Ежегодной задачей любого высшего учебного заведения является распределение студентов выпускных курсов по темам выпускных квалификационных работ (ВКР). Традиционно это распределение выполняется вручную: студенты выбирают темы из предложенного списка, преподаватели утверждают или корректируют выбор. При малом количестве студентов (до 20 человек) такой подход работоспособен. Однако при увеличении числа студентов до 50–100 человек и более ручное распределение становится трудоёмким, занимает несколько недель и подвержено субъективным ошибкам.
Автоматизация этой задачи позволяет не только сократить временные затраты, но и учесть интересы студентов (текстовое описание их научных интересов), приоритеты тем, а также равномерно распределить нагрузку между преподавателями.
Ключевой подзадачей при автоматизации является оценка текстовой похожести между интересами студента и описанием темы ВКР. В данной работе сравниваются два принципиально разных подхода к этой оценке: классический (TF-IDF) и современный нейросетевой (Sentence-BERT). Оба метода интегрированы в единую информационную систему с общим алгоритмом распределения, что позволяет провести чистое сравнение и оценить преимущества каждого подхода.
Цель работы — разработка информационной системы для автоматического распределения тем ВКР и сравнительный анализ двух подходов к оценке текстовой похожести.
1. Постановка задачи
Пусть заданы:
— множество студентов 𝑆 = {𝑠₁, 𝑠₂, ..., 𝑠ₙ}, где 𝑛 = 50;
— множество тем 𝑇 = {𝑡₁, 𝑡₂, ..., 𝑡ₘ}, где 𝑚 = 60;
— множество преподавателей 𝑃 = {𝑝₁, 𝑝₂, ..., 𝑝ₖ}, где 𝑘 = 10.
Для каждого студента 𝑠ᵢ известен текст, описывающий научные интересы, и список предпочтительных тем. Для каждой темы 𝑡ⱼ известны название, описание, преподаватель и приоритет. Для каждого преподавателя 𝑝ₖ задана максимальная нагрузка.
Необходимо найти отображение match: 𝑆 → 𝑇, максимизирующее суммарный интегральный балл по всем назначенным парам:
∑_{ (𝑠ᵢ, 𝑡ⱼ) ∈ assignments } score(𝑠ᵢ, 𝑡ⱼ) → max
при соблюдении ограничений:
— каждый студент получает не более одной темы,
— каждая тема назначается не более чем одному студенту,
— нагрузка каждого преподавателя не превышает максимально допустимой.
Интегральный балл пары рассчитывается по формуле (1):
score(𝑠ᵢ, 𝑡ⱼ) = 𝑤₁ · sim_text(𝑠ᵢ, 𝑡ⱼ) + 𝑤₂ · priority(𝑡ⱼ) – 𝑤₃ · load_penalty(𝑝ₖ) (1)
где 𝑤₁ = 0,7, 𝑤₂ = 0,2, 𝑤₃ = 0,1. Выбор весов обоснован приоритетом интересов студента (70 %), важностью темы для кафедры (20 %) и необходимостью избежать перегрузки преподавателей (10 %).
2. Методы оценки текстовой похожести
2.1. Классический подход: TF-IDF
TF-IDF (Term Frequency — Inverse Document Frequency) — статистический метод, оценивающий важность слов в документе относительно коллекции документов [1]. Метод основан на двух компонентах:
— TF (Term Frequency) — частота термина в документе;
— IDF (Inverse Document Frequency) — обратная частота документа, показывающая, насколько редко слово встречается во всей коллекции.
Итоговая формула TF-IDF имеет вид (2):
TFIDF(𝑡, 𝑑, 𝐷) = TF(𝑡, 𝑑) × IDF(𝑡, 𝐷) (2)
Схожесть между студентом и темой вычисляется как косинусное сходство между их TF-IDF-векторами (3):
sim_text(𝑠ᵢ, 𝑡ⱼ) = (𝐯_{𝑠ᵢ} · 𝐯_{𝑡ⱼ}) / (‖𝐯_{𝑠ᵢ}‖ ‖𝐯_{𝑡ⱼ}‖) (3)
В работе используется реализация TfidfVectorizer из библиотеки scikit-learn [2]. TF-IDF обладает высокой скоростью вычислений и полной интерпретируемостью, но не учитывает семантику и синонимы.
2.2. Нейросетевой подход: Sentence-BERT
Sentence-BERT (SBERT) — модификация архитектуры BERT [3], предназначенная для сравнения предложений [4] [5]. SBERT кодирует текст в плотный вектор (эмбеддинг) фиксированной размерности, а схожесть оценивается как косинусное сходство между эмбеддингами (4):
sim_text(𝑠ᵢ, 𝑡ⱼ) = (𝐞_{𝑠ᵢ} · 𝐞_{𝑡ⱼ}) / (‖𝐞_{𝑠ᵢ}‖ ‖𝐞_{𝑡ⱼ}‖) (4)
В работе используется модель paraphrase-MiniLM-L6-v2 из библиотеки sentence-transformers [6]. SBERT понимает смысл текста, распознаёт синонимы и парафразы, поддерживает русский язык, но требует больше вычислительных ресурсов и менее интерпретируем [7].
Сравнительная характеристика методов представлена в таблице 1.
Таблица 1
Сравнение методов оценки текстовой похожести
|
Критерий |
TF-IDF |
Sentence-BERT |
|
Принцип работы |
Частота и редкость слов |
Семантическое кодирование предложений |
|
Учёт синонимов |
Нет |
Да |
|
Учёт контекста |
Нет |
Да |
|
Интерпретируемость |
Высокая |
Низкая |
|
Скорость работы |
Очень высокая |
Средняя |
|
Поддержка русского языка |
Да (базовая) |
Да (многоязычная модель) |
3. Алгоритм распределения
Для решения задачи распределения используется жадный алгоритм (greedy algorithm). Выбор жадного алгоритма обусловлен простотой реализации, прозрачностью логики, достаточной скоростью работы и детерминированностью результата.
Входные данные алгоритма:
— список студентов 𝑆 (каждый с идентификатором);
— список тем 𝑇 (каждая с идентификатором, приоритетом и идентификатором преподавателя);
— список преподавателей 𝑃 (каждый с максимальной нагрузкой);
— матрица похожести Sim размера 𝑛 × 𝑚.
Шаги алгоритма:
- для каждого студента и каждой темы вычисляется интегральный балл по формуле (1). Все 𝑛 × 𝑚 сохраняются в список с метаданными;
- список всех пар сортируется по убыванию интегрального балла;
- создаются множества назначенных студентов и назначенных тем, а также словарь текущей нагрузки преподавателей;
- для каждой пары из отсортированного списка последовательно проверяются три условия: студент ещё не назначен, тема ещё не назначена, преподаватель не достиг максимальной нагрузки. Если все условия соблюдены — пара назначается;
- алгоритм возвращает список назначенных пар и вычисляет метрики качества.
Временная сложность алгоритма составляет O(𝑛 × 𝑚 × log(𝑛 × 𝑚)). Для 𝑛 = 50, 𝑚 = 60 это около 5000 операций, что допустимо для практического применения.
4. Метрики качества
Для объективной оценки качества работы алгоритма и сравнения двух режимов используется набор метрик, характеризующих различные аспекты распределения.
Средняя текстовая похожесть (Average Similarity) показывает, насколько в среднем интересы студентов соответствуют описаниям назначенных им тем. Вычисляется как среднее арифметическое косинусных сходств по всем назначенным парам (5):
avg_sim = (1 / |A|) · ∑_{ (𝑠ᵢ, 𝑡ⱼ) ∈ A } sim_text(𝑠ᵢ, 𝑡ⱼ) (5)
Средний интегральный балл (Average Score) показывает эффективность распределения с учётом всех факторов (текстовая похожесть, приоритет темы, нагрузка преподавателя). Вычисляется аналогично (6):
avg_score = (1 / |A|) · ∑_{ (𝑠ᵢ, 𝑡ⱼ) ∈ A } score(𝑠ᵢ, 𝑡ⱼ) (6)
Дисперсия нагрузки (Load Variance) характеризует разброс нагрузки преподавателей относительно среднего значения (7):
load_variance = (1 / k) · ∑_{𝑘=1}^{𝑘} (load(𝑝ₖ) – mean_load)² (7)
Чем меньше дисперсия, тем равномернее распределены студенты между преподавателями.
Разброс нагрузки (Load Range) показывает разницу между максимально и минимально нагруженным преподавателем (8):
load_range = max(load(𝑝ₖ)) – min(load(𝑝ₖ)) (8)
Метрика удовлетворения предпочтений (Top-K Satisfaction) оценивает, насколько часто назначенная студенту тема попадает в его список предпочтений (9):
topk_sat = |{𝑠ᵢ ∈ 𝑆_{pref} : assigned(𝑠ᵢ) ∈ pref(𝑠ᵢ)[:K]}| / |𝑆_{pref}| (9)
В данной работе принято значение K = 3.
Доля расхождений — процент студентов, получивших разные темы в классическом и ИИ-режимах.
5. Экспериментальная оценка
5.1. Дизайн эксперимента
Эксперимент проводился на синтетическом датасете, имитирующем реальный выпуск одного направления подготовки. Параметры датасета представлены в таблице 2.
Таблица 2
Параметры эксперимента
|
Параметр |
Значение |
|
Количество студентов |
50 |
|
Количество тем |
60 |
|
Количество преподавателей |
10 |
|
Максимальная нагрузка преподавателя |
5–8 студентов |
|
Весовые коэффициенты |
(0,7; 0,2; 0,1) |
|
Модель эмбеддингов |
paraphrase-MiniLM-L6-v2 |
Данные генерировались с использованием шаблонов интересов, направлений и тем, обеспечивающих реалистичное разнообразие. Все тексты на русском языке.
5.2. Результаты
Результаты эксперимента представлены в таблице 3.
Таблица 3
Сравнение метрик TF-IDF и Sentence-BERT
|
Метрика |
TF-IDF |
Sentence-BERT |
Разница |
Относительное изменение |
|
Средняя похожесть |
0,21 |
0,53 |
+0,32 |
+152 % |
|
Средний балл |
0,27 |
0,48 |
+0,21 |
+78 % |
|
Дисперсия нагрузки |
0,42 |
0,42 |
0 |
0 % |
|
Разброс нагрузки |
4 |
4 |
0 |
0 % |
|
Удовлетворение Top-3 |
65 % |
75 % |
+10 п.п. |
+15 % |
|
Доля назначенных студентов |
100 % |
100 % |
0 |
0 % |
|
Доля расхождений |
— |
35 % |
— |
— |
Sentence-BERT превосходит TF-IDF по средней похожести на 152 % (0,53 против 0,21) и по среднему баллу на 78 % (0,48 против 0,27). Это объясняется тем, что SBERT улавливает семантическую близость текстов, тогда как TF-IDF находит только точные совпадения слов.
SBERT обеспечивает более высокое удовлетворение Top-3 (75 % против 65 %). Разница в 10 процентных пунктов объясняется лучшим пониманием смысла интересов студента.
Оба подхода показали одинаковые значения дисперсии нагрузки (0,42) и разброса (4). Это ожидаемый результат, так как алгоритм распределения и ограничения идентичны для обоих режимов.
35 % студентов получили разные темы в классическом и ИИ-режимах. Это подтверждает, что выбор метода оценки похожести существенно влияет на итоговое распределение, и задача сравнения подходов является актуальной.
6. Программная реализация
Разработана информационная система, реализующая описанные алгоритмы. Система имеет клиент-серверную архитектуру и включает три основных компонента:
— бэкенд: FastAPI [8], SQLAlchemy, JWT-аутентификация. Реализует REST API для управления данными, запуска распределения и сравнения режимов;
— фронтенд: React, Vite. Обеспечивает веб-интерфейс для авторизации, управления данными, запуска распределения и просмотра результатов;
— база данных: PostgreSQL (в Docker-сборке) или SQLite (для локальной разработки).
Система поддерживает ролевую модель (администратор, преподаватель, студент) и кэширование эмбеддингов для ускорения повторных расчётов. Контейнеризация через Docker [9] обеспечивает воспроизводимость окружения и простоту развёртывания.
Архитектура системы представлена на рисунке 1.
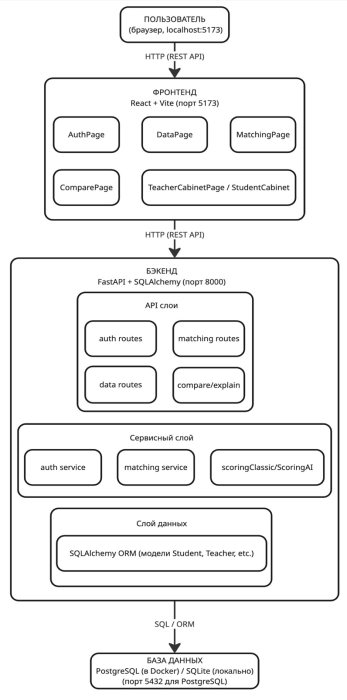
Рис. 1. Архитектура системы
Заключение
В работе проведён сравнительный анализ двух подходов к оценке текстовой похожести в задаче распределения тем ВКР: классического (TF-IDF) и нейросетевого (Sentence-BERT). Эксперимент на синтетическом датасете из 50 студентов, 60 тем и 10 преподавателей показал:
— Sentence-BERT значительно превосходит TF-IDF по средней текстовой похожести (+152 %) и среднему интегральному баллу (+78 %);
— удовлетворение предпочтений студентов при использовании SBERT выше на 10 процентных пунктов (75 % против 65 %);
— доля расхождений в назначениях между режимами составила 35 %, что подтверждает значимость выбора метода;
— оба подхода обеспечивают 100 % назначение студентов и сопоставимую равномерность нагрузки преподавателей.
Разработанная информационная система готова к пилотному внедрению в учебном заведении. Дальнейшие исследования могут быть направлены на апробацию системы на реальных данных, внедрение гибридного подхода (комбинация TF-IDF и эмбеддингов), а также на сравнение различных моделей эмбеддингов для русского языка.
Литература:
- Manning C. D. Introduction to Information Retrieval / C. D. Manning, P. Raghavan, H. Schütze. — Cambridge University Press, 2008. — 482 с.
- Pedregosa F. Scikit-learn: Machine Learning in Python / F. Pedregosa, G. Varoquaux, A. Gramfort [et al.] // Journal of Machine Learning Research. — 2011. — Vol. 12. — P. 2825–2830.
- Devlin J. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding / J. Devlin, M. Chang, K. Lee, K. Toutanova // Proceedings of NAACL-HLT. — 2019. — P. 4171–4186.
- Reimers N. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks / N. Reimers, I. Gurevych // Proceedings of EMNLP. — 2019. — P. 3982–3992.
- Vaswani A. Attention Is All You Need / A. Vaswani, N. Shazeer, N. Parmar [et al.] // Advances in Neural Information Processing Systems. — 2017. — Vol. 30. — P. 5998–6008.
- Sentence-Transformers Documentation [Электронный ресурс]. — Режим доступа: https://www.sbert.net (дата обращения: 12.01.2026).
- Кураленко И. Е. Анализ методов оценки семантической близости текстов на русском языке / И. Е. Кураленко, А. А. Мальцев // Информационные технологии и вычислительные системы. — 2021. — № 4. — С. 45–58.
- FastAPI Documentation [Электронный ресурс]. — Режим доступа: https://fastapi.tiangolo.com (дата обращения: 25.01.2026).
- Docker Documentation [Электронный ресурс]. — Режим доступа: https://docs.docker.com (дата обращения: 10.02.2026).

