Введение
Современные информационные системы ежедневно формируют большое количество записей о действиях пользователей, работе сервисов, сетевых соединениях и срабатываниях средств защиты. Часть таких записей является обычным фоном: плановые операции, единичные ошибки входа, уведомления о доступе к ресурсам. При этом в том же потоке могут присутствовать признаки реального инцидента, например серия неудачных попыток аутентификации, подозрительное повышение привилегий или вход с необычного адреса.
На практике специалист по информационной безопасности не всегда может последовательно просмотреть весь поток уведомлений. Чем больше источников подключено к мониторингу, тем выше риск пропуска события, требующего немедленной реакции. Поэтому важной задачей становится не только сбор событий, но и их распределение по степени значимости. Приоритет должен помогать аналитику быстро понять, какие записи необходимо обработать в первую очередь, а какие можно оставить для последующей проверки.
Распространенные правила и сигнатуры удобны для первичной фильтрации, однако они не всегда учитывают контекст. Одно и то же событие может иметь разный смысл в зависимости от частоты повторения, времени возникновения, источника и сочетания с другими действиями. В связи с этим целесообразно использовать комбинированный подход: базовые правила сохраняют объяснимость оценки, а интеллектуальный модуль уточняет итоговый уровень риска по совокупности признаков [1; 2].
Целью работы является разработка системы приоритизации событий информационной безопасности с использованием интеллектуального модуля анализа. Для достижения цели необходимо определить признаки, влияющие на приоритет события, описать структуру системы, разработать алгоритм обработки и показать работу прототипа на тестовом наборе событий.
Анализ подходов к обработке событий
События информационной безопасности поступают из разных источников: системных журналов, сетевого оборудования, средств обнаружения вторжений, антивирусных решений и SIEM-систем. Обычно такие записи различаются форматом, полнотой полей и уровнем детализации. Поэтому перед оценкой их необходимо привести к единому виду: выделить время, тип события, источник, пользователя, описание и дополнительные признаки.
Классический способ обработки основан на заранее заданных правилах. Например, единичная ошибка входа может получать низкий приоритет, а пять и более ошибок за короткое время с одного адреса — средний или высокий. Преимущество правил состоит в простоте проверки и понятности результата. Недостаток проявляется при сложных сценариях, когда опасность определяется не одним признаком, а их сочетанием.
Корреляция событий позволяет рассматривать не отдельные записи, а последовательность действий. Если вход в систему, обращение к закрытому ресурсу и попытка повышения привилегий происходят в близкие моменты времени, итоговый риск должен быть выше, чем при изолированном появлении каждого из этих событий. Однако качество корреляции зависит от полноты входных данных и корректности заданных связей.
Интеллектуальные методы применяются для классификации событий, выявления аномалий и оценки подозрительности. В исследованиях по тематике SOC и triage-процессов отмечается, что машинное обучение может ускорять отбор значимых уведомлений, но полностью заменять правила им нецелесообразно из-за требований к объяснимости и контролю качества решений [1; 3]. Поэтому в разрабатываемой системе интеллектуальный модуль используется как дополнительный компонент, а не как единственный механизм принятия решения.
Для практического прототипа достаточно использовать скоринговую модель. Она не требует большого обучающего набора, но позволяет формализовать влияние признаков: частота повторения, тип события, принадлежность источника к внешней сети, необычное время, наличие действий с привилегиями. В дальнейшем такая модель может быть заменена более сложным классификатором или модулем обучения на обратной связи от аналитика.
Структура разрабатываемой системы
Предлагаемая система предназначена для автоматизированного анализа входного потока событий и назначения каждому событию уровня приоритета. В составе системы выделяются модуль сбора, блок предварительной обработки, модуль выделения признаков, база правил, интеллектуальный модуль анализа, модуль приоритизации и пользовательский интерфейс.
Модуль сбора получает события из журналов безопасности, сетевых устройств, IDS/IPS, SIEM или тестового файла. Далее блок предварительной обработки нормализует записи: приводит время к единому формату, удаляет дубликаты, отделяет ключевые поля от текстового описания и отбрасывает явно служебные сообщения. Такой этап уменьшает объем фоновых данных и повышает качество последующей оценки.
После нормализации выполняется выделение признаков. Для каждого события могут рассчитываться тип события, источник, пользователь, число повторений за заданный интервал, время появления, признак внешнего адреса, наличие обращения к привилегированным функциям и связь с другими событиями. Эти признаки передаются в правила анализа и интеллектуальный модуль.
База правил отвечает за очевидные условия: множественные ошибки входа, сканирование портов, попытка повышения привилегий, необычный источник или повторение одинаковых записей. Интеллектуальный модуль формирует дополнительную оценку подозрительности. Затем модуль приоритизации объединяет результаты и относит событие к низкому, среднему или высокому уровню.
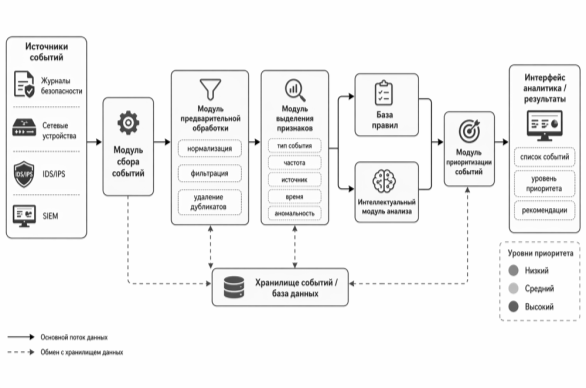
Рис. 1. Общая схема программной реализации системы
Алгоритм приоритизации
Алгоритм обработки одного события можно представить как последовательность операций. Сначала запись поступает в систему и проходит нормализацию. Затем из нее выделяются признаки, необходимые для оценки. После этого событие проверяется по правилам, а интеллектуальный модуль рассчитывает дополнительный балл риска. На завершающем этапе суммарная оценка переводится в один из трех уровней приоритета.
В демонстрационном прототипе используется простая балльная схема. Низкоопасные события получают минимальный вес. Повышающие признаки добавляют баллы: большое количество повторений, внешний источник, нетипичное время, подозрительный тип события, связь с действиями по изменению прав. Итоговая оценка сравнивается с порогами. Если сумма мала, событие относится к низкому приоритету; при средней сумме — к среднему; при превышении верхнего порога — к высокому.
Такая схема удобна для демонстрации, поскольку аналитик может понять, почему событию назначен конкретный уровень. Например, одиночная неудачная попытка входа в рабочее время не является достаточным основанием для немедленного реагирования. Но если похожие попытки повторяются с одного адреса, система повышает приоритет. Если к этому добавляется вход с необычного адреса или попытка повышения привилегий, событие попадает в список первоочередной обработки.
Использование трех уровней приоритета упрощает восприятие результата. Низкий приоритет соответствует фоновым и единичным отклонениям. Средний указывает на необходимость контроля или дополнительной проверки. Высокий означает потенциально опасную ситуацию, которую следует анализировать в первую очередь.
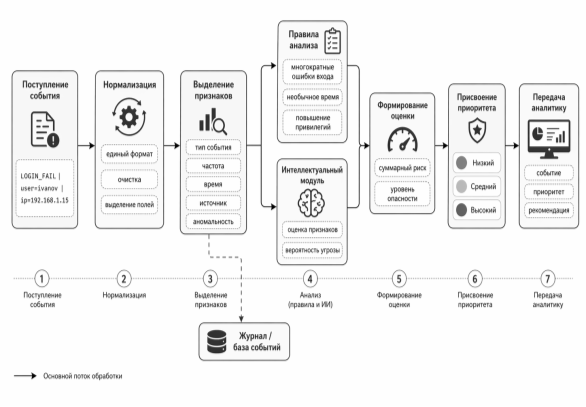
Рис. 2. Блок-схема алгоритма обработки одного события
Программная реализация
Прототип системы реализован на языке Python. Выбор языка обусловлен удобством работы со структурированными данными, наличием библиотек для обработки таблиц и возможностью быстро создавать демонстрационные модели анализа. Входные события в прототипе представлены в виде набора записей, где указаны время, тип, источник, пользователь, описание и дополнительные параметры.
На первом этапе программа считывает входной набор и приводит записи к единому формату. Затем удаляются дублирующиеся события и рассчитываются признаки. Для тестирования были использованы типовые ситуации: одиночный неудачный вход, серия ошибок аутентификации, сканирование портов, доступ к защищенному ресурсу, служебная операция резервного копирования и попытка повышения привилегий.
После обработки каждое событие получает числовую оценку и текстовый уровень приоритета. Результаты выводятся в интерфейсе в отсортированном виде: события высокого уровня отображаются выше остальных, рядом указывается статус обработки. Такой подход позволяет специалисту сразу перейти к наиболее критичным записям, не просматривая весь поток в хронологическом порядке.
Таблица 1
Пример результатов приоритизации событий
|
Тип события |
Признаки |
Оценка |
Приоритет |
Рекомендация |
|
Служебная операция |
плановое резервное копирование |
1 |
низкий |
наблюдение |
|
Неудачный вход |
единичная ошибка пользователя |
2 |
низкий |
без срочной реакции |
|
Сканирование портов |
внешний источник, сетевой признак |
5 |
средний |
проверить источник |
|
Множественные ошибки входа |
повторение, один IP-адрес |
6 |
средний |
контроль учетной записи |
|
Повышение привилегий |
критичный тип, рабочая станция |
9 |
высокий |
первоочередной анализ |
|
Необычный вход |
нетипичное время, внешний адрес |
8 |
высокий |
проверить сессию |
Представленные результаты показывают, что прототип корректно разделяет фоновые и потенциально опасные события. Служебные операции и единичные ошибки не поднимаются в верхнюю часть списка. События, связанные с сетевой активностью, множественными ошибками входа и повышением привилегий, получают больший вес и становятся заметнее для аналитика.
Интерфейс прототипа содержит список событий, фильтр, сортировку по приоритету, сводку по количеству событий каждого уровня и краткую рекомендацию. В публикации рисунок интерфейса оставлен как один из ключевых материалов, поскольку он показывает практический результат работы разработанной системы.
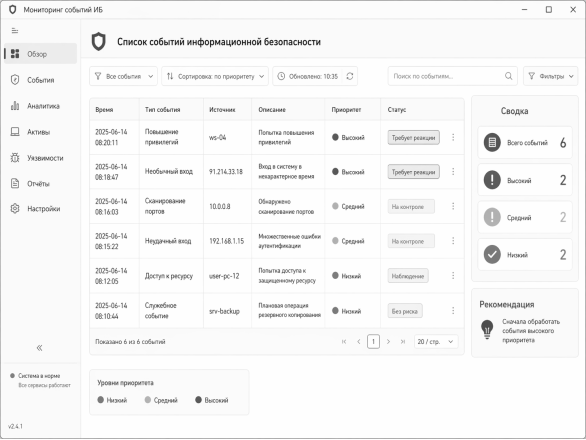
Рис. 3. Пример интерфейса программы с отсортированными событиями
Оценка результатов
Разработанная система решает прикладную задачу предварительного отбора событий. Ее основное назначение состоит не в автоматической замене специалиста, а в сокращении времени на первичный просмотр уведомлений. Пользователь получает уже упорядоченный список, где наиболее важные записи находятся в начале и сопровождаются понятным уровнем приоритета.
Преимуществом предложенного решения является сочетание правил и интеллектуального анализа. Правила обеспечивают прозрачность и позволяют быстро настроить реакцию на известные типы событий. Интеллектуальный модуль учитывает дополнительные признаки и делает оценку более гибкой. При этом сохраняется возможность объяснить итоговый результат через набор факторов, повлиявших на балл риска.
Ограничение прототипа связано с тем, что проверка выполнена на тестовом наборе событий. Для промышленного применения необходимо подключить реальные источники данных, расширить перечень признаков, настроить хранение истории и провести оценку качества на размеченных событиях. Также важно учитывать, что разные организации могут по-разному определять критичность событий: пороги и веса должны настраиваться под конкретную инфраструктуру.
Дальнейшее развитие системы может быть связано с использованием моделей машинного обучения, обучением на действиях аналитика и добавлением механизма обратной связи. Например, если специалист регулярно изменяет приоритет определенного класса событий, система может учитывать это при последующих расчетах. Такой подход позволит сделать приоритизацию более адаптивной без отказа от базовой объяснимости.
Заключение
В работе рассмотрена проблема обработки большого потока событий информационной безопасности и предложена система их автоматизированной приоритизации. Показано, что применение только жестко заданных правил ограничивает гибкость анализа, а использование интеллектуального модуля без правил может снижать объяснимость результата. Поэтому в статье выбран комбинированный подход.
Описана структура системы, включающая сбор событий, предварительную обработку, выделение признаков, правила анализа, интеллектуальный модуль и блок присвоения приоритета. Разработан программный прототип, который сортирует события по уровням значимости и выводит их в интерфейсе аналитика. На тестовом наборе показано, что система выделяет события высокого и среднего приоритета, оставляя фоновые записи ниже в списке.
Практическая значимость работы заключается в снижении нагрузки на специалиста по информационной безопасности и ускорении первичного реагирования. Полученные результаты могут использоваться как основа для дальнейшей разработки системы мониторинга, подключаемой к реальным журналам и средствам защиты.
Литература:
- Gupta N., Traore I., Quinan P. M. F., Nakkabi Y., Jain A. Automated Event Prioritization for Security Operation Center using Deep Learning // 2019 IEEE International Conference on Big Data (Big Data). 2019. P. 5864–5872. DOI: 10.1109/BigData47090.2019.9006073.
- Jalalvand F., Chhetri M. B., Nepal S., Paris C. Adaptive alert prioritisation in security operations centres via learning to defer with human feedback // arXiv preprint. 2025. arXiv:2506.18462.
- Микрюков А. А., Бабаш А. В., Сизов В. А. Классификация событий в системах обеспечения информационной безопасности на основе нейросетевых технологий // Открытое образование. 2019. Т. 23, № 1. С. 4–13. DOI: 10.21686/1818–4243–2019–1-4–13.
- Букин А. В., Самонов А. В. Обнаружение инцидентов информационной безопасности на основе технологии нейронных сетей // Вопросы кибербезопасности. 2022. № 4. С. 60–69.
- Мещеряков Р. В. Перспективные направления применения технологий искусственного интеллекта при защите информации // Вопросы кибербезопасности. 2024. № 2. С. 6–18.

