Введение
Московский метрополитен [1] является одной из крупнейших систем городского пассажирского транспорта в мире: по данным оператора, в 2023 году суммарный пассажиропоток превысил 2,5 млрд поездок. Интенсивное расширение сети — за последнее десятилетие открыто более 50 новых станций — сопровождается нарастающей нагрузкой на инфраструктуру и повышением требований к качеству транспортного обслуживания.
Актуальность данного исследования обусловлена тем, что традиционные подходы к оценке качества перевозок — анкетирование, аудиторские проверки, анализ жалоб — обладают рядом существенных ограничений: высокой трудоёмкостью, субъективностью и значительным временным лагом между возникновением проблемы и её фиксацией. Альтернативой служит автоматизированная обработка открытых транспортных данных: портал открытых данных Правительства Москвы [2] предоставляет структурированные датасеты в формате GeoJSON через REST API, что открывает возможности для воспроизводимых и масштабируемых аналитических исследований. Методы машинного обучения — кластеризация, поиск аномалий, регрессионное прогнозирование — применяются в транспортных исследованиях всё активнее, однако работ, ориентированных на российские открытые порталы и квартальный горизонт анализа, практически нет.
Цель работы — исследовать подходы к сбору, предобработке и анализу открытых транспортных данных московского метрополитена и на их основе разработать инструментарий мониторинга качества пассажирских перевозок.
Для достижения поставленной цели решались следующие задачи:
— сбор данных через REST API портала data.mos.ru с поддержкой пагинации и локального кэширования;
— предобработка GeoJSON-ответов: преобразование в табличный формат, нормализация координат, расчёт производных показателей;
— разведочный анализ динамики и сезонности пассажиропотока на уровне сети, линий и отдельных станций;
— кластеризация станций по профилю нагрузки для выявления типовых транспортных функций;
— обнаружение статистически нетипичных периодов эксплуатации;
— построение и валидация модели краткосрочного прогнозирования пассажиропотока;
— геовизуализация результатов анализа.
1. Источники данных
1.1. Портал открытых данных Правительства Москвы
Правительство Москвы публикует транспортные данные на портале data.mos.ru в соответствии с принципами открытых государственных данных. Портал предоставляет доступ через REST API: все ответы возвращаются в формате GeoJSON FeatureCollection, что позволяет единообразно обрабатывать как атрибутивную, так и геометрическую информацию. Аутентификация осуществляется посредством ключа API, передаваемого в строке запроса. Пагинация реализована через параметры $top (размер страницы) и $skip (смещение); первый запрос выполняется без параметра $skip в соответствии с особенностью реализации API.
1.2. Используемые датасеты
В исследовании задействованы три датасета, характеристики которых приведены в таблице 1.
Таблица 1
Датасеты портала data.mos.ru, использованные в исследовании
|
№ Датасета |
Тип / Период |
Описание |
|
624 [3] |
Актуальные |
Вестибюли станций: координаты, режим работы, статус эскалаторов |
|
2278 [4] |
Актуальные |
Линии метрополитена: наименование, статус эксплуатации |
|
62743 [5] |
2021–2025, квартально |
Пассажиропоток по станциям: входящие / выходящие пассажиры, год, квартал, линия |
Датасет 62743 является основным источником для анализа: он содержит поквартальные сведения о входящем и исходящем пассажиропотоке в разбивке по каждой станции и линии метрополитена за период с 2021 по 2025 год. Датасет 624 (вестибюли) служит для получения географических координат станций, поскольку в основном датасете координаты не предусмотрены: за координату станции принимается среднее значение координат всех её вестибюлей. Датасет 2278 (линии) применяется для нормализации наименований линий и сопоставления с атрибутом Line основного датасета.
1.3. Программный стек сбора данных
Сбор данных реализован в виде функции, написанной на языке Python 3 [6] с использованием библиотеки requests. Функция поддерживает два режима: одностраничный (для небольших датасетов, укладывающихся в один ответ, например линии метро) и постраничный (для крупных датасетов с автоматическим перебором страниц до исчерпания результатов). Для минимизации обращений к серверу предусмотрено локальное кэширование в формате JSON: при повторном запуске данные читаются из файла, что обеспечивает воспроизводимость даже при отсутствии интернет-соединения. Между страничными запросами введена задержка 200 мс во избежание превышения допустимой частоты обращений к API.
2. Методология
2.1. Предобработка данных
На этапе предобработки GeoJSON-ответы API преобразуются в плоские таблицы (объекты pandas DataFrame): из каждого объекта Feature извлекается поле properties.Attributes, содержащее структурированные атрибуты. Координаты вестибюлей, хранящиеся в исходнике как строки с точкой в качестве десятичного разделителя, приводятся к числовому типу методом pd.to_numeric() с обработкой ошибок (errors='coerce'). Координаты станций вычисляются как среднее арифметическое координат всех вестибюлей соответствующей станции.
Для основного датасета пассажиропотока рассчитываются производные показатели: суммарный поток, показатель дисбаланса направлений и порядковый номер квартала (1–4). Поле Quarter преобразуется в упорядоченную категориальную переменную для корректной хронологической сортировки.
2.2. Применяемые методы машинного обучения
Сводный перечень применяемых аналитических методов представлен в таблице 2.
Таблица 2
Применяемые методы и инструменты
|
Задача |
Метод |
Реализация |
|
Разведочный анализ |
Статистические сводки, визуализации |
pandas, matplotlib, seaborn |
|
Типизация станций |
K-Means кластеризация (k = 4) |
sklearn.cluster.KMeans |
|
Обнаружение аномалий |
Z-score, Isolation Forest |
scipy.stats, sklearn.ensemble |
|
Прогнозирование потока |
Gradient Boosting Regressor |
sklearn.ensemble, lag-признаки |
|
Геовизуализация |
Точечная карта по координатам WGS-84 |
matplotlib |
Кластеризация методом K-Means [7] выполняется в пространстве четырёх признаков, рассчитанных на уровне станции: средний квартальный поток (avg_flow), коэффициент вариации потока (flow_cv), средний дисбаланс входа и выхода (avg_imbalance) и линейный тренд по годам (growth). Перед кластеризацией признаки стандартизируются (StandardScaler) для устранения масштабной несопоставимости. Оптимальное число кластеров определяется методом «локтя» по внутрикластерной сумме квадратов (inertia); по результатам анализа выбрано k = 4.
Для обнаружения аномалий применяются два независимых метода. Метод Z-оценки работает на уровне отдельной станции: для каждой записи вычисляется стандартизированное отклонение от среднего значения потока по данной станции; записи с |z| > 2,5 классифицируются как аномальные. Метод Isolation Forest [8] реализован в многомерном пространстве признаков [TotalPassengers, IncomingPassengers, OutgoingPassengers, imbalance], что позволяет выявлять аномалии, невидимые при маргинальном анализе. Уровень загрязнения (contamination) установлен равным 3 %.
Регрессионная модель краткосрочного прогнозирования строится на основе GradientBoostingRegressor (библиотека scikit-learn) с гиперпараметрами: 300 деревьев, глубина 4, скорость обучения 0,05. В качестве признаков используются лагированные значения потока (lag-1 и lag-4 квартала), календарные переменные (год, номер квартала) и индикаторы линии метро (one-hot-кодирование). Валидация проводится на хронологическом разбиении: все годы, кроме последнего — обучающая выборка; последний год — тестовая. Метрики качества: MAE, MAPE и sMAPE. В качестве базовой модели (бейзлайна) используется значение аналогичного квартала предыдущего года.
3. Результаты
3.1. Разведочный анализ
Собранный массив данных включает сведения о 15 линиях метрополитена, более 300 вестибюлях и свыше 240 уникальных станций; квартальный датасет насчитывает более 3 000 записей за 2021–2025 годы (рис. 1).
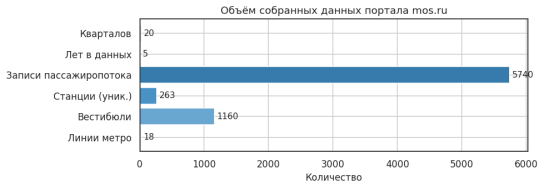
Рис. 1. Объём собранных данных портала data.mos.ru (разработано автором)
Квартальная динамика пассажиропотока (рис. 2) демонстрирует устойчивый рост после спада 2021–2022 годов: суммарный поток по сети восстановился до допандемийного уровня и продолжает увеличиваться. Выраженная сезонность сохраняется на всём периоде наблюдений: пик приходится на IV квартал, минимум — на I квартал.
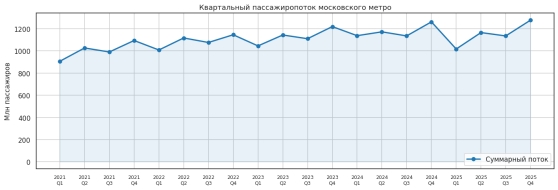
Рис. 2. Квартальный пассажиропоток московского метро, 2021–2025 (разработано автором)
Анализ сезонности (рис. 3) подтверждает системный характер квартальных колебаний: IV квартал в среднем превышает годовое значение на 6.9 %, тогда как I квартал отстаёт на 7.4 %. Данный эффект объясняется ростом деловой активности в осенне-зимний период и снижением пассажиропотока в январе в связи с праздничными днями.
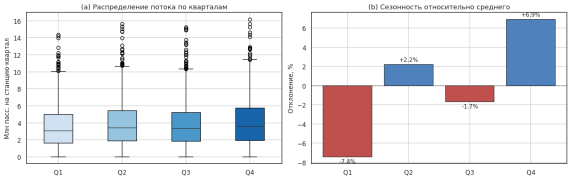
Рис. 3. Сезонность пассажиропотока: распределение по кварталам и отклонение от среднего (разработано автором)
Нагруженность линий существенно различается (рис. 4): три ключевые линии концентрируют основную долю совокупного пассажиропотока, тогда как периферийные и кольцевые маршруты значительно уступают им по абсолютным значениям.
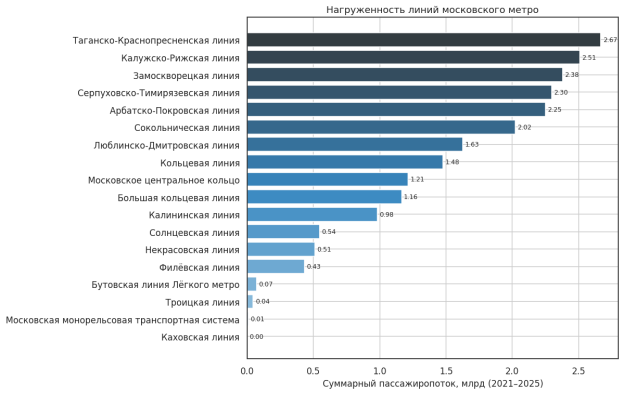
Рис. 4. Нагруженность линий московского метро, суммарный поток 2021–2025 (разработано автором)
Распределение нагрузки между станциями крайне неравномерно (рис. 5): коэффициент вариации превышает 71.3 %. Лидер по суммарному потоку — станция Комсомольская (381 млн пасс.), аутсайдер — станция Театральная (0.0 млн пасс.).
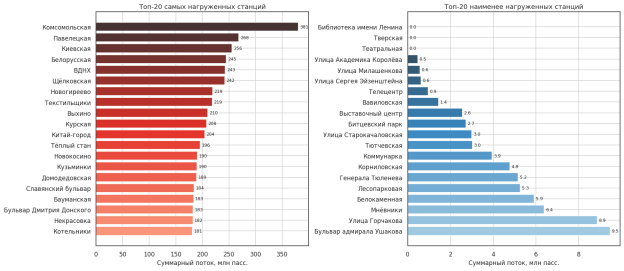
Рис. 5. Топ-20 наиболее и наименее нагруженных станций (разработано автором)
3.2. Кластеризация станций
Метод «локтя» (рис. 6) указал на оптимальное число кластеров k = 4. По профилю нагрузки выделены: крупные пересадочные узлы с высоким стабильным потоком, станции среднего пояса, периферийные станции с высокой вариативностью и новые станции с выраженным трендом роста (рис. 7). Географически кластеры соответствуют удалённости от центра: узловые станции сосредоточены в исторической части города, новые — на периферии.
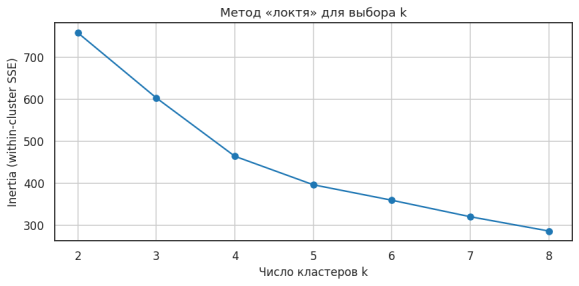
Рис. 6. Метод «локтя» для выбора числа кластеров K-Means (разработано автором)
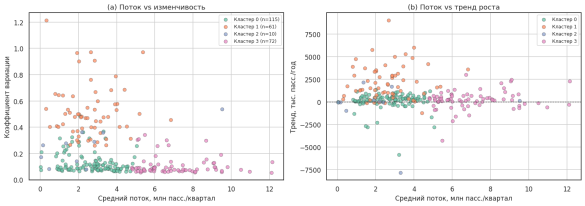
Рис. 7. Кластеризация станций: поток / изменчивость и поток / тренд (разработано автором)
3.3. Обнаружение аномалий
Метод Z-оценки (порог |z| > 2,5) выявил 57 аномальных записей (0.99 % выборки), Isolation Forest при уровне загрязнения 3 % — 173 записей (3.01 %). Наибольшая концентрация аномалий фиксируется в 2022 году (рис. 8), что соответствует нестабильному восстановлению пассажиропотока после пандемийного спада. Пересечение двух методов позволяет выделить наиболее достоверные случаи отклонений: Z-оценка чувствительна к резким выбросам на конкретной станции, Isolation Forest дополнительно улавливает многомерные аномалии по совокупности признаков.
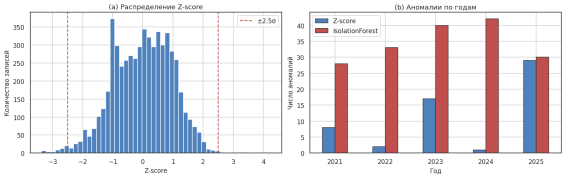
Рис. 8. Распределение Z-оценок и динамика аномалий по годам (разработано автором)
3.4. Прогнозирование пассажиропотока
Модель GradientBoostingRegressor на тестовой выборке последнего года достигла MAE = 907,140 пасс./квартал и sMAPE = 30.71 %, превзойдя бейзлайн «значение год назад» на +20.8 % по MAE (рис. 9). Наибольший вклад в прогноз вносят лагированные значения потока — предыдущего квартала и аналогичного квартала прошлого года — что подтверждает высокую инерционность и выраженную сезонность пассажиропотока. Линейные индикаторы и номер квартала дополнительно учитывают системные различия между маршрутами.
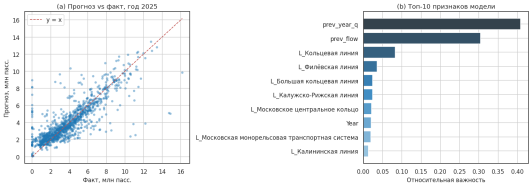
Рис. 9. Прогноз / факт и топ-10 признаков модели по важности (разработано автором)
3.5. Геовизуализация
Пространственное распределение нагрузки (рис. 10) демонстрирует радиально-кольцевую структуру московского метро: максимальные потоки сосредоточены в центре и вдоль основных диаметральных направлений. Цветовая шкала и размер маркеров пропорциональны суммарному пассажиропотоку за 2021–2025 годы, подписаны восемь наиболее загруженных станций.
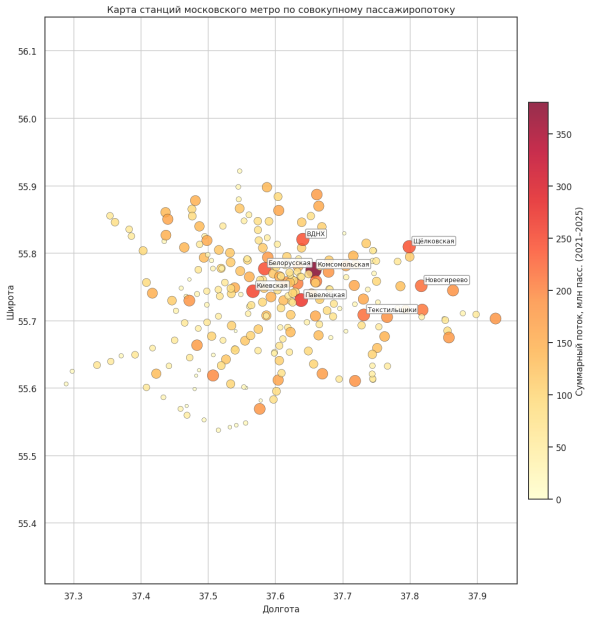
Рис. 10. Карта станций московского метро по суммарному пассажиропотоку
Заключение
В работе продемонстрирован полный воспроизводимый цикл анализа открытых транспортных данных: автоматизированный сбор через REST API портала открытых данных Правительства Москвы, нормализация GeoJSON-ответов, разведочный анализ, кластеризация, детекция аномалий и краткосрочное прогнозирование. Совокупность разработанных модулей формирует основу системы мониторинга качества пассажирских перевозок: типология станций позволяет дифференцировать управленческие решения, детектор аномалий обеспечивает автоматическую сигнализацию о нетипичных периодах, а прогностическая модель даёт возможность планировать ресурсы с учётом ожидаемой нагрузки.
Литература:
1. Московский Метрополитен. — URL: https://mosmetro.ru/
2. Портал открытых данных Правительства Москвы. — URL: https://data.mos.ru/
3. Входы и выходы вестибюлей станций Московского метрополитена — URL: https://data.mos.ru/opendata/624/
4. Линии Московского метрополитена — URL: https://data.mos.ru/opendata/2278/
5. Пассажиропоток по станциям Московского метрополитена — URL: https://data.mos.ru/opendata/62743/
6. Python — URL: https://www.python.org/downloads/
7. Кластеризация: алгоритмы k-means и c-means — URL: https://habr.com/ru/articles/67078/
8. IsolationForest — URL https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html

