Анализ данных, полученных из многочисленных источников данных, приводит к работе с огромными объемами неструктурированных необработанных данных, которые являются большими с точки зрения объема, разнообразия и скорости сбора. Процесс анализа таких данных в последнее время является популярной областью исследований, известной как анализ больших данных. Одной из наиболее важных задач интеллектуального анализа данных является классификация [1].
Классификация ближайших соседей (KNN) является одним из самых популярных алгоритмов классификации [2]. Поскольку классический алгоритм KNN полностью основан на близости отдельных экземпляров, он сильно страдает от высоких вычислительных затрат. Кроме того, поскольку стратегия принятия решений алгоритмом основана на близости отдельных экземпляров, а не на более сильных представлениях классов, точность классификации алгоритма также не подходит для современного анализа больших данных, который требует быстрых и точных результатов.
В этой статье предлагается новый алгоритм на основе KNN и MapReduce, названный алгоритмом ZKNN. Алгоритм ZKNN пытается исправить точность классификации классического классификатора KNN.
Основная идея алгоритма ZKNN состоит в том, чтобы основывать решение о классификации классического алгоритма KNN на представлениях классов, вычисляя центроиды ближайших обучающих экземпляров Z, принадлежащих классам K ближайших экземпляров, обнаруженных KNN. Другими словами, классический подход к голосованию большинством заменяется более строгим классификационным решением, что также не требует больших затрат в вычислительном отношении.
Алгоритм ZKNN
Предложенный алгоритм ZKNN является алгоритмом распределенной классификации на основе KNN, который предназначен для работы в среде MapReduce. Hadoop MapReduce — это программная среда для простого написания приложений, которые параллельно обрабатывают огромные объемы данных на больших кластерах аппаратного оборудования надежным, отказоустойчивым способом [3].
Структура MapReduce алгоритма ZKNN для m количества экземпляров в наборе обучающих данных и n количества экземпляров в наборе данных тестирования представлена на рисунке 1.
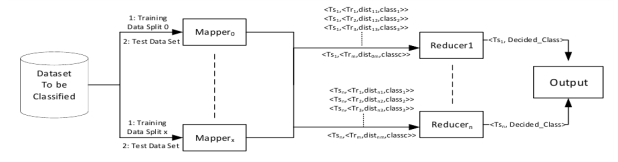
Рис. 1. Схема ZKNN
Как видно на рисунке 1, подзадачи алгоритма ZKNN состоят из функций Mapper и Reducer.
Функция Mapper отвечает за получение разделений обучающих наборов данных от драйвера MapReduce, который является основной функцией для настройки среды и управления распределенной обработкой, выполняемой поверх платформы Hadoop, и вычисления расстояний между обрабатываемым экземпляром тестирования.
В соответствии с MapReduce Framework выходные данные функции Mapper должны быть вектором <key, value=""> [3]. В алгоритме ZKNN выходной ключ Mapper является идентификатором экземпляра тестирования, а значение является объектом, который содержит используемый экземпляр обучения. Расстояние между тестированием и экземплярами обучения и есть идентификатор класса, к которому принадлежит экземпляр обучения. </key,>
После этого инфраструктура MapReduce перетасовывает выходные пары <key, value="">, испускаемые функциями сопоставления, так что пары с общими ключами передаются в одну и ту же функцию Reducer. Другими словами, один Reducer будет обрабатывать все рассчитанные расстояния, принадлежащие одному и тому же экземпляру тестирования. </key,>
Как объяснено выше, функция Mapper отвечает за расчет расстояний между обучающим и тестовым экземплярами.
В качестве примера для расчета расстояния, если рассматриваются один экземпляр тестирования tsi и один обучающий экземпляр trj, то расстояние между этими двумя экземплярами вычисляется по уравнению:
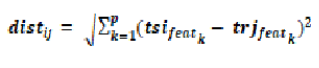
Функция Reducer содержит фазу принятия решения о классификации для тестовых экземпляров, где можно увидеть основной вклад предложенного алгоритма ZKNN.
Вход функции Reducer представляет собой список всех пар <key1, value1="">, испускаемых функцией Mapper модели MapReduce. Стоит еще раз упомянуть, что один Reducer получает список пар, принадлежащих общему значению ключа. Другими словами, один Reducer получает расстояния одного тестового экземпляра до всех обучающих экземпляров, рассчитанных Mapper-ми. После получения входных данных функция Reducer находит K ближайших соседей из всех обучающих экземпляров, исследуя минимальные K расстояний среди всех значений в списке. Затем Reducer ZKNN обнаруживает, к каким классам относятся эти K соседей (например, класс A). </key1,>
Основной вклад классификатора ZKNN зависит от правильного представления обнаруженных классов A, B и C, а не от расстояния до отдельных экземпляров обучающих данных. Основная идея этой стратегии обусловлена тем фактом, что, когда размер данных велик, и особенно когда данные представлены множественным числом классов и большим количеством признаков, некоторые данные могут иметь сходную близость к экземплярам разных классов. В таких случаях минимальное расстояние от отдельных экземпляров может неправильно означать, что тестовый экземпляр будет принадлежать к тому же классу.
Параметр Z в классификаторе ZKNN представляет собой количество экземпляров каждого из классов A, B и C, которые имеют самые близкие расстояния до экземпляра теста. Как было объяснено ранее в функции Mapper алгоритма, для каждого экземпляра теста расстояния до каждого обучающего экземпляра вычисляются и передаются в функцию Reducer. То есть каждый Reducer получает список, который уже отсортирован, так что Reducer-ы могут напрямую брать первое число Z элементов из каждого класса. Следовательно, без дополнительных затрат, Reducer может использовать уже имеющуюся информацию о близости.
Повторяя вычисление центроида для каждого класса, Reducer ZKNN вычисляет центроиды класса, используя первые элементы Z. Вклад параметра Z просто предполагает, что вместо использования полной совокупности классов для вычисления центра класса, используя только Z экземпляров класса, Reducer вычисляет центр тяжести для этого класса с гораздо более низкими затратами на вычисление и при этом сохраняет корректное значение.
Результаты
Эффективность алгоритма ZKNN измеряется с точки зрения точности классификации, которая представляет собой отношение количества правильных классификаций к количеству всех классификаций.
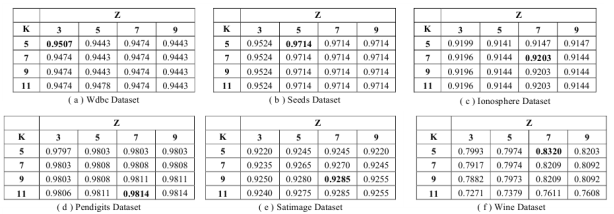
Рис. 2. Результаты точности классификации ZKNN
Что касается общей точности классификации, на рисунке 2 видно, что ZKNN удалось правильно определить класс более 92 % (83 % — частный случай) проверенных данных во всех наборах данных. Что касается параметра Z, можно заметить, что алгоритму ZKNN удается достичь высокой точности классификации с 5–7 ближайшими соседями в представлении класса, что также показывает, что добавление параметра Z не увеличивает стоимость вычислений значительно. Также ZKNN демонстрирует реалистичную применимость к приложениям с большими объемами данных.
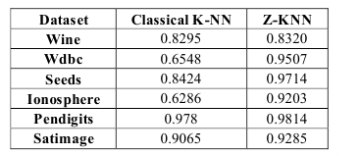
Рис. 3. Сравнение показателей точности KNN и ZKNN
Как видно из сравнений производительности, ZKNN работает лучше почти во всех наборах данных, что демонстрирует, что предлагаемое представление экземпляра Z значительно улучшает характеристики точности классического KNN и некоторых его вариаций.
Единственный набор данных, в котором предложенный алгоритм ZKNN работает не сильно лучше — это набор данных Wine. Из результатов, которые наблюдались в [4], можно сделать вывод, что это скорее всего связано с особенностями распределения данных набора Wine.
Заключение
Результаты производительности ZKNN показывают, что основной вклад, который предлагает использовать центроидное представление классов данных вместо того, чтобы полагаться на расстояния отдельных экземпляров, доказывает улучшение точности классификации по сравнению с классическим алгоритмом KNN. ZKNN будет внедрен в систему классификации заведений и будет использоваться в области сервисного обслуживания населения.
Литература:
- D. Singh and K. Reddy, «A survey on platforms for big data analytics», Journal of Big Data vol. 1, no. 8, 2014.
- X. Wu et. Al., «Top 10 algorithms in data mining», Knowledge and Information Systems,vol. 14, no. 1, pp 137, 2008.
- T. White, «Hadoop: A Definitive Guide», 4th ed., O'Reilly, 2015.
- T.Tulgar, A.haydar and İ.Erşan, «Data Distribution Aware Classification Algorithm based on K-Means», International Journal of Advanced Computer Science and Applications, Article in Press, 2017.

