





В мире информационных технологий имеется существенный объем задач, каждая из которых требующая тщательного рассмотрения, чтобы подобрать правильный инструментарий для её решения. Одновременно, помимо понимания поставленной задачи, важным фактором для выбора необходимых инструментов является понимание их принципов работы и нюансов использования. Особенно понимание внутреннего устройства важно, когда стоит задача обрабатывать большое количество информации за единицу времени. Даже малейший просчет в технической реализации, с точки зрения производительности, может привести как к неудовлетворительным результатам быстродейтвия, так и к прогрессивному замедлению работы программы. При создании высоконагруженных систем, существуют общие требования к реализации:
- Система должна быть способна обрабатывать требуемые объёмы информации
- Система должна быть устойчива к ошибкам. Т. е. вне зависимости от её типа (ошибка обработки или системный сбой), изменение показателей быстродействия должны быть минимизированы
- Метрики производительности должны минимально корелироваться с объёмами информации, хранимой внутри системы.
В данной статье рассмотрены подходы серверной обработки на языке Java и хранения информации в реляционной базе данных, а также описываются существующие инструменты и их анализ, с приведением результатов измерений производительности.
Для проведения измерений производительности сервера, использовались следующие инструменты:
- Вычислительная машина, ЦПУ 4 ядра, ОЗУ 16 ГБ
- Операционная система Ubuntu 18.04
- HTTP-бенчмарк wrk (https://github.com/wg/wrk)
- Java-приложение, обрабатывающее GET-запрос с отдачей ответа в JSON-формате
Поток выполнения есть наименьшая единица обработки команд в приложении. Для обеспечения асинхронной обработки запросов на сервер существует два подхода организации потоков выполнения.
При первом подходе одному потоку ассоциируется одно открытое соединение. До тех пор, пока не произойдет отключение от сервера, поток будет прослушивать события только с определенного сокета. Существует очевидных два недостатка: во-первых, между запросами от клиента существует время простоя, когда поток выполнения не делает полезную работу. Данное время возможно было использовать на выполнение некоторой другой работы. Во-вторых, в высоконагруженной системе, данная модель определенно не выдержит нагрузок по следующим причинам:
- Учитывая, что поток ассоциируется строго с одним сокетом, имеется ограничение в количестве соединений. Например, если есть пул из двадцати потоков, это значит, что одновременно мы можем обрабатывать только двадцать соединений. Остальные входящие запросы на подключения будут отклонены
- Альтернатива в качестве увеличения пула потоков не решает проблему, по причине того, что сам поток выполнения достаточно ресурсоёмкий, а также процессорные мощности расходуются нерационально, что приводит к снижению скорости обработки одного запроса
На рисунке 1 представлены результаты измерений производительности сервера, согласно модели «один поток — одно соединение». Обратите внимание на количество ошибок сокета в течении пяти минут высокой нагрузки. 16.6 процентов всех запросов, отправленных на сервер, были не обработаны, что не удовлетворяет первому требованию к высоконагруженной системы
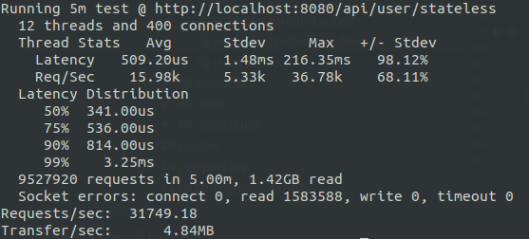
Рис. 1. Измерение производительности сервера, основанного на модели «один поток — одно соединение»
Другой подход для обработки запросов имеет структурные отличия в технической реализации. Существует две группы потоков. В первой группе достаточно иметь один поток, называемый селектором. Он оперирует такими событиями, как подключение или отключения соединения и приёма потока данных по одному из сокетов. Вторая группа может содержать несколько потоков выполнения. Она, собственно, выполняет обработку входящих пакетов, принятых первой группой. Перечислим преимущества данного подхода:
- Система может принять намного большее количество соединений. Число ограниченно только максимальным значением, определенным операционной системой.
- Селектор максимально утилизирует время, он постоянно проверяет наличие входящих событий, итерируясь по файловым дескрипторам операционной системы
- Потоки второй группы также выполняют полезную работу. По сравнению с первым подходом, когда один поток обрабатывал события только с одного сокета, здесь поток обрабатывает пакеты с нескольких. Существуют также реализации, ассоциирующие группу сокетов к одному потоку.
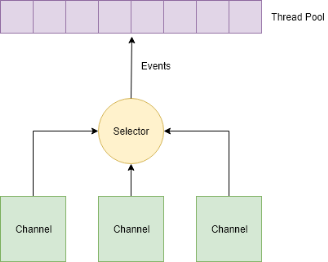
Рис. 2. Схема работы неблокирующей модели обработки данных
Данный подход называется неблокирующей моделью обработки данных. На рисунке 2 проиллюстрирован принцип работы данной модели: существует поток-селектор, обрабатывающий события, связанные с сокетами. При подключении, селектор регистрирует сокет и реагирует только на появление в нем входящих данных. Когда данные принял селектор, он делегирует обработку одному из потоков второй группы. При отключении соединения, селектор удаляет дескриптор сокета, чтобы при следующей итерации не тратить время на его проверку [1].
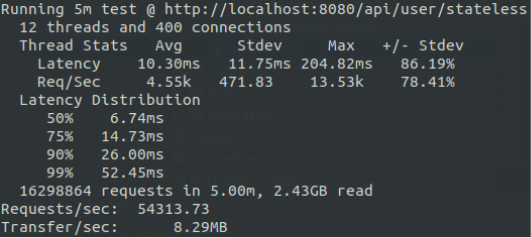
Рис. 3. Измерение производительности сервера, основанного на неблокирующей модели ввода-вывода
Что касается, показателей производительности, рисунок 3 показывает результаты теста. По сравнению с предыдущими измерениями, отсутствуют ошибки чтения и наблюдается прирост скорости обработки на 42.5 процента
Неблокирующая модель имеет несколько реализации. В операционной системе Linux есть такие методы, реализующие модель как select(), poll() и epoll() [2]. Измерения на рисунке 3 сделаны на Java-сервере, использующего по умолчанию poll() реализацию. Если воспользоваться вызовом epoll(), то результаты измерения выглядят как на рисунке 4. Однако при выборе между poll() и epoll(), необходимо учитывать, что последний доступен только на операционной системе Linux.
Таким образом, выше были представлены существующие инструменты для реализации собственного сервера обработки HTTP-запросов, а также приведены результаты нагрузочных тестов. При реализации высоконагруженного сервера, следует учитывать, что существует неблокирующая модель ввода-вывода, проявившая высокую отказоустойчивость при высоких нагрузках.
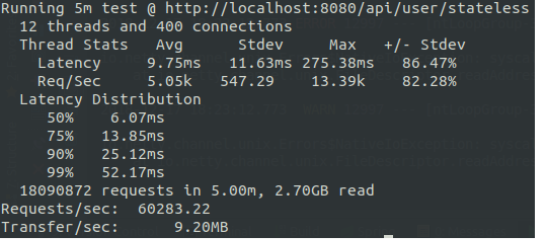
Рис. 4. Измерение производительности сервера, вызывающий метод epoll() для обработки событий
Для проведения измерений производительности базы данных, использовались следующие инструменты:
- Вычислительная машина ЦПУ 2 ядра, ОЗУ 8 ГБ
- Операционная система Windows 10 Pro
- СУБД Postgres 10.0
- Таблица с записями в размере 10000
Зачастую для обеспечения производительности поиска данных в базе, прибегают к индексированию полей. Однако быстрый доступ обеспечивается за счет большего потребления памяти. Индекс есть отдельная от таблицы структура данных, элемент которого хранит ссылку на кортеж в основной таблице и контрольное значение. Помимо того, что увеличивается объем памяти для хранения, также уменьшается производительность операций вставки, удаления и изменения кортежа, т. к. вместе с таблицей, изменяются и индексы. На рисунке 5 верхний результат был измерен на выборке из таблицы без индексирования, нижний результат, наоборот.
Однако поиск значительно улучшился, когда поиск осуществляется по индексу — 4.439 миллисекунд против 0.220. Однако на тестируемой вычислительной машине можно получить результат в размере 0.096, если учитывать, какие структуры данных может представлять индекс. Например, 0.220 миллисекунд — время поиска в индексе, хранящий данные в виде сбалансированного дерева. Как известно, алгоритмическая сложность поиска в нем логарифмическая. Что касается 0.096 миллисекунд, здесь поиск по индексу имеет константную алгоритмическую сложность, т. к. данные в индексе хранятся в хэш-таблице. Не смотря на внушительный прирост производительности поиска, использование данного индекса ограничено. При запросах на выборку, где в критериях поиска будут фигурировать такие знаки сравнения как `>, <. >=, <=` или операторы BETWEEN, LIKE, база будет осуществлять поиск по таблице, игнорируя индекс, т. к. например хэширование аргумента в операторе LIKE, вероятнее всего даст отсутствие результата.
![]()
![]()
Рис. 5. Сравнение производительности вставки в таблицу без индексов (сверху) и с индексами (снизу)
Также возможно потерять производительность при индексировании таблицы по нескольким полям. Индекс с неправильным порядком объявленных контрольных полей будет применен базой данных для поиска результата, однако результат может быть улучшен, если порядок будет соблюдён.
Например, есть таблица пользователей. Нужно улучшить производительность поиска по фамилии и возрасту. Имеем следующий запрос:
SELECT * FROM users WHERE lastname = 'Shimmans' AND age BETWEEN 4 AND 10
В составном индексе, структура элемента будет выглядеть следующим образом: контрольное значение по первому контрольному полю. Далее перечень контрольных значений по второму полю, имеющих одинаковое первое контрольное значение, упомянутое ранее и ссылки на кортежи в основной таблице.
Для начала, рассмотрим поиск по индексу с контрольными значениями в порядке age, lastname. Чтобы в индексе найти результат, нужно взять максимум шесть элементов и внутри каждого из них найти кортежи с фамилией, указанной в запросе.
Теперь наоборот, индекс имеет порядок lastname, age. В индексе достаточно найти элемент, имеющий первое контрольное значение, заданное в запросе и в нем произвести поиск кортежей, удовлетворяющий критерий по полю age. Определенно, второй индекс выполнит поиск за меньшее количество шагов. Время исполнения также доказывает это — 0.080 против 0.047 милисекунд.
Резюмируя, отметим, что поверхностный подход обеспечения производительности в базе данных может привести к неудовлетворительным показателям, где выявление ошибок проектирования может занять достаточное количество времени, при отсутствии нужных инструментов. Например, индексы можно протестировать, используя вызов EXPLAIN ANALYZE [3]. Данный вызов даёт информацию о выбранной стратегии базы данных для поиска результата, а также время разработки стратегии и время выполнения запроса. В зависимости от вендора базы данных, результаты анализа могут различаться по формату вывода, однако документация от разработчика даёт необходимые пояснения.
Литература:
- Greg Travis Getting started with new I/O (NIO) [Электронный ресурс] // URL — https://www.ibm.com/developerworks/java/tutorials/j-nio/j-nio.html
- Louay Gammo, Tim Brecht, Amol Shukla, David Pariag Comparing and Evaluating epoll, select, and poll event Mechanisms // University of Waterloo. — 2010
- Markus Winand SQL Performance Explained — Markus Winand, 2012
