В данной статье приводится обоснование важности соблюдения паттернов микросервисной разработки.
Ключевые слова: микросервисная архитектура, паттерн, программный продукт.
Микросервисная архитектура, фактически, является подвидом сервис-ориентированной архитектуры программных продуктов. Под микросервисами стоит понимать слабо связанные и легко изменяемые модули, размер которых стремится к минимуму [1]. Программный продукт на базе микросервисной архитектуры отличается особой простотой добавления нового и изменения существующего функционала именно благодаря повышенной гранулярности, что и отличает его от классических монолитных программных продуктов. Особенно ценным это свойство стало за последние десять лет — во времена практически повсеместного применения DevOps и agile-методик разработки. Обычно микросервисы размещаются в средах управления контейнерами, например, в чистом Kubernetes или его надстройке OpenShift [2]. Полезной практикой считается включение контейнерной среды в процессы непрерывной интеграции — это обеспечивает автоматизацию развёртывания микросервисов и их быстрое обновление. Однако, для извлечения всех преимуществ микросервисной архитектуры, необходимо придерживаться определённых правил — паттернов проектирования микросервисных программных продуктов.
Суть применения паттерна API Gateway заключается в создании единой точки входа для запросов от внешних систем или пользователей. Для реализации данного паттерна создаётся отдельный микросервис-шлюз, выполняющий функции маршрутизации внешних запросов и аутентификации (в некоторых случаях) [3].
Таким образом, микросервис-шлюз остаётся единственным сервисом, доступным к коммуникации извне программного продукта, что способствует не только упрощению дальнейшей поддержки и документирования, но и повышению уровня безопасности программного продукта. На рис. 1 представлена наглядная иллюстрация организации связи микросервисов и внешних систем с учётом применения паттерна API Gateway. Важно отметить, что стоит избегать выполнения любой бизнес-логики микросервисом-шлюзом, так как его основная цель — передача данных целевым микросервисам. В некоторых случаях возможно использование более одного микросервиса-шлюза, когда программный продукт имеет несколько вариантов взаимодействия с пользователем. Применение паттерна API Gateway имеет смысл в любом программном продукте с микросервисной архитектурой ввиду того, что каждый микросервис выполняет свою отдельную функцию, подобно модулям монолитного продукта, а внешняя система или пользователь должны иметь единую точку входа для выполнения всех видов запросов к программному продукту.
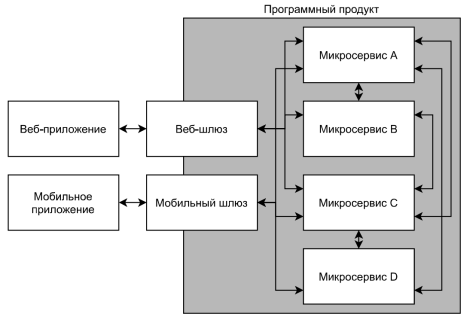
Рис. 1. Схематическое отображение концепции паттерна API Gateway
Позитивные эффекты использования паттерна API Gateway:
− упрощение способа коммуникации пользователей и внешних систем с программным продуктом;
− предоставление оптимальных точек входа для всех вариантов взаимодействия с программным продуктом;
− стандартизация протоколов взаимодействия с программным продуктом вне зависимости от того, как выстроена коммуникация микросервисов между собой.
Негативные побочные эффекты применения паттерна API Gateway:
− повышается сложность программного продукта: микросервис-шлюз нужно так же разрабатывать, поддерживать и разворачивать, как и остальные микросервисы;
− повышается время ожидания ответа от программного продукта: все запросы производятся через микросервис-шлюз, который тратит время на их обработку.
Использование паттерна Database per service означает, что каждый микросервис в программном продукте имеет свою собственную базу данных. Чтобы одному микросервису получить данные другого микросервиса, нужно произвести обращение именно к нему, а не к его базе данных напрямую [3]. При реализации данного паттерна появляется возможность использовать подходящие типы баз данных для всех типов задач в рамках одного программного продукта.
Преимущества использования паттерна Database per service:
− уменьшение связанности между микросервисами: изменения в базе данных одного микросервиса не влияют на остальные микросервисы;
− каждый микросервис может использовать наиболее подходящий для его функционала тип базы данных.
Среди негативных эффектов реализации данного паттерна: усложнение процессов управления ввиду наличия нескольких типов баз данных.
В подавляющем большинстве случаев внешний запрос обрабатывается в программном продукте более чем одним микросервисом, что вносит определённые сложности в процесс отладки программного продукта. Соблюдение паттерна Distributed tracing позволяет облегчить отслеживание хода выполнения внешних запросов внутри программного продукта [3]. Становится возможным узнать, когда какой запрос и каким микросервисом был обработан благодаря обогащению логов микросервисов трассирующими данными. Наглядная иллюстрация работы данного паттерна представлена на рис. 2.
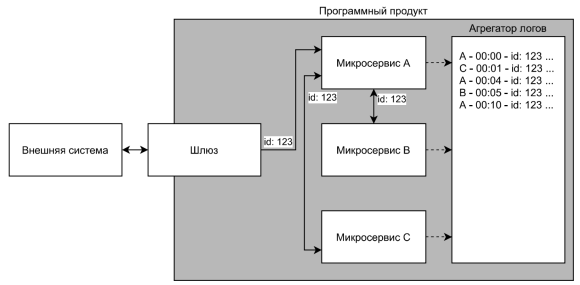
Рис. 2. Схематическое отображение концепции паттерна Distributed tracing
Соблюдение паттерна Distributed tracing имеет следующие преимущества:
− становится проще понять поведение программного продукта при возможных девиациях;
− упрощается процесс поиска источников задержек в сложных программных продуктах.
Однако, стоит учитывать, что реализация паттерна Distributed tracing влечёт за собой расширение технологического стека программного продукта, так как для обогащения, сбора и анализа логов микросервисов требуется использование сторонних технических решений.
Взяв во внимание всё вышеизложенное, можно сделать однозначный вывод: проектирование и реализация программного продукта с микросервисной архитектурой подразумевает обязательное соблюдение определённых правил — паттернов микросервисной разработки — благодаря чему программный продукт и приобретает все преимущества, свойственные микросервисным решениям.
Литература:
- Ньюмен С. Создание микросервисов — СПб.: Питер, 2016.
- Маркелов А. А. Введение в технологии контейнеров и Kubernetes — М.: ДМК Пресс, 2019.
- Ричардсон К. Микросервисы. Паттерны разработки и рефакторинга — СПб.: Питер, 2019.

