |
0.5059 |
0.7999 |
0.6302 |
0.8233 |
|
Batch = 25 |
0.4540 |
0.8209 |
0.7135 |
0.8270 |
|
Batch = 15 |
0.4180 |
0.8312 |
0.7437 |
0.8328 |
|
Batch = 5 |
0.3819 |
0.8472 |
0.7611 |
0.8345 |
Таблица 3
|
loss |
Accuracy |
Recall |
Precision | |
|
Voc_size=500 |
0.4917 |
0.8049 |
0.8511 |
0.8511 |
|
Voc_size=750 |
0.4729 |
0.8167 |
0.8454 |
0.8635 |
|
Voc_size=1000 |
0.4391 |
0.8317 |
0.8544 |
0.8676 |
Можно заметить, что LSTM дает неплохие результаты, но несильно опережает Наивный Байесовский классификатор.
BERT
BERT состоит из стека энкодеров Трансформера, специальной модели, использующей механизм внимания [5].
BERT — первая нейросеть, которая успешно использует двунаправленный подход для решения задачи представления слов и целых предложений в n-мерном пространстве с учётом контекста [6]. Обычно для решения этой задачи сеть обучают предсказывать слово по заданной последовательности. Двунаправленный подход позволяет учесть влияние каждого слова на контекст, но создаёт дополнительные проблемы, для борьбы с которыми BERT обучают решать задачи Masked Language Modeling.
В ходе решения этой проблемы сеть представляет слова в векторной форме. Это и является основной целью работы нейросети. Эмбеддинги затем применяются для решения различных задач с использованием техники fine-tuning.
Google предоставляет несколько предобученных моделей.
Для поставленной задачи была использована модель BERT-Base, нечувствительная к регистру, имеющая 12 слоев, 768 узлов, и с 12 attention heads. К выходному слою BERT был добавлен еще один слой c функцией активации — softmax и 3 выходами — для негативных, нейтральных и позитивных твитов. Для того, чтобы избежать переобучения в архитектуре сети также используется dropout-слой. Размер бэтча равен 32. Количество эпох — 3.
Полученные значения метрик указаны в таблице 4.
Таблица 4
|
Accuracy |
Precision |
Recall |
F1-мера |
|
0,92739 |
0.89134 |
0.92546 |
0.90808 |
Как видно из таблицы, BERT является очень мощным инструментов для решения задач NLP. Именно данные тех твитов, которые были классифицированы им, как «отрицательные» будут подвергнуты анализу в дальнейшей главе.
Анализ негативных твитов
После классификация твиты были подвергнуты процедуре анализа.
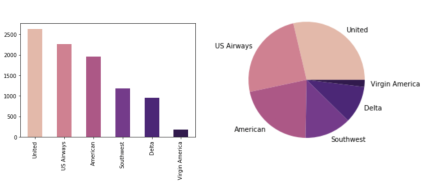
Рис. 2: Гистограмма и Круговая диаграмма, отражающие количество негативных отзывов, которые получили авиакомпании
На рисунке 2 представлены графики, отражающие количество негативных отзывов с разбивкой по авиакомпаниям. Эти данные нерепрезентативны из-за разного количества рейсов, совершаемых компаниями, поэтому было принято решение рассмотреть процентные соотношения твитов разной тональности.
Как видно из приведенных таблицы и гистограммы на рисунке 3 пользователи были больше недовольны перевозками компании “US Airways”.
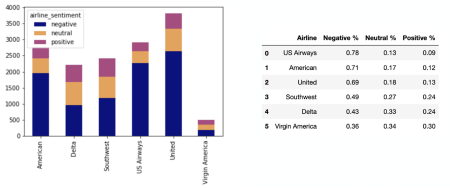
Рис. 3: Гистограмма и таблица, отражающие соотношение твитов разных тональностей для авиакомпаний
Важным для компании является мониторинг лидеров мнений. Те причины, которые выделяют подобные пользователи могут быть ключевыми негативными качествами, которые следует упразднить. За лидеров мнений приняты те пользователи, отзывы которых получили наибольшее количество ретвитов.
Список лидеров для компании United и твит, получивший наибольший отклик, представлены на рисунке 4.

Рис. 4. Топ-5 лидеров мнений для компании «United»
Одним из самых простых и эффективных способов репрезентации ключевых слов является Облако Слов.
Так выглядит облако слов, в котором использовались слова из отзывов всех авиакомпаний. Можно сделать вывод, что основными проблемами пользователи признают утерю багажа и отмененные рейсы.

Рис. 5: Облако слов, часто встречаемых в негативных отзывах для всех авиакомпаний
Отрицательные твиты были также проанализированы с разбивкой по штатам. Выделив самые проблемные штаты, можно точечно решить проблему, что улучшит рейтинг компании. Можно заметить, что такие штаты, как Аляска, Монтана и Вайоминг остались недовольны работой авиакомпаний.
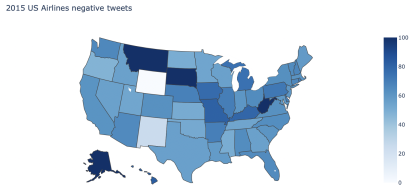
Рис. 6: Визуализация процентного соотношения отрицательных твитов по штатам
Заключение
В процессе работы были изучены принципы векторного представления слов, популярные модели классификаторов. Проанализированы их возможности, недостатки, потенциальные сферы применения.
В отношении BERT можно с уверенностью сказать, что модель показывает впечатляющие результаты. Особенности архитектуры выделяют её среди существующих нейросетей.
Был проведен анализ негативно классифицированных твитов, результаты которого потенциально могут помочь авиаперевозчикам улучшить качество сервиса.
В дальнейшем планируется представить полученные благодаря анализу данные в виде приложения для компаний. В данном приложении имелась бы, как и ранее приведенная инфографика, так и новые данные, например, процентные соотношения отзывов, полученных от пользователей разных полов, возрастов, отображение графов взаимосвязей между пользователями. Так же хотелось бы добавить возможность компании самой выбирать, твиты с какой тональностью она хочет отслеживать для мониторинга положительных качеств своих конкурентов.
Литература:
- Датасет Twitter US Airline Sentiment // Kaggle сайт. — URL: https://www.kaggle.com/crowdflower/twitter-airline-sentiment
- S. Hochreiter S., Schmidhuver J Long Shor-Term Memory // ResearchGate [Электронный ресурс]. — URL: https://www.researchgate.net/publication/13853244_Long_Short-term_Memory — Текст: электронный.
- Gers F. A., Schmidhuber J. Recurrent Nets that Time and Count Difficult // IEEE [Электронный ресурс]. — URL: https://ieeexplore.ieee.org/document/861302 — Текст: электронный.
- Cho K., van Merrlenboer B., Bougares F., Shwenk H., Bahdanau D., Bengio Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation // arXiv [Электронный ресурс]. — URL: https://arxiv.org/abs/1406.1078 — Текст: электронный.
- Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A. N., Kaiser L., Polosukhin I., Attention Is All You Need // // arXiv [Электронный ресурс]. — URL: https://arxiv.org/abs/1706.03762 — Текст: электронный.
- Devlin J., Chang M., Lee K., Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding // arXiv [Электронный ресурс]. — URL: https://arxiv.org/pdf/1810.04805.pdf — Текст: электронный.

