В последние годы наблюдается стремительный рост рынка мобильных приложений, сопровождающийся усилением конкуренции за внимание пользователей. В условиях высокой насыщенности цифровой среды особую значимость приобретает задача повышения вовлечённости и удержания пользователей. Одним из ключевых инструментов решения данной задачи является персонализация пользовательского опыта.
Современные мобильные приложения используют персонализацию для адаптации контента (ленты, рекомендаций, уведомлений) под поведение пользователя. При этом необходимо учитывать ограничения мобильных устройств (включая ограниченные вычислительные ресурсы), необходимость обработки данных в реальном времени и ограниченность доступных пользовательских данных.
В связи с этим всё большее внимание уделяется применению методов машинного обучения, позволяющих анализировать поведение пользователей и формировать персонализированные рекомендации. Применение данных методов способствует повышению релевантности рекомендаций и увеличению пользовательской активности.
Целью данной работы является исследование методов машинного обучения, применяемых для персонализации пользовательского опыта в мобильных приложениях, а также оценка их эффективности.
Научная новизна работы заключается в сравнительном анализе базового подхода и подхода машинного обучения к персонализации в условиях ограниченных мобильных ресурсов.
Обзор методов персонализации
Одним из наиболее распространенных методов анализа данных о пользователях является коллаборативная фильтрация, основанная на анализе поведения пользователей. Данный подход предполагает формирование рекомендаций на основе предпочтений других пользователей с аналогичными интересами. К преимуществам данного метода относится способность выявлять скрытые зависимости, однако он требует значительного объёма данных и сопряжен с проблемой «холодного старта».
Другим подходом является контентная фильтрация, при которой рекомендации формируются на основе характеристик объектов и предпочтений конкретного пользователя. Данный метод не зависит от данных других пользователей, что делает его применимым на ранних этапах работы системы, однако его эффективность ограничена качеством и полнотой описания контента.
Кроме того, в задаче персонализации используются методы машинного обучения, такие как логистическая регрессия, методы кластеризации и решающие деревья. Эти алгоритмы обеспечивают выявление закономерностей, моделирование вероятности взаимодействия и прогнозирование поведения пользователей. Согласно исследованиям в области рекомендательных систем, применение моделей машинного обучения способствует повышению точности рекомендаций по сравнению с базовыми подходами [1].
В последние годы также гибридно используются контентная и коллаборативная фильтрации, что помогает достичь более высоких результатов в формировании подборки персонализированных рекомендаций и снизить влияние ограничений отдельных методов [2].
Проведённый сравнительный анализ показал, что коллаборативная фильтрация демонстрирует более высокую точность при наличии большого объёма данных, тогда как контентная фильтрация обеспечивает стабильную работу при ограниченных данных. Методы машинного обучения, в свою очередь, позволяют достичь наилучших результатов при условии достаточного объёма обучающей выборки, однако требуют дополнительных вычислительных ресурсов.
Указанные методы могут быть адаптированы для использования в мобильной среде с учётом требований обработки данных в реальном времени. В частности, часть вычислений может быть перенесена на серверную сторону, тогда как на мобильном устройстве могут использоваться уже обученные модели.
Таким образом, выбор метода персонализации определяется доступными данными, требованиями к скорости работы системы и ограничениями мобильной платформы. В условиях мобильных приложений ключевым фактором становится баланс между точностью рекомендаций и вычислительными затратами.
Применение механизмов рекомендаций и анализа поведения в мобильных приложениях
В контексте развития мобильных приложений анализ поведения пользователей становится важным этапом на пути к улучшению качества взаимодействия и адаптации контента под индивидуальные предпочтения. Аналитика взаимодействий пользователя с приложением позволяет выявлять закономерности поведения, что используется для построения рекомендательных систем и оптимизации интерфейса.
В современных инженерных и практических публикациях подчёркивается значимость анализа данных для персонализации и повышения эффективности мобильных приложений. Например, анализ поведения пользовательских взаимодействий (включая последовательность действий, частоту использования функций и навигацию по элементам интерфейса) является ключевым этапом при построении систем рекомендаций и адаптивных интерфейсов [3].
Рекомендательные модели, использующие данные о предпочтениях и прошлых действиях, позволяют формировать предложения релевантного контента и функциональности в приложениях, что улучшает удержание пользователей и повышает уровень вовлечённости. Рекомендательные системы и алгоритмы машинного обучения применяются в широком спектре онлайн-сервисов для анализа поведения и генерации персонализированных предложений на основе данных пользователя [3].
Применение данных подходов требует адаптации моделей к ограничениям мобильных устройств и работе в реальном времени.
Методология исследования
В рамках данного исследования рассматривается задача персонализации контента в мобильном приложении на основе анализа пользовательского поведения.
Задача персонализации формализуется как задача прогнозирования вероятности взаимодействия пользователя u с объектом i :
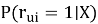
где X — вектор признаков поведения пользователя.
Для проведения эксперимента была сформирована модель пользовательских данных, включающая информацию о взаимодействиях пользователей с элементами приложения (просмотры, клики, выбор контента). В качестве признаков использовались: частота взаимодействий, тип контента, время активности пользователя и последовательность действий. В исследовании использовалась выборка, включающая 1000 пользователей и более 5000 взаимодействий. Данные были разделены на обучающую и тестовую выборки в соотношении 80:20.
На основе указанных данных были реализованы три подхода к формированию рекомендаций:
– базовый подход, основанный на популярности контента;
– коллаборативная фильтрация, учитывающая сходство предпочтений пользователей;
– подход с использованием методов машинного обучения, основанный на применении алгоритма классификации для прогнозирования интереса пользователя к контенту.
В качестве модели машинного обучения использовалась логистическая регрессия, обеспечивающая оценку вероятности взаимодействия пользователя с элементом контента на основе его поведения.
Модель логистической регрессии оценивает вероятность взаимодействия пользователя с объектом по формуле:
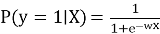
Для оценки эффективности предложенных подходов использованы следующие метрики: точность рекомендаций (для оценки общей корректности предсказаний), доля релевантных рекомендаций (для оценки доли релевантных рекомендаций среди предложенных), а также уровень пользовательской вовлечённости, измеряемый средним числом взаимодействий пользователя с контентом за сессию.
Эксперимент проводился путём сравнения результатов работы трёх подходов на одном и том же наборе данных. Показатели точности представлены в числовом виде, тогда как уровень вовлечённости и вычислительной сложности оценивался качественно. Полученные результаты представлены в таблице 1.
Таблица 1
Сравнительный анализ методов персонализации
|
Метод |
Точность рекомендаций |
Доля релевантных рекомендаций |
Вовлечённость |
Сложность |
|
Базовый (популярность) |
0,65 |
0,62 |
Низкая |
Низкая |
|
Коллаборативная фильтрация |
0,75 |
0,72 |
Средняя |
Средняя |
|
Машинное обучение (логистическая регрессия) |
0,82 |
0,78 |
Высокая |
Очень высокая |
Результаты, представленные в таблице 1, демонстрируют, что базовый подход характеризуется наименьшими показателями точности и вовлечённости пользователей, что обусловлено отсутствием учёта индивидуальных предпочтений.
Повышение доли релевантных рекомендаций с 0,62 до 0,78 свидетельствует о снижении доли нерелевантных рекомендаций и улучшении качества персонализации. Увеличение точности рекомендаций до 0,82 указывает на более точное прогнозирование пользовательского поведения.
Полученные результаты свидетельствуют о том, что применение методов машинного обучения обеспечивает повышение эффективности персонализации в мобильных приложениях.
Результаты сравнения точности методов представлены на рис. 1.
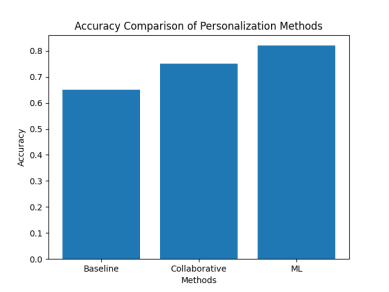
Рис. 1. Сравнение точности методов персонализации
В работе проведён сравнительный анализ методов персонализации в мобильной среде. Показано, что использование моделей машинного обучения повышает точность рекомендаций (до 0,82) и долю релевантных предложений по сравнению с базовыми подходами. Установлено, что эффективность методов зависит от объёма данных и доступных вычислительных ресурсов, что требует адаптации моделей для мобильной среды. Полученные результаты подтверждают эффективность применения моделей машинного обучения для адаптации пользовательского опыта в мобильных приложениях.
Литература:
1. Ricci F., Rokach L., Shapira B. Recommender Systems Handbook. — Springer, 2015.
2. Aggarwal C. C. Recommender Systems: The Textbook. — Springer, 2016.
3. Рекомендательные системы в современном мире [Электронный ресурс] // Хабр. — URL: https://habr.com/ru/companies/otus/articles/950650/ (дата обращения: 22.03.2026).

