Введение
Сфера разработки видеоигр является довольно перспективным направлением бизнеса в наши дни, а разработка мобильных игр в особенности, так как они доступны каждому. У большинства людей есть смартфоны и планшеты с доступом в интернет, которые позволяют играть во время поездки на работу, ожидания в очередях и т. д., тем самым, не затрачивая реальное время своего досуга.
Большинство мобильных игр являются бесплатными, так называемыми free-to-play. Такие игры приносят доход разработчикам от внутриигровых покупок и показа рекламы, позволяя расширить свою «сферу влияния» на тех, кто не готов платить за скачивание игры либо за возобновляемую подписку.
Показатель LTV (Life time value) отражает доходность с одного клиента за все время его существования. По сути, это доход с клиента до момента удаления им приложения. В индустрии мобильных игр, как и в любой другой, показатель LTV является очень важным. Компании инвестируют в пользователей посредствам рекламы, скидок, специальных предложений, закупки трафика и так далее. Для того, чтобы грамотно распределять бюджет на вовлечение необходимо оценивать потенциальную доходность с клиентов.
В статье Forbes «Don't Get Lazy About Your Client Relationships» Патрик Халл пишет, что вероятность продажи чего-либо старому клиенту составляет 60–70 % против 5–20 % новому. Также удержание существующих клиентов обходится на порядок дешевле привлечения новых. [1]
В статье «Юнит-экономика» журнала «Бизнес-образование в экономике знаний» Горбачева М. А. делает акцент на том, что прогнозирование показателей является неотъемлемой частью работы над проектом и лучшим инструментом для руководства при принятии решений. [2]
Целью работы является анализ существующих методик и применение машинного обучения в прогнозировании показателя LTV для мобильной игры.
Задачи исследования: изучение имеющихся подходов к прогнозированию LTV; обзор литературы на тему исследования; описание методики исследования; анализ полученных результатов.
Объект исследования — мобильная free-to-play игра.
Предмет исследования — доходность с пользователей приложения.
Аналитики компании Coffee An–alytics в результатах своего исследования пишут о том, в России и СНГ только треть компаний используют метрику LTV, в то время как в Великобритании этот показатель рассчитывают 93 % всего e-commerce бизнеса. [3]
В ходе работы выявлено, что на сегодняшний день на тему прогнозирования показателя LTV в мобильных играх, особенно с применением машинного обучения, мало исследований, так как индустрия является относительно новой. Таким образом данное исследование является значимым для индустрии и отличается научной новизной.
Описание методики исследования и обоснование ее выбора
В большинстве источников по теме прогнозирования LTV предпочтение отдается коэффициентным подходам. Так, например, аналитики из Pixonic, Crazy Panda и Mail.ru Group в своей статье на крупнейшей в рунете платформе для предпринимателей и высококвалифицированных специалистов «vc.ru» выделяют два подхода к прогнозированию LTV — на основе удержания и при помощи накопительного ARPU. [4]
Первый подход используется при стабильном, равномерном доходе с пользователей, без каких-либо резких изменений. Жизненная ценность клиента рассчитывается по формуле:
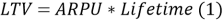
где ARPU — средняя выручка с одного пользователя, Lifetime — время «жизни» пользователя.
Для расчета LTV по формуле (1) нужно определить время жизни клиента. Существует два основных способа подсчета показателя Lifetime: первый — субъективная оценка жизни пользователя (наиболее часто используют 7 и 14 дней); второй способ — вычисление интеграла от функции удержания (Retention). [5]
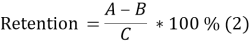
где A — количество клиентов в конце периода, В — количество всех клиентов за период, С — количество клиентов в начале периода.
На рисунке 1 пример графика удержания клиентов.
![График удержания клиентов [6]](https://articles-static-cdn.moluch.org/articles/j/91786/images/91786.003.jpg)
Рис. 1. График удержания клиентов [6]
Показатель ARPU считается по формуле:
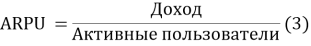
ARPU может быть подневным, помесячным и так далее. Для расчета LTV необходимо привести к одному виду ARPU и Retention, выбрав нужный период (например, помесячный срез).
Минусом такого подхода к расчету LTV является то, что показатель ARPU предполагается неизменным. Пользователи с аномальным поведением могут вносить сильно изменять метрику, поэтому такой способ расчета LTV подойдет, например, для продуктов, доступных по подписке.
Второй подход к расчету LTV– при помощи накопительного ARPU. Эта метрика рассчитывается также, как и обычный ARPU, но отличается тем, что рассчитывается исключительно для определенной когорты пользователей (установивших приложение в определенный период) и накапливается каждый день. На рисунке 2 график накопительного ARPU, LTV и CPI (цена за привлечение пользователей).
![График накопительного ARPU, LTV и CPI [7]](https://articles-static-cdn.moluch.org/articles/j/91786/images/91786.005.jpg)
Рис. 2. График накопительного ARPU, LTV и CPI [7]
На основе имеющихся данных о накопительном ARPU можно сделать прогноз дохода с пользователя в будущем. Так как кривая накопительного ARPU изгибается равномерно, прогноз можно рассчитать по формуле:
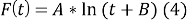
где t — дней от регистрации пользователя, А и В — параметры функции.
Точка, в которой график становится перпендикулярен оси х и есть средний показатель LTV на пользователя.
Минусом такого подхода также является то, что пользователи с аномальным поведением могут сильно влиять на график функции накопительного ARPU.
В связи с тем, что оба представленных выше подхода имеют свои минусы, было решено исследовать возможность использования машинного обучения для предсказания показателя LTV.
Для начала нужно определить временные рамки расчета LTV, функции, которые будут использованы в предсказании, рассчитать значение LTV для обучения модели и построить саму модель.
Выбор временного окна может зависеть от различных факторов, в нашем случае, основываясь на специфике мобильной игры, было решено использовать 3-месячный период. Все пользователи были сегментированы с помощью RFM- подхода. Для проведения сегментации необходимо вычислить три показателя:
— recency — давность (сколько времени прошло с последнего платежа пользователя);
— frequency — частота (общее количество платежей пользователя за определенный период);
— monetary — средний чек (или общая сумма платежей пользователя).
С помощью RFM-анализа можно определить, кто покупает много и часто, кто мало, а кто давно не покупал ничего.
После расчета LTV каждого клиента необходимо исключить выбросы, так как они могут значительно влиять на предсказание модели. Также имеет смысл оценить корреляцию между сегментом RFM-матрицы и значением LTV. Перед построением модели необходимо определить тип задачи. Предсказание LTV это задача регрессии, но было решено предсказывать не конкретное значение, а номер сегмента, которому будет принадлежать пользователь, то есть задача определяется как задача классификации.
Для решения поставленной задачи был использован язык python и некоторые библиотеки для работы с данными.
Результаты исследования
Все пользователи были разделены на сегменты RFM-матрицы. На рисунке 3 графики зависимости показателей recency, frequency и monetary.
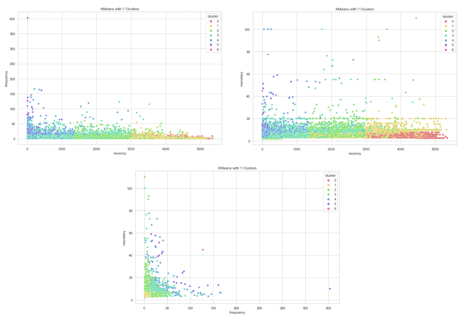
Рис. 3. Полученные сегменты по показателям частоты платежей, давности платежа и среднего чека
Методом к-средних были определены кластеры по каждому показателю. Далее номера кластеров были просуммированы и таким образом получено 6 итоговых сегментов, описание которых представлено в таблице 1.
Таблица 1
Описание сегментов
|
Номер кластера |
Название |
Описание |
|
0 |
УШЕДШИЕ |
Платили давно, редко, мало |
|
1 |
В ЗОНЕ РИСКА |
Платили давно, редко, траты средние |
|
2 |
ЗАСЫПАЮЩИЕ |
Платили не так давно (30 дней), мало, средние траты |
|
3 |
ЛОЯЛЬНЫЕ |
Платили недавно, относительно часто, средние траты |
|
4 |
ПОСТОЯННЫЕ ПЛАТЕЛЬЩИКИ |
Платили недавно, часто, много |
|
5 |
КИТЫ |
Платили недавно, очень часто, много |
|
6 |
ТОП |
Платили недавно, очень часто, очень много |
В качестве факторов для модели используются значения прибыли с клиента за его первый, второй, третий, седьмой, четырнадцатый и тридцатый день жизни. Также используется номер сегмента, определенный по метрикам RFM за первую неделю «жизни». Методом к-средних был определен кластер LTV, который и является результирующей переменной.
На рисунке 4 зависимость видно, как с ростом номера LTV кластера увеличиваются значения LTV.
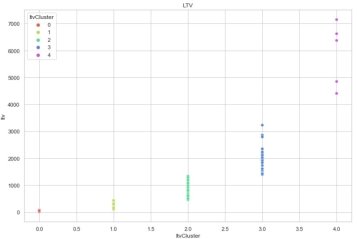
Рис. 4. График значений LTV относительно кластеров
Далее набор данных разделяется на обучающую и тестовую выборки. Для решения задачи мультиклассовой классификации использован алгоритм XGBoost.
Анализ и пояснение полученных результатов
Для реализации была использована ML библиотека XGBoost. Число классов для предсказания определилось в ходе кластеризации пользовательского LTV. Всего выявлено 5 кластеров, где нулевой кластер самый многочисленный, в который попали в основном не платящие пользователи.
Так как нулевой кластер составляет 99 % всех данных, было принято решение о балансировке классов при помощи oversampling, а именно алгоритма SMOTE (Synthetic Minority Oversampling Technique), rjnjhsq генерирует данные, похожие на каждый класс не дублируя их.
После балансировки классов данные были переданы в XGBClassifier с параметром максимальной глубины равно 5, и learning rate равной 0,1. На рисунке 6 представлены полученные результаты.
Более информативными показателями являются точность (precision), полнота (recall) и F-мера (f1-score). Точность отражает долю действительно положительных значений от предсказанных положительных значений. Вычисляется по формуле:
|
|
(5) |
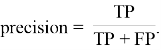
Полнота показывает долю истинно положительных значений от их общего количества:
|
|
(6) |
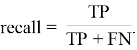
Для того, чтобы как-то обобщить результаты, используют F-меру — гармоническое среднее precision и recall:
|
|
(7) |

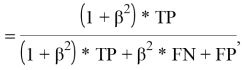
где β в общем случае равно 1.
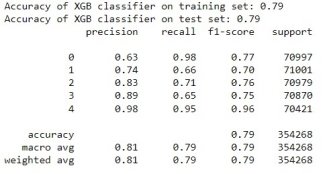
Рис. 5. Результаты классификации
Видно, что модель научилась хорошо предсказывать высокий сегмент плательщиков. Низкие сегменты предсказываются хуже. Для увеличения точности модели рекомендуется использовать подбор гиперпараметров классификатора.
Заключение
В ходе проведенного исследования выявлено, что на сегодняшний день нет большого количества литературных источников по изучаемой теме. Предсказание жизненной ценности пользователя в приложении является важной задачей для бизнеса и может способствовать грамотному распределению ресурсов на привлечение пользователей.
Также была проведена классификация пользователей на LTV — сегменты с использованием RFM-меток клиентов за первую неделю «жизни» в проекте. В качестве алгоритма мультиклассовой классификации использован XGBoost, так как хорошо зарекомендовал себя для решения подобного рода задач.
Из-за сильного дисбаланса классов в исходных данных было решено применить алгоритм балансировки SMOTE.
Получены результаты классификации с большей точностью для высоких сегментов плательщиков. В дальнейшем рекомендуется подбор гиперпараметров модели для улучшения точности.
Литература:
- Forbes [Электронный ресурс] — 2021. — Режим доступа: (https://www.forbes.com/sites/patrickhull/2013/12/06/tools-for-entrepreneurs-to-retain-clients/?sh=376bf5aa2443) (дата обращения: 09.12.2021)
- Горбачева, М. А. Юнит-экономика [Текст] / М. А. Горбачева // БИЗНЕС-ОБРАЗОВАНИЕ В ЭКОНОМИКЕ ЗНАНИЙ. — 2020. — № 3. — С.41–43
- Аналитическая платформа Coffee Analytics [Электронный ресурс] — 2021. — Режим доступа: (https://coffee-analytics.com/ltv-in-cis) (дата обращения: 09.12.2021)
- VC.ru [Электронный ресурс] — 2021. — Режим доступа: (https://vc.ru/promo/81060-how-to-ltv) (дата обращения: 09.12.2021)
- Аналитический портал devtodev [Электронный ресурс] — 2021. — Режим доступа: (https://www.devtodev.com/education/articles/ru/212/glavnie-metriki-lifetime) (дата обращения: 09.12.2021)
- Информационный ресурс, посвященный всем аспектам индустрии игр App2Top [Электронный ресурс] — 2021. — Режим доступа: (https://app2top.ru/marketing/modeliruem-uderzhanie-pol-zovatelej-v-poiskah-optimal-noj-formuly-99392.html) (дата обращения: 09.12.2021)
- Аналитический портал devtodev [Электронный ресурс] — 2021. — Режим доступа: (https://devtodev.medium.com/9-tips-to-increase-accuracy-of-the-revenue-forecasts-in-games-3be1ac921bda) (дата обращения: 09.12.2021)
- Base Group Labs Технологии анализа данных devtodev [Электронный ресурс] — 2021. — Режим доступа: (https://basegroup.ru) (дата обращения: 09.12.2021)
- Uplab [Электронный ресурс] — 2021. — Режим доступа: (https://www.uplab.ru/blog/unit-economics-how-to-evaluate-the-success-of-the-business/) (дата обращения: 09.12.2021)
- Уткин, Л. В., Модель классификации на основе неполной информации о признаках в виде их средних значений / Л. В. Уткин, Ю. А. Жук, И. А. Селиховкин // Искусственный интеллект и принятие решений. — 2012. — С.71–81.
- Мюллер А., Введение в машинное обучение с помощью Python. Руководство для специалистов по работе с данными / А. Мюллер, С. Гвидо // Вильямс — 2017. — 393 с.
- Алексеева, В. А. Использование методов машинного обучения в задачах классификации / В. А. Алексеева // Автоматизация процессов управления. — 2015 (март). — № 3(41). — С. 58–63.

