В статье автор исследует концепцию применимости big data в области баз данных.
Ключевые слова: big data, СУБД, PostgreSQL.
Введение
В современном мире все больше растет потребность в хранении и обработке достаточно больших ресурсов данных, которые нельзя расположить в рамках одного устройства. На данный момент все больше набирает популярность технология Big Data, которая в перспективе может устранить проблемы в структуризации сверхбольших объемов информации во множестве областей, такие как, финансовая среда, медицина, агропромышленность, банки, страхование, логистика, наука, маркетинг.
В общем случае данная технология позволяет систематизировать данные, находить причинно-следственные связи, что в свою очередь, помогает при обработке определенных запросов, которые трудно реализовать в общепринятых системах хранения данных. На примере данной технологии, можно отследить закономерности в передвижении определенной группы пользователей агрегаторов такси или иных перевозок в рамках коммерческого пользования. Данные, которые хранятся о покупателях, автопарке, партнерах, сотрудниках, пользователях, можно структурировать для обработки и анализа закономерностей, полученных из данных от партнеров, которые могут предсказать, какой группе пользователей предлагать услуги партнеров на истории их запросов или покупок в сфере услуг.
Для обеспечения хранения подобного объема данных требуются значительные вычислительные мощности, что может вызвать финансовые и кадровые трудности для компаний, обслуживающих огромное количество пользователей. Одна из ведущих компаний, чья деятельность прямо связана с передачей, хранением и обработкой огромного объема данных в различных формах по всему миру, оказывает значительное влияние на информационное пространство общества.
Тем не менее, сами по себе эти данные нет имеют за собой практической пользы, если не уметь правильно их использовать. Для повышения эффективности предприятий широко применяется анализ больших данных (Big Data), что открывает широкий спектр возможностей, таких как прогнозирование спроса на определенный товар или услугу. Благодаря анализу данных можно заранее оценить успешность продукта, еще до его выхода на рынок.
1. Определение методологий для исследования по теме «Анализ концепции big data в области баз данных»
Была сформулирована тема исследования: «Анализ концепции big data в области баз данных».
Выявлена проблема исследования:
При работе с большими данными есть проблема структуризации, т. к. информация может быть разнородной, что влечет за собой проблему масштабируемости, которая, скорее всего, является одним из ключевых затруднений при реализации концепции big data в области баз данных.
Была поставлена следующая цель исследования:
Проанализировать в каком ключе применяется концепция big data в области баз данных из области применения данной концепции.
Были определены следующие задачи:
— Определить причины использования больших данных в сфере баз данных;
— Сформулировать общие понятия концепции big data;
— Описать, в общих чертах, проблемы при использовании big data в сфере баз данных;
— Проанализировать подходы при работе с big data в области баз данных.
Объект исследования: концепция big data в области баз данных;
Предмет исследования: изучение технологий при реализации концепции big data в среде баз данных .
Гипотеза исследования : Проанализировав нижеописанные источники, можно будет сформулировать вывод о целесообразности применения концепции big data в области баз данных, опираясь на информацию из источников.
2. Анализ предметной области
В настоящее время, мировое деловое сообщество уделяет значительное внимание инновациям как потенциальному двигателю роста. Каждая компания осознает, что для достижения действительного успеха и конкурентоспособности в быстро меняющейся бизнес-среде необходимо вкладывать в инновации.
Анализ больших данных считается одним из ключевых направлений современных бизнес-инноваций с высоким потенциалом. В последнее время этот вид технологии привлекает повышенный интерес в деловых кругах по всему миру. Разнообразные управленческие возможности анализа больших данных для всех функций и отраслей бизнеса, а также перспективы от использования этой технологии, привлекают внимание компаний.
Согласно статистике, более половины всех применений анализа больших данных связаны с проблемами, касающимися клиентов. Это подчеркивает высокий спрос компаний на маркетинговые приложения технологии анализа больших данных. Таким образом, вопросы, связанные с использованием анализа больших данных в маркетинге, гармонично сочетаются с последними технологическими вызовами в сфере бизнеса.
Для более конструктивного анализа по теме big data, необходимо рассмотреть подход к самой концепции big data с разных сторон.
Как известно, само понятие big data достаточно широко, что является неоспоримым плюсом для разработки информационных систем, структур для хранения данных, аналитической базы в экономической сфере, системах безопасности, основанных на данной технологии. В ниже приведенных источниках, рассмотрим само понятие big data и его применение.
В статье «Цифровой маркетинг как современный тренд», авторы А. Д. Назаров и Н. Д. Товмасян описывают термин «Big Data» как «методы обработки данных огромных объёмов, которые позволяют анализировать эту информацию».
Неотъемлемой частью любого бизнеса является присутствие в онлайн-рекламе, будь то профиль в Яндекс Маркете, на YouTube или в других социальных сетях. Современные вызовы экономики побуждают компании пересматривать свои рекламные кампании и стратегии продвижения в сети с учетом цифровых маркетинговых технологий.
Таким образом, возникла новая ветвь развития маркетинга — «Big Data Driven Marketing», где все стратегические решения принимаются исключительно на основе анализа данных и гибкой сегментации клиентов. Гибкая сегментация клиентов представляет собой многофакторную кластеризацию по множеству критериев, преодолевая ограничения стандартных параметров, таких как пол, возраст и профессия.
На основе полученной информации можно выделить четыре стадии «знания» клиента в маркетинге:
1-я стадия: демография, доход;
2-я стадия: поведение с call-центром, поведение на сайте, геоданные, профили социальных сетей;
3-я стадия: поисковые данные пользователя, опросы, взаимодействие с компанией через приложения, кросс-дейвасность;
4-я стадия: история ответов на маркетинговые кампании, полноценный анализ скрытых связей между разными типами данных.
В статье «Стандарты в области больших данных», опубликованной в 2016 г. (https://cyberleninka.ru/article/n/standarty-v-oblasti-bolshih-dannyh), Д. Е. Намиот рассматривает проблему стандартизации больших данных. Автор данной статьи описывает, существующие стандарты в области больших данных на момент публикации статьи.
Наибольший интерес для анализа представлен в стандартах больших данных от NIST. В данных документах, приведены актуальные темы в область больших данных:
— Технические требования и стандартизация для метаданных.
— Языки запросов, включая нереляционные запросы для поддержки различных типов данных (например, XML, RDF, JSON, мультимедиа) и больших объемов данных операций (например, матричных операций).
— Проблемно-ориентированные языки для задач больших данных.
— Семантика для слабой согласованности и согласованности в конечном счете.
— Расширенные сетевые протоколы для эффективной передачи данных.
— Безопасность и контроль доступа.
— Удаленные, распределенные и федеративные аналитики данных, включая методы обнаружения и обработки ресурсов, а также методы интеллектуального анализа данных.
— Обмен и разделение данных.
— Системы хранения данных.
— Представление результатов анализа данных (сюда, очевидно, должны входить визуализация и объяснения).
— Энергетическая эффективность работы с большими данными.
— Интерфейс между реляционными (SQL) и нереляционными (NoSQL) хранилищами данных.
— Оценка качества и достоверности данных.
Приведенные в этой статье стандарты демонстрируют актуальный вектор развития в области больших данных на момент 2016 г. Так же, автор указывает на проблему взаимодействия установившегося стандарта SQL и новых стандартов больших данных в сфере баз данных. Не уделено внимание технической стороне в вопросе стандартизации в сфере хранения больших данных.
В статье “Применение Big Data при анализе больших данных в компьютерных сетях”, опубликованной в 2020 г. (https://cyberleninka.ru/article/n/primenenie-big-data-pri-analize-bolshih-dannyh-v-kompyuternyh-setyah), Орлов Г. А. привел основную информацию для сравнительной характеристики традиционных баз данных и big data. В данной статье представлены информативные таблицы при сравнении традиционных БД и big data. На рисунках 1–2 представлены информативные таблицы для сравнения традиционных БД и big data.
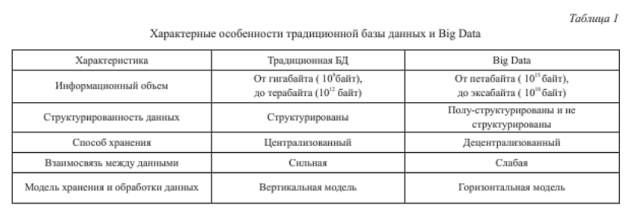
Рис. 1. Таблица с характерными особенностями традиционной базы данных и big data
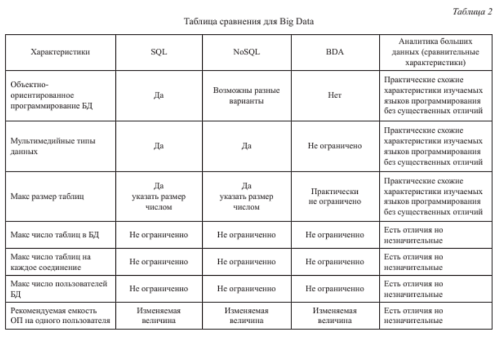
Рис. 2. Таблица сравнения для big data
Орлов Г. А. достаточно подробно предоставил информацию по реализации big data в области баз данных для решения конкретной задачи, что демонстрирует эффективность больших данных при использовании NoSQL.
В статье “Big Data: опасности и перспективы”, опубликованной в 2019 г. (https://cyberleninka.ru/article/n/big-data-opasnosti-i-perspektivy), рассмотрена концепция big data со стороны перспектив и опасности при реализации в сфере услуг. Закулисова А. Ю. приводит примеры двоякости использования больших данных, т. к. c одной стороны компании оперируют информацией о пользователях, что несет свои плюсы для аналитики и корректировки бизнес-процессов, но существует опасность в утечке данных пользователей или в не правомерном использовании личных данных пользователей третьими лицами.
В итоге Закулисова А. Ю. рассмотрел данную проблему с точки зрения общества, но не уделил внимание в сфере хранения больших данных.
М. А. Симакина в своей статье «Особенности использования технологий Big Data в маркетинге» выделяет ряд преимуществ, которые компании могут получить, внедрив технологию Big Data:
- Создание наиболее точного портрета целевого потребителя.
- Предсказание реакции потребителей на маркетинговые «сообщения» и предложения того или иного продукта.
- Персонализация рекламных сообщений.
- Оптимизация производства и стратегий распределения.
- Создание цифрового маркетинга и рекламных кампаний.
- Сохранение большого числа клиентов путем наименьших трат.
- Получение лучшего представления о собственном продукте компании.
Тем не менее, необходимо помнить, что, как и в случае с любым другим решением, у больших данных есть свои недостатки.
Во-первых, возникает проблема масштабирования. Работа с большим объемом информации, характерной для больших данных, требует не только значительных объемов хранения, но и постоянного доступа к этим данным. Многие корпоративные центры обработки информации не были изначально спроектированы для обработки таких объемов данных. Следовательно, компаниям приходится не только рассматривать вопрос о расширении собственных корпоративных центров хранения, но и искать оптимизированные подходы, такие как переход к использованию «облачных» хранилищ данных.
Во-вторых, необходима правильная интеграция данных, которые были собраны до использования Big Data. Важно иметь доступ к собранной ранее информации о клиентах, чтобы более эффективно использовать все преимущества больших данных, однако прошлые системы хранения не были рассчитаны для использования их в реальном времени, что может негативно влиять на работу технологии Big Data.
В-третьих, даже при наличии организованной системы данных, при сборе и анализе данных необходимо понимание, как правильно и эффективно работать с полученной информацией, а значит отделу маркетинга придётся научиться кооперироваться со специалистами данной области.
3. Основные проблемы, связанные с использованием Big Data
Проблемы, связанные с использованием системы Big Data, могут быть разделены на три основных категории: объем данных, скорость обработки и неструктурированность. Эти три «V« — объем (Volume), скорость (Velocity) и разнообразие (Variety) — представляют собой ключевые аспекты, на которые следует обратить внимание при работе с Big Data.
Управление обширными объемами информации представляет собой сложную задачу, требующую специализированных условий и ресурсов. Вопросы, связанные с пространством и возможностями, становятся критическими. Скорость обработки данных важна не только для устранения задержек и повышения производительности, но также для обеспечения интерактивности и оперативного реагирования на требования рынка.
Проблема отсутствия структурированности данных возникает из-за разнообразия источников, форматов и качества информации. Для эффективной обработки таких данных необходимо привести их к единому формату и использовать специализированные аналитические инструменты и системы.
Тем не менее, существует и проблема, связанная с масштабами данных. Определение точного «объема» данных является сложной задачей, и, следовательно, затруднительно предсказать необходимые технологии и финансовые вложения для будущих разработок. Тем не менее, уже сейчас существуют инструменты обработки данных, способные справиться с конкретными объемами информации (например, терабайт), и эти инструменты продолжают активно развиваться.
Одной из сложностей является отсутствие четких принципов в обработке такого объема данных, связанного с разнообразием потоков. Возникает вполне логичный вопрос о том, какие данные стоит собирать и сохранять, а какие можно пренебречь, чтобы извлечь ценные сведения. Это требует разработки новых методов анализа больших данных и формирования новых областей, например, науки о Big Data, как указывают исследователи из некоторых американских университетов.
Временные задержки в реализации проектов Big Data в компаниях обусловлены не только вышеуказанными факторами, но также высокими ресурсными затратами. Выбор данных для обработки и определение алгоритмов анализа представляют собой отдельные трудности, поскольку часто отсутствует ясное представление о том, какие данные являются значимыми, а какие можно проигнорировать. Также, одной из серьезных проблем также является нехватка квалифицированных специалистов, способных провести глубокий анализ данных, создать отчеты и извлечь выгоду из Big Data.
Этический компонент также представляет собой проблему в области работы с Big Data. Сбор данных, особенно без согласия пользователей, может рассматриваться как нарушение личной жизни. Некоторые поисковые системы активно собирают информацию о пользователях, включая их интересы, покупки и личные данные, с целью предоставления контекстной рекламы. Возникает вопрос о том, где проходит граница между сбором данных и нарушением приватности. Безопасность хранения и использования данных также становится актуальной проблемой, учитывая современные угрозы вирусной активности и хакерских атак.
В общем, система Big Data представляет свои сложности и порождает множество вопросов. Тем не менее, с использованием соответствующих методов анализа, разработки новых инструментов и обеспечения этичной и безопасной обработки данных, Big Data может стать мощным инструментом для принятия обоснованных решений в маркетинге и других областях бизнеса.
4. Чем отличается SQL в больших данных от обычного SQL.
Как упоминалось ранее, для обработки больших данных широко используется подход с распределенными вычислениями. Вычислительные задачи распределяются между несколькими серверами, где одна база данных размещена на нескольких узлах. Результаты запросов вычисляются параллельно несколькими серверами. Парадигма MapReduce описывает алгоритмы распределенных вычислений.
При работе с большими объемами данных важно учесть, что практически каждая база данных хранит информацию на нескольких серверах. Допустим, имеются три сервера и таблица клиентов. Вся таблица равномерно распределена между этими серверами, так что каждый из них хранит треть общего объема данных. Для получения результата запроса необходимо извлечь каждую часть данных с каждого сервера и объединить их на одном сервере, где будет сформирован итоговый результат.
Пример простейшего SQL-запроса для такой структуры:
SELECT * FROM CLIENTS;
Даже такой элементарный запрос разбивается на три обязательные части MapReduce:
— Map
— Shuffle
— Reduce
Каждая из перечисленных операций имеет свои особенности в распределении и параллелизации, что делает важным понимание их сути.
- Стадия Map. Часто представляет собой чтение данных с жесткого диска. Кроме чтения, здесь могут выполняться однострочные трансформации и фильтры, такие как операции без операндов distinct, join, group by, order by, и без агрегирующих функций. Операции на этой стадии отлично параллелятся и не нагружают базу данных, поскольку каждый сервер читает только ту часть данных, которая хранится у него на жестком диске. Данные обычно распределены равномерно на каждом сервере, что обеспечивает равномерное распределение нагрузки между всеми серверами.
- Стадия Shuffle. На этой стадии не происходит никаких вычислений, но все данные перемещаются между серверами так, чтобы их можно было использовать для формирования окончательного результата на стадии Reduce. Полное понимание этого шага становится ясным только после вхождения в стадию Reduce.
- Стадия Reduce. Reduce может вызвать заметные проблемы с производительностью базы данных. Здесь выполняются группирующие операции и операции, записывающие результат. Некоторые операции не могут выполняться параллельно на нескольких серверах, поэтому для их выполнения необходимо собрать весь объем данных на одном сервере. Если данные не умещаются на один сервер, запрос может вызвать ошибку.
Использование эффективных стратегий запросов и оптимизации для устранения ошибок типа «Out of Memory» — важная задача. Одним из подходов может быть изменение запроса таким образом, чтобы снизить нагрузку на сервер, выполняющий запрос. В приведенном вами примере предлагается создать отдельную таблицу, CLIENTS_RESULT, которая будет хранить данные из исходной таблицы CLIENTS. Это позволит сократить нагрузку при выводе результатов запроса на сервере.
Эффективный запрос можно представить как:
INSERT INTO CLIENTS_RESULT
SELECT * FROM CLIENTS;
COMMIT;
При таком подходе таблица CLIENTS_RESULT будет храниться на трех серверах, что дает возможность записывать данные с каждого сервера по отдельности. Это может улучшить производительность при обработке запроса и снизить риск возникновения аномалий при правильной обработке операции добавления новых данных.
В таком случае необходимость в централизации данных отсутствует, и все вычисления будут эффективно распределяться. Фаза Map успешно параллелизируется, в то время как фаза Reduce (запись результатов) теперь выполняется распределено на серверах, где данные были изначально прочитаны. Это позволяет избежать этапа Shuffle (передача данных между серверами перед записью результатов), что дополнительно ускоряет вычислительный процесс. Процесс описан на рисунке 3.
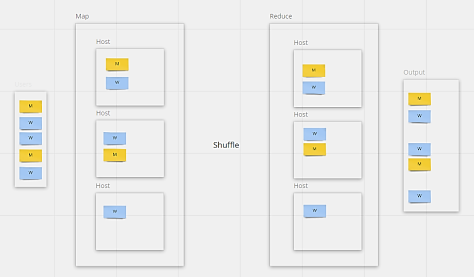
Рис. 3. Процесс выборки и чтения данных по парадигме MapReduce
Таким образом, применение парадигмы MapReduce целесообразно для параллелизации обработки запросов, что повышает скорость обработки при использовании нескольких серверов для обработки обширных данных. Следует отметить, что необходимо учитывать возможные ошибки, которые могут возникнуть при работе с обширными данными, например, при выборке данных в рамках парадигмы MapReduce.
Также стоит упомянуть, что в сфере баз данных существует несколько подходов к использованию больших данных в реляционных и нереляционных СУБД. Один из ключевых аспектов при работе с SQL — масштабируемость и оптимизация. В случае NoSQL проблема оптимизации решается за счет распределения базы данных между несколькими узлами, что улучшает масштабируемость и снижает нагрузку. Для реализации нереляционной СУБД с использованием концепции больших данных применяется BDA. Главное отличие заключается в горизонтальной масштабируемости и динамической схеме данных, что устраняет необходимость в изменении самих данных.
В представленных источниках упоминается интеграция больших данных в реляционные СУБД, что вызывает трудности с SQL СУБД. Больше предпочтений уделяется NoSQL СУБД из-за их совместимости и открытого исходного кода, который доступен в свободном доступе. Также важную роль играет экономическая эффективность при использовании NoSQL и SQL СУБД, где NoSQL оказывается в 2 раза более эффективной с точки зрения окупаемости. Следовательно, для интеграции больших данных предпочтительнее использовать NoSQL СУБД.
5. Реализация подхода SQL в концепции big data, с использованием NoSQL структур.
Для реализации концепции Big Data, можно использовать реляционную СУБД Postgresql, которая поддерживает некоторые аспекты, для реализации методов обработки и хранения больших объемов данных.
Один из возможных вариантов реализации на практике данной концепции, это хранение данных в виде объектов, например JSON. При таком подходе, можно достичь структурированности данных и гибкости организации структур с данными, в зависимости от необходимости. Организация данных, как структур или объектов, может дать большую гибкость для модернизации архитектуры хранилища данных или организации какой-либо системы хранения, обработки различной информации.
Для примера реализации концепции big data, был взят набор данных, представляющий собой, информацию о литературных произведениях, с отзывами и рейтингом от различных пользователей, которые взаимодействовали или знают о данной книге или авторе. Также, в данном наборе присутствуют категории, которые относятся к определенным литературным произведениям.
При помощи средств на базе СУБД Postgresql, данный набор данных распределен в базе данных data, которая представляет собой примером, как реализация хранения объектно-ориентированной структуры в сфере реляционной базы данных
На рисунке 4 представлена структура базы данных data в СУБД Postgresql, в которую входит схема books, содержащая следующий перечень таблиц:
books.answers;
books.books;
books.books_tags;
books.ratings;
books.reviews;
books.tags.
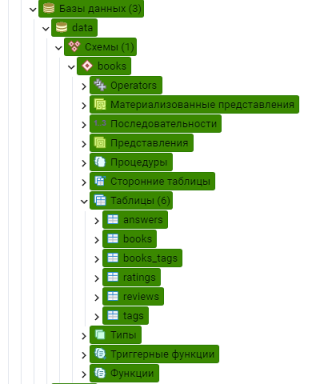
Рис. 4. Структура базы данных data и перечнем таблиц в схеме books
Каждая таблица в схеме books имеет один атрибут data, представляющий собой тип данных формата JSON. Пример одной записи из таблицы books.books:
"{""item_id"": 16827462, ""URL:"": ""https://www.goodreads.com/book/show/11870085-the-fault-i11235712Nan11235712-our-stars"", ""title"": ""The Fault in Our Stars"", ""authors"": ""John Green"", ""lang"": ""eng"", ""img"": ""https://images.gr-assets.com/books/1360206420m/11870085.jpg"", ""year"": 2012, ""description"": ""There is an alternate cover edition \u0001.\n\""I fell in love the way you fall asleep: slowly, then all at once.\""\nDespite the tumor-shrinking medical miracle that has bought her a few years, Hazel has never been anything but terminal, her final chapter inscribed upon diagnosis. But when a gorgeous plot twist named Augustus Waters suddenly appears at Cancer Kid Support Group, Hazel's story is about to be completely rewritten.\nInsightful, bold, irreverent, and raw, The Fault in Our Stars is award-winning author John Green's most ambitious and heartbreaking work yet, brilliantly exploring the funny, thrilling, and tragic business of being alive and in love.""}"
Из вышеприведенного примера можно сделать предположение, что каждая запись в такой таблице может иметь различные объекты в виде ключ-значение, что предает гибкости и неоднородности данных, как при работе с файлами, имеющими ветвистую структуру. Такие объекты могут содержать в себе множество несвязанных между собой пар ключ-значение, что так же ведет к избыточности данных при обработке или хранении полезной информации.
Стоит упомянуть, что данный набор данных из таблицы books.books связан с другими таблицами через пару ключ-значение «item_id»: value, где «item_id» — ключ, а value значение, которое может быть представлено как строка, число, ссылка, путь до файла, логическим значением (true/false).
Для работы с такими данными средствами СУБД Postgresql представляет следующий пример, приведенный на рисунке 5.
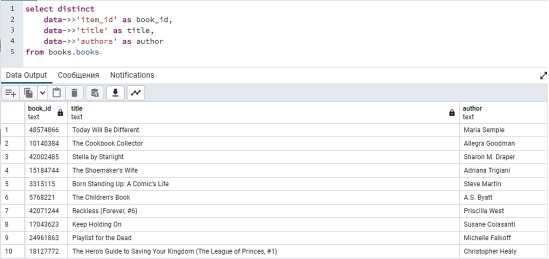
Рис. 5. Запрос на выборку из таблицы books.books в схеме books
Есть определенные достоинства и недостатки при работе с такой организацией данных:
— При работе с объектами можно использовать ORM системы на примере различных фреймворков, которые поддерживают формат JSON, что в свою очередь избавит разработчика ППО от необходимости работы со строками классической реляционной базы данных;
— Нужно учитывать проблемы с оптимизацией, при выборки огромного набора результирующих строк, не отсортированных или не проиндексированных значений, с подходом выборки значений каждого ключа и преобразованием в строку или число;
Рассмотрим ситуацию, в которой нужно получить из набора данных информацию, которая связана через пару ключ-значения в разных файлах на примере таблиц books.books, books.books_tags и books.tags.
При использовании объектов можно использовать подзапросы для выборки значений в временную таблицу, формирующуюся в подзапросе, и связывать значения напрямую через join конструкции в запросе.
На рисунке 6 приведен запрос, который включает в себя подзапросы из каждой таблицы, которая в блоке where завязывается с другими таблицами через атрибуты, которые находятся в других таблицах.
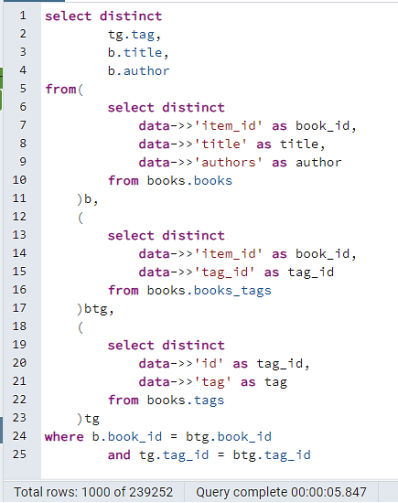
Рис. 6. Выборка значений с подзапросами
На рисунке 7 приведен запрос, который напрямую связывает таблицы через join конструкцию, используя равенство пар ключ-значение в каждой таблице с приравниванием значений атрибутов JSON объекта.
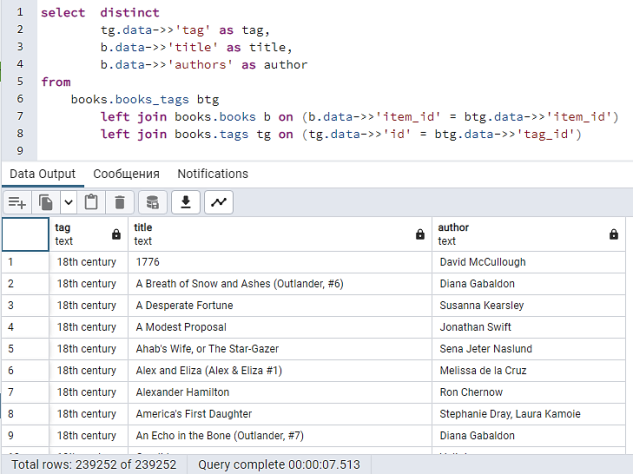
Рис. 7. Выборка значений с конструкцией join
Из выше приведенных примеров, можно сделать вывод о том, что можно использовать разные подходы к выборке, которые удобны для написания компактных запросов, так и для более оптимизированных за счет использования стандартных приемов при работе с СУБД Postgresql.
Стоит заметить, что существует множество различных способов оптимизации запросов за счет распараллеливания процессов чтения и записи на несколько кластеров или узлов в базах данных, как пример, использование вышеописанной парадигмы MapReduce и не только.
Заключение
Исходя из всего вышеперечисленного, можно выдвинуть предположение о том, что концепция больших данных может быть реализована в различных СУБД с использованием неструктурированных данных по типу ключ-значение на примере JSON объектов.
Эти данные имеют разнородную и не структурированную информацию в огромных количествах, что создает проблему при реализации этих данных в традиционных БД, т. к. реляционные СУБД на базе SQL имеют проблемы с масштабируемостью и оптимизацией, ограничивающие возможности при использовании больших данных.
Для реализации big data подойдет реляционная СУБД на базе NoSQL, из-за своего потенциала к масштабируемости и не строгой структуре при разработке схем данных.
Также рассмотрены некоторые возможности для реализации концепции big data в СУБД Postgresql с демонстрацией структуры базы данных, состоящей из перечней таблиц, которые содержат в себе объекты формата JSON
Литература:
- Век качества. Феномен big data. URL: https://cyberleninka.ru/article/n/fenomen-big-data (дата обращения: 22.10.2022).
- Д. Е. Намиот и др. International Journal of Open Information Technologies. Стандарты в области больших данных. Д. Е. Намиот, В. П. Куприянов, Д. Е. Николоаев, Зубарева Е. В., URL: https://cyberleninka.ru/article/n/standarty-v-oblasti-bolshih-dannyh (дата обращения: 22.010.2022).
- Орлов Г. А. и др. Наукоемкие технологии в космических исследованиях Земли. Применение Big Data при анализе больших данных в компьютерных сетях. / Орлов Г. А., Красов А. В., Гольфанд А. М., URL: https://cyberleninka.ru/article/n/primenenie-big-data-pri-analize-bolshih-dannyh-v-kompyuternyh-setyah (дата обращения: 22.10.2022).
- Закулисова А. Ю. Международный журнал прикладных наук и технологий «Integral». Big Data: опасности и перспективы. URL: https://cyberleninka.ru/article/n/big-data-opasnosti-i-perspektivy (дата обращения: 22.10.2022).
- Назаренко Ю. Л., European science. Обзор технологии «большие данные» (Big Data) и программно-аппаратных средств, применяемых для их анализа и обработки. URL: https://cyberleninka.ru/article/n/obzor-tehnologii-bolshie-dannye-big-data-i-programmno-apparatnyh-sredstv-primenyaemyh-dlya-ih-analiza-i-obrabotki (дата обращения: 22.10.2022).
- Котенко И. В., Ушаков И. А. Базы данных безопасности корпоративной сети: применение SQL и NoSQL технологий // Региональная информатика и информационная безопасность: сборник трудов. 2017. № 4. С. 254–255.
- Назаров А. Д., Товмасян Н. Д. Цифровой маркетинг как современный тренд // Московский экономический журнал. 2020. № 6. URL: https://cyberleninka.ru/article/n/tsifrovoy-marketing-kak-sovremennyy-trend (дата обращения: 22.10.2022).
- Большие данные // Википедия, 2017. URL: http://ru.wikipedia.org/?oldid=87934960/ (дата обращения: 29.09.2021).
- Медетов А. А. Термин Big Data и способы его применения // Молодой ученый, 2016. № 11. С. 207–210.
- Намиот Д. Е., Шнепс-Шнеппе М. А. Об отечественных стандартах для Умного Города // International Journal of Open Information Technologies. 2016. -Т. 4. — № 7. С.32–37.
- BSI Big Data and standards market research, 2016
- ITU Big Data http://www.itu.int/en/ITU-T/techwatch/Pages/big-data-standards.aspx (дата обращения: 28.09.2022).
- Tene, Omer, and Jules Polonetsky. «Big data for all: Privacy and user control in the age of analytics». Nw. J. Tech. & Intell. (2012): xxvii
- Smith, John R. «Riding the multimedia big data wave». Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. ACM, 2013.

