В статье описан метод извлечения ключевых фраз из постов социальной сети «Твиттер», основанный на построении и обучении нейронной сети с архитектурой Joint-layer.
Ключевые слова:обработка естественного языка, нейронные сети, ключевые слова, ключевые фразы.
С постоянным увеличением потоков информации, наполняющих сеть Интернет, всё более актуальной становится задача извлечения из единицы контента некоторой ключевой части, позволяющей с высокой точностью определить основную мысль данного текста. Эту ключевую часть обычно называют ключевой фразой(keyphrase).
С помощью ключевых фраз конечный пользователь может получить концентрированную и исчерпывающую информацию об основных мыслях или тематике того или иного текста. Такую задачу постоянно вынуждены решать поисковые системы, новостные аггрегаторы и ресурсы, анализирующие мнение пользователей социальных сетей по какому-либо вопросу. Существует множество видов контента, из которого можно извлечь ключевую часть: это могут быть веб-страницы, научные статьи, книги или даже фильмы. В данной работе будут рассмотрены методы извлечения ключевых фраз из коротких (объёмом до 140 символов) текстов, в частности постов, размещаемых в социальной сети Twitter.
В то время как методы извлечения ключевых фраз из текстов на английском языке достаточно глубоко изучены (как для текстов большого объёма, так и для небольших текстов, например твитов), подобных исследований для русскоязычных текстов по-прежнему очень немного. Следует обратить внимание на то, что мы отделяем задачу извлечения ключевых фраз от таких задач как извлечение ключевых слов(на эту тему есть достаточно исследований для русского языка, например [1, 2, 3]), извлечения терминологии предметной области и задачи извлечения коллокаций (словосочетаний, имеющих признаки синтаксически и семантически целостной единицы).
Описание Joint-layerneuralnetworks
Рекуррентная нейронная сеть с совмещёнными слоями (Joint-layer Recurrent Neural Networks) является модификацией сложенной рекуррентной нейронной сети (Stacked Recurrent Neural Network) с двумя скрытыми слоями, т.к такая архитектура позволяет лучше приспособиться к поставленной выше задаче. Joint-Layer RNN имеет 2 выходных слоя и результирующий слой, учитывающий результаты, получаемые на обоих выходных слоях.
Рассмотрим Stacked RNN, состоящую из L слоёв и имеющую выходной слой для каждого скрытого слоя. В этом случае l-й слой определяется как:
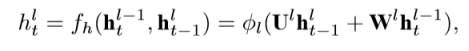
где ![]() является состоянием скрытого слоя l в момент времени t.
является состоянием скрытого слоя l в момент времени t. ![]() являются матрицами весов для данного слоя в момент времени t — 1 и для предыдущего слоя в момент времени t соответственно. При l = 1 это значение вычисляется как:
являются матрицами весов для данного слоя в момент времени t — 1 и для предыдущего слоя в момент времени t соответственно. При l = 1 это значение вычисляется как:
![]()
φl это поэлементная нелинейная функция, например сигмоид. Значения для
выходного слоя с номером l вычисляются как:
![]()
где ![]() это матрица весов для скрытого слоя
это матрица весов для скрытого слоя ![]() .
. ![]() также может быть поэлементной нелинейной функцией, например softmax.
также может быть поэлементной нелинейной функцией, например softmax.
Joint-layer RNN (рис.1) это расширение для Stacked RNN с двумя скрытыми слоями. В момент времени t тренировочное значение ![]() является совокупностью значений для элементов, находящихся внутри рассматриваемого окна(window-size). В данной работе в качестве таких значений используются векторные представления слов, составленные с помощью метода word2vec [1].
является совокупностью значений для элементов, находящихся внутри рассматриваемого окна(window-size). В данной работе в качестве таких значений используются векторные представления слов, составленные с помощью метода word2vec [1].
Выходные значения ![]() и
и ![]() , сообщают нейронной сети о том, является ли рассматриваемое слово ключевым или является ли оно частью ключевой фразы соответственно.
, сообщают нейронной сети о том, является ли рассматриваемое слово ключевым или является ли оно частью ключевой фразы соответственно. ![]() может иметь одно из 2-х значений: True или False, в зависимости от того, является ли данное слово ключевым или нет.
может иметь одно из 2-х значений: True или False, в зависимости от того, является ли данное слово ключевым или нет. ![]() может иметь одно из 5-ти возможных значений: Single, Begin, Middle, End или Not, сообщающих нейронной сети о том, является ли рассматриваемое слово одиночным ключевым, началом ключевой фразы, её серединой (т.е стоящим в ней не первым и не последним), концом фразы или вообще не является ключевым для рассматриваемого отрывка.
может иметь одно из 5-ти возможных значений: Single, Begin, Middle, End или Not, сообщающих нейронной сети о том, является ли рассматриваемое слово одиночным ключевым, началом ключевой фразы, её серединой (т.е стоящим в ней не первым и не последним), концом фразы или вообще не является ключевым для рассматриваемого отрывка.
Т.к решаемой задачей является извлечение ключевых фраз из последовательности слов, авторы адаптировали архитектуру нейронной сети для одновременного нахождения ключевых слов, и извлечения ключевых фраз. Значения скрытых слоёв определяются как:
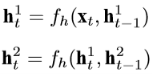
Значения выходного слоя определяются как:
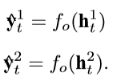
Обучение нейросети
Обозначим параметры обучения как θ.
![]()
где X это векторные представления слов, а остальные переменные описаны в предыдущем пункте. В одних и тех же выражениях размечаются как ключевые слова, так и ключевые фразы (фразы состоят из ключевых слов). На выходе
первого скрытого слоя мы получаем из модели информацию о ключевых словах, на втором — о ключевых фразах. Затем результаты, полученные на выходе из этих слоёв, комбинируются в финальный результат, вычисляемый как:
![]()
где α- линейный фактор веса. Для данных N тренировочных последовательностей D = ![]() значения
значения ![]() (θ) и
(θ) и ![]() (θ) определяются как:
(θ) определяются как:
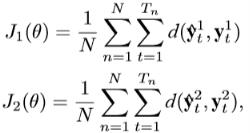
где d(a, b) это некоторая мера близости(например евклидово расстояние или перекрёстная энтропия). Данные формулы демонстрируют, что мы вычисляем ключевые слова и извлекаем ключевые фразы на разных уровнях одновременно, что позволяет достигнуть более высоких результатов, по сравнению с другими методами решения задачи извлечения ключевых фраз [2].
Создание модели иобучение
На данном этапе создание модели и её обучение проводилось в полном соответствии с [2], чтобы проверить насколько точно данный алгоритм, изначально предназначенный для английского языка, может быть применён к русскоязычным твитам без каких-либо изменений(в качестве русскоязычного корпуса твитов был взят корпус Юлии Рубцовой, находящийся в свободном доступе по адресу https://study.mokoron.com). В качестве переменных обучения были взяты следующие значения:

![]()
![]()
Все переменные были взяты из [2], т. к. модель, представленная авторами статьи, показала наилучшие результаты именно при таких параметрах обучения. В качестве функции потерь (loss function) использовалась softmax cross-enthropy(перекрёстная энтропия). Функция Softmax вычисляется как:
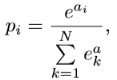
где вектор вещественных чисел размерности N преобразуется в вектор той же размерности, но каждая компонента ![]() вектора p представлена числом в интервале [0,1] и сумма координат равна 1. Перекрёстная энтропия между двумя распределениями вероятностей измеряет среднее число бит, необходимых для опознания события из некоторого набора если используемая схема кодирования базируется на заданном распределении вероятностей y, вместо «истинного» распределения p, где p является вектором получающимся в результате преобразования с помощью функции Softmax. Функция потерь в таком случае выглядит так:
вектора p представлена числом в интервале [0,1] и сумма координат равна 1. Перекрёстная энтропия между двумя распределениями вероятностей измеряет среднее число бит, необходимых для опознания события из некоторого набора если используемая схема кодирования базируется на заданном распределении вероятностей y, вместо «истинного» распределения p, где p является вектором получающимся в результате преобразования с помощью функции Softmax. Функция потерь в таком случае выглядит так:
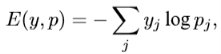
где p — является предположением нейронной сети, а y — вектором меток, преобразованным с помощью Softmax. Результаты обучения нейросети, представлены на рис. 2.
Результаты
Окончательный результат после 150 эпох обучения составил 68 %accuracy, 78.6 %precision, 71.7 % recall и 74 % f-measure(рис.1). Если взглянуть на результаты, полученные в [2] (Precision — 80,74 %, Recall — 81,19 %, F-Measure — 80,97 %), можно заметить, что значения аналогичных метрик довольно близки к результатам, полученным в настоящей работе, откуда можно сделать вывод о том, что результаты работы алгоритма для русскоязычных твитов стоит признать удовлетворительными.Также необходимо пояснить, что мы извлекаем слова из фраз с указанием их позиции во фразе, так что, если задача решена качественно, то с высокой вероятностью фраза будет восстановлена корректно. Менее высокие результаты в сравнении с англоязычными текстами можно объяснить множеством сложностей, с которыми связаны как в целом задачи из области NLP(Natural Language Processing), так и конкретно задача извлечения ключевых слов и фраз из коротких текстов.
Одной из главных проблем является строгий порядок слов в английских предложениях, в то время как в русском языке автор имеет большую свободу в конструировании предложений. В связи с этим предложения имеют менее структурированный вид и сложнее поддаются формализации и обработке и использованием математических моделей [3].
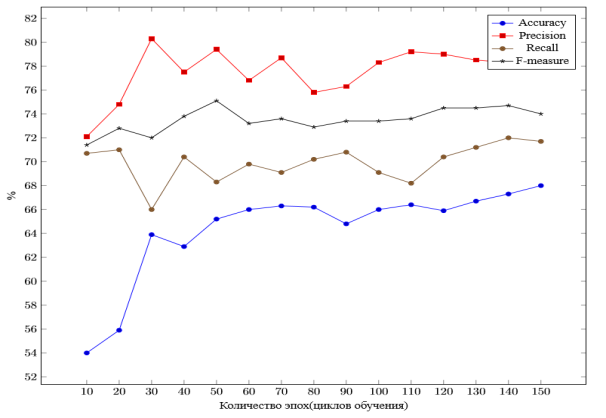
Рис. 1. Результаты обучения нейросети
Таким образом данная методика построения нейронных сетей действительно может быть успешно применена и для анализа коротких текстов в русскоязычных социальных сетях.
Литература:
- Ванюшкин А. С. Методы и алгоритмы извлечения ключевых слов / А. С. Ванюшкин, Л. А. Гращенко // Новые информационные технологии в автоматизированных системах, 2016
- Соколова. Е. В. Автоматическое извлечение ключевых слов и словосочетаний из русскоязычных текстов с помощью алгоритма KEA./ Е. В. Соколова, О. А. Митрофанова// Компьютерная лингвистика и вычислительные онтологии. Выпуск 1 (Труды XX Международной объединенной научной конференции «Интернет и современное общество», IMS-2017, Санкт-Петербург, 21–23 июня 2017 г. Сборник научных статей).
- Шереметьева, С. О. Методы и модели автоматического извлечения ключевых слов / С. О. Шереметьева, П. Г. Осминин // Вестник ЮУрГУ. Серия «Лингвистика». — 2015. — Т. 12, № 1. — С. 76–81.
- Tomas Mikolov, Distributed Representations of Words and Phrases and their Compositionality / T. Mikolov, I.Sutskever, K.Chen, G.Corrado, J.Dean // In Proceedings of NIPS.
- Qi Zhang, Keyphrase Extraction Using Deep Recurrent Neural Networks on Twitter / Qi Zhang, Yang Wang, Yeyun Gong, Xuanjing Huang // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 836–845, Austin, Texas, November 1–5, 2016.

