





В работе рассматривается выбор оборудования, программного обеспечения, вопросы настройки и тестирования производительности вычислительного кластера на базе небольшого числа неоднородных многоядерных серверных узлов. Оценка производительности выполняется как с помощью традиционного теста Linpack, оптимизированного для конкретной конфигурации, так и с точки зрения производительности при решении прикладных задач.
Ключевые слова: вычислительный кластер, кластер рабочих станций (COW), массивно-параллельная обработка (MPP), High-perfomancecomputing (HPC), GPU, архитектура IntelManyIntegratedCore (MIC), IntelXeonPhi, IntelXeonE5, Cent’OS, MPI, Linpack, IntelMKL, SIESTA, ANSYS, FlowVision, Mathematica, FRUND, Top50.
Введение
В настоящее время потребность в высокопроизводительных вычислительных системах и высокопроизводительных вычислениях в целом (high-perfomancecomputing или HPC) по-прежнему высока, несмотря на распространенность таких систем, так как ученым и конструкторам приходится обрабатывать все большие объемы информации и применять все более точные и реалистичные методы и средства моделирования. В первом случае речь может идти об интеллектуальных методах обработки так называемых больших данных (bigdata), во втором — о повышении точности уже используемых моделей, применении принципиально новых моделей и алгоритмов их обработки, моделировании в реальном времени или одновременном междисциплинарном моделировании. Последнее десятилетие характеризуется масштабным переходом к внедрению параллелизма вычислений благодаря повсеместному распространению многопроцессорных систем, удешевлению и повышению быстродействия сетевых инфраструктур. В сущности, оба больших класса задач (обработка bigdata и высокоточное моделирование исследуемых процессов или разрабатываемых конструкций) могут с успехом эксплуатировать два вида параллелизма: параллелизм данных и параллелизм задач, предоставляемых параллельными архитектурами.
В то время как параллелизм внедряется во все современные автономные микропроцессорные системы, начиная от смартфонов и заканчивая серверными платформами, актуальность создания и эксплуатации многопроцессорных серверных комплексов не снижается. Это объясняется многим факторами, среди которых можно выделить прогресс сетевых технологий, глобальной сети Интернет, развитие технологий виртуализации, что привело к росту популярности облачной парадигмы вычислений. С другой стороны, рост мощности современных компьютеров сопровождается ростом потребности в вычислительной мощности как для задач BigData, так и для сверхсложного моделирования в традиционных и новых областях, которые формируют проблематику задач «большого вызова», требующих перехода к экзафлопсным значениям производительности. Растет и потребность в многопроцессорных системах и комплексах (кластерах) среднего класса, находящихся по производительности между передовыми супер-ЭВМ и настольным системами. Они необходимы как для ускорения сложного моделирования, для обработки средних по размеру массивов частных данных в необщедоступном облаке, так и для апробации крупномасштабных задач до их переноса на сверхбольшие облачные или иные доступные вычислительные ресурсы. Помимо предоставления мощных вычислительных ресурсов такие среднемасштабные комплексы позволяют централизовать обслуживание и специализированную инфраструктуру, предоставить в общее пользование специализированное программное обеспечение и хранилище данных и так далее.
В этой связи для такой научной и образовательной организации, как современный технический университет, наличие вычислительного кластера, хотя бы не очень крупного, является практически обязательным условием как поддержки учебного процесса для подготовки современных инженеров (не только программистов и специалистов по информационным технологиям), но и для поддержки научных исследований фундаментального и разработок прикладного характера. А рост возможностей современных вычислительных архитектур и сетевых технологий позволяет реализовать эту потребность относительно небольшими средствами.
Кластер можно определить как группу взаимосвязанных полноценных компьютеров, выполняющих совместно некоторую работу таким образом, что со стороны она воспринимается как единый вычислительный ресурс. Термин «полноценный» в данном случае означает, что такой компьютер может работать автономно, отдельно от кластера. Более узко вычислительный кластер — это относительно слабосвязанный многопроцессорный вычислительный комплекс с обменом данными между узлами (или процессами) путем передачи сообщений по каналам ввода-вывода. Относительно слабосвязанный потому, что существуют еще более слабосвязанные распределенные комплексы, которые обычно относят к классу грид-систем.
Развитие вычислительного кластера в Волгоградском государственном техническом университете
В Волгоградском государственном техническом университете (ВолгГТУ) на факультете электроники и вычислительной техники (ФЭВТ) развитие своего небольшого вычислительного кластера идет с 2007/2008 года, когда на базе первых приобретенных многоядерных серверов и рабочих станций был построен кластер рабочих станций (COW) под управлением системы Linux [1,2].
Кластер постоянно развивался, дополнялся новыми узлами и ускорителями разных архитектур (GPU, FPGA, MIC), оснащался различным системным и прикладным программным обеспечением. С 2009 года кластер ФЭВТ стал участником программы Университетский кластер [3]. С 2009 года с использованием кластера стали выполняться различные проекты и исследования, прежде всего в области моделирования физики твердого тела (ФТТ), в целом физической электроники, в области создания и использования инженерных систем нового поколения, в том числе системы ФРУНД (FRUND), разрабатываемой и развиваемой в ВолгГТУ, а также САПР T-Flex и CFD — пакета FlowVision [2,4–9].На кластере стали выполняться расчеты в прикладных пакетах Abaqus, ANSYS, ModeFrontier и других учеными университета. Кластер также широко использовался в учебном процессе направления Информатика и вычислительная техника, начиная со 2 курса бакалавриата и во многих дисциплинах магистратуры. С 2014 года кластер начал использоваться и как тестовая площадка для решения задач обработки BigData. Пиковая производительность кластера на 12 основных узлах составила около
10 TFLOPS.
Осенью 2014 года в рамках государственной программы подготовки новых инженерных кадров в ВолгГТУ было принято решение о приобретении дополнительного оборудования для создания нового вычислительного кластера класса близкого к MPP. Новое оборудование было решено соединить с новыми компонентами имеющегося кластера, приобретенными в 2013–2014 годах по программе стратегического развития университета, для создания нового относительного мощного, хотя и небольшого вычислительного кластера.
Выбор оборудования, как и последующий монтаж, настройка, конфигурирование, установка системного и прикладного программного обеспечения кластера выполнялись силами сотрудников и студентов факультета ЭВТ.
Выбор аппаратного и системного программного обеспечения кластера
При рассмотрении вариантов создания кластера, приобретения нового и использования уже имеющегося на тот момент оборудования учитывались такие аспекты, как: имеющийся бюджет (достаточно скромный), предполагаемое к приобретению и уже установленное программное обеспечение (системное, прикладное, средства разработки), назначение кластера (поддержка ведущихся и планируемых научных и прикладных разработок, возможности оказания услуг на хоздоговорной основе, учебный процесс), энергопотребление, возможности охлаждения, возможность обслуживания, возможность использования кластера как единого вычислительного ресурса, актуальность приобретаемого оборудования в ближайшие несколько лет, опыт эксплуатации различного оборудования, достижение максимальной производительности минимальными средствами и некоторые другие аспекты. После анализа перечисленных факторов было решено остановиться на платформе IntelXeonE5 v3 как совместимой с имеющимися двумя узлами на базе IntelXeonE5, задействовать ранее приобретенное оборудование для интерконнекта на базе стандарта InfinibandFDR 56 Гбит/с, оснастить серверные платформы ускорителями IntelXeonPhi архитектуры MIC, а также — несколькими GPU ускорителямиNVidia на базе архитектуры NvidiaKEPLER.
В дальнейшем при выборе набора ускорителей на первый план вышли два аспекта: сильно возросшая стоимость ускорителей NVidia (по соотношению пиковой производительности к стоимости они уступают и MIC ускорителям, и GPU компании AMD) и значительное усложнение использования узлов с разными ускорителями (даже на единой серверной платформе) как единого ресурса. В связи с этим, а также в связи с тем, что уже имеющиеся узлы на базе XeonE5 уже были оснащены XeonPhi, для тестовых расчетов уже имелись ускорители NVidia, а предполагаемое к установке прикладное программное обеспечение в основном имело заявленную поддержку архитектуры MIC по крайней мере через библиотеку IntelMKL, было принято решение остановиться на приобретении ускорителей XeonPhi. Это также позволило увеличить количество приобретенных узлов. При этом, конечно, нужно понимать, что это решение не является топовым и уступает GPUNVidia по ряду параметров.
Характеристики аппаратного и системного программного обеспечения кластера
Кластер, собранный на базе приобретенного и имевшегося оборудования состоит из 13 вычислительных узлов, аппаратные характеристики которых приведены в таблице 1.
Таблица 1
Аппаратные характеристики вычислительных узлов
|
№ |
Наименование |
11 узлов |
2 узла |
|
1 |
Процессор |
Intel Xeon Processor E5–2650v3 (2,3 GHz, 10 ядер) x2 |
Intel Xeon Processor E5–2660 (2,2 GHz, 8 ядер) x2 |
|
2 |
Память |
64GbDDR4 |
128GbDDR3 |
|
3 |
Жесткий диск |
SSDIntel 240Gb |
SATA 2 Tb |
|
4 |
Сопроцессор |
IntelXeonPhiCoprocessor 31s1px2 (в одном из 11 узлов — x6) |
IntelXeonPhiCoprocessor 31s1px2 / 5110p |
Для объединения вычислительных узлов в сеть используется 36-портовый коммутатор стандарта InfiniBandFDR (56 Гбит/с) компании Mellanox. При использовании данного интерконнекта достигаются следующие преимущества (по сравнению со стандартными архитектурами ввода-вывода):
- cовместно используемая система ввода-вывода создает общую точку соединения, уменьшая число прямых соединений (кабелей), что уменьшает требуемое число адаптеров и снижает общие издержки
- пропускная способность шин PCI, равная 500 Мбайт/с, разделяется между всеми устройствами, а для InfiniBand каждый канал имеет минимальную скорость соединения 500 Мбайт/с, увеличиваемую до 6 Гбайт/с; cерверInfiniBand может иметь несколько высокоскоростных каналов ввода-вывода для использования с системами хранения или в коммуникациях — это устраняет узкие места;
- гибкость в размещении серверов и контроллеров ввода-вывода в пределах центра данных и способность добавлять вычислительные мощности отдельно от расширения системы хранения;
- cетевой протокол InfiniBand позволяет реализовать возможности глобальной маршрутизации в пределах пакетов данных, поддерживая различные местоположения систем хранения WAN;
- производительность сервера возрастает, поскольку задачи ввода-вывода переносятся в структуру InfiniBand [10].
В качестве операционной системы на управляющем и вычислительных узлах используется CentOS — дистрибутив Linux, основанный на коммерческом дистрибутиве RedHatEnterpriseLinux компании RedHat и совместимый с ним. Для распределения обработки данных между узлами используется технология MPI. На кластере используется следующее специализированное ПО:
- для централизованного управления кластером используется XCAT, инструмент, спроектированный для управления большими кластерами с открытым исходным кодом.
- в качестве менеджера распределенных ресурсов используется TORQUE, обладающий большим количеством расширений от ведущих лабораторий в сфере HPC.
- для математических вычислений используется библиотека IntelMKL, в которую входят оптимизированные алгоритмы для решения задач линейной алгебры, векторной математики, статистики и так далее.
Настройкасистемного программного обеспечения кластера
Для запуска параллельных вычислений был установлен пакет для создания параллельных приложенийIntelParallelStudioXE 2015 ClusterEdition. Ниже приведены переменные окружения, используемые для вызова команд компилятора:
export ICCROOT=/usr/local/intel/composerxe
export MPIROOT=/usr/local/intel/impi/5.0.3.048/impi/5.0.3.048
source $ICCROOT/bin/compilervars.sh intel64
source $MPIROOT/intel64/bin/mpivars.sh
Для осуществления высокоскоростного обмена данными между узлами при выполнении параллельных вычислений, использовалась сеть InfiniBand поколения FDR с пропускной способностью до 54 Гбит/с.Для соединения узлов была выбрана группа протоколовIPoIB, описывающая передачу IP-пакетов поверх InfiniBand. На всех узлах, имеющих InfiniBand платы был установлен драйвер OFED-3.12–1 с поддержкой IntelXeonPhi.
Пример настройки сетевого интерфейса InfiniBand приведен ниже:
DEVICE=ib0
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.10.10
NETMASK=255.255.255.0
TYPE=Infiniband
С целью получения максимальной пропускной способности были настроены следующие параметры BIOS:
Intel® Hyper-Threading Tech — OFF
CPU Power and Perfomance — Perfomance
CPU C-State — Disabled
Socket PCIe — Gen3
Так же для большей производительности для сетевых плат InfiniBand стоит использовать слоты PCIex16.
В протоколе InfiniBand реализовано аппаратное решение для обеспечения прямого доступа к оперативной памяти другого компьютера — RDMA. Для того, чтобы включить поддержку RDMA в ОС необходимо добавить переменные окружения I_MPI_DEVICE=RDMA, I_MPI_FABRICS=DAPLи снять ограничения пользователя командой ulimit –l unlimited.
Чтобы протестировать пропускную способность соединения между двумя узлами использовалась утилита ib_read_bw, поставляемая вместе с драйвером OFED.
Результат теста пропускной способности выглядит следующим образом:
---------------------------------------------------------------------------------------
RDMA_Read BW Test
Dual-port : OFF Device : mlx4_0
Number of qps : 1 Transport type : IB
Connection type : RC Using SRQ : OFF
TX depth : 128
CQ Moderation : 100
Mtu : 2048[B]
Link type : IB
Outstand reads : 16
rdma_cm QPs : OFF
Data ex. Method : Ethernet
---------------------------------------------------------------------------------------
local address: LID 0x04 QPN 0x004f PSN 0x220402 OUT 0x10 RKey 0x20010b00 VAddr 0x007f83e001d000
remote address: LID 0x01 QPN 0x004f PSN 0xbfe5ae OUT 0x10 RKey 0x20011000 VAddr 0x007fc19b92e000
---------------------------------------------------------------------------------------
#bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps]
65536 5000 6190.71 6097.43 0.086327
---------------------------------------------------------------------------------------
Тестирование производительности вычислительного кластера
Инструментом тестирования производительности кластера был выбран IntelMPOptimizedLinpackBenchmark. Данный тест является модифицированным и дополненным тестом HPL 2.1. Алгоритм теста заключается в решении плотной СЛАУ методом LU-декомпозиции исходной матрицы и работает следующим образом.При параллельном процессе на вычислительном кластере исходная матрица разделяется на логические блоки размерностью NBxNB (обычно NBxNBпри расчетах лежит в интервале 32–256, а для систем с сопроцессорами в интервале 960–1280). Эти блоки в свою очередь разбиваются сеткой PxQна более мелкие. Каждый из таких блоков отправляется отдельному процессору системы. Коэффициенты P и Q берутся в зависимости от структуры кластера, а их произведение не может быть больше имеющегося количества узлов. Конкретные значения P и Q следует выбирать в зависимости от коммуникационной среды.
За одну итерацию главного цикла факторизации подвергаются NB столбцов с последующим обновлением оставшейся части матрицы. Результаты разложения пересылаются всем узлам одним из шести алгоритмов распространения.
После разложения последовательно решается две системы уравнений:
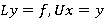 .
.
Тест считается выполненным, если:
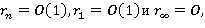 где (1)
где (1)
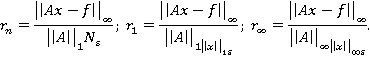
Эти условия означают, что задача решена верно,ε — точность представления чисел с плавающей точкой.
IntelMPOptimizedLinpack предлагает несколько вариантов тестов для оценки производительности систем с сопроцессорами. Нами был выбран тест xhpl_offload64, т. к. он позволяет распределять количество запускаемых MPI процессов на хосте и сопроцессорах.
Для тестирования производительности нами был проведен ряд тестов на разном количестве узлов (10+2, 11+1, 10+0) и с разным количеством запускаемых MPI процессов (1, 2, 4).
Согласно рекомендациям Intel, при использовании сопроцессоров в тесте Linpack, следует использовать значения параметра Nb: 960 для системы с 1 XeonPhi, 1024 для системы с 2 XeonPhi и 1280 для системы с 3 XeonPhi.
Для расчета параметра NIntel рекомендует пользоваться следующей формулой:
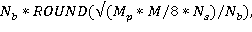
где 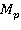 — процент использования памяти,
— процент использования памяти, 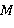 — объем памяти,
— объем памяти, 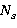 — количество вычислительных узлов
— количество вычислительных узлов
Параметры настройки Linpack и полученные результаты тестирования приведены в таблице 2. Стоит отметить, что чем больше разница между P и Q, тем меньше максимальное число N и тем ниже оцениваемая производительность узлов. Таким образом, при разбиении узлов на произведение P и Q, необходимо выбирать примерно одинаковыеP и Q.
Таблица 2
Производительность кластера при изменениинастроекLinpack
|
№ |
N |
Nb |
P |
Q |
Производительность, TFLOPS |
|
1 |
82944 |
1024 |
1 |
1 |
2.13 |
|
2 |
227328 |
1024 |
2 |
5 |
17,4 |
|
3 |
230400 |
1024 |
2 |
5 |
17,5 |
|
4 |
230400 |
1024 |
2 |
6 |
17,7 |
|
5 |
283584 |
1280 |
3 |
4 |
19,4 |
|
6 |
289280 |
1280 |
4 |
6 |
23.21 |
Проведенные тесты позволяют сделать вывод, что рост производительности при росте числа узлов не является пропорциональным, что подтверждается законом Амдала–Уэра, из которого следует, что последовательные участки параллельной программы ограничивают рост скорости их выполнения с ростом количества вычислителей [11].
Полученные показатели производительности позволили кластеру, состоящему всего из 13 узлов (а фактически в тесте использовались как вычислительные только 12 из них) занять 49 место в 22 редакции рейтингаTop50 СНГ [12]. Необходимо отметить, что выбранный вариант конфигурации показал при этом неплохое соотношение реальной и пиковой производительности (65,7 % для кластера в целом, до 74 % для 12 узлов) и высокую производительность на один узел (до 2 ТФлопс).Многие соседние по рейтингу системы показывают близкую производительность, имея в десятки раз больше узлов, из-за отсутствия ускорителей.
Настройка прикладного программного обеспечения
Для работы студентов и сотрудников ВолгГТУ на кластере установлено следующее программное обеспечение:
- IntelParallelStudio — параллельный пакет разработки программного обеспечения Intel, сочетающий в себе ведущие в индустрии C/C++ компилятор и Fortran компилятор, различные библиотеки, инструменты профилирования и многое другое [13];
- WolframMathematica — система компьютерной алгебры, используемая во многих научных, инженерных, математических и компьютерных областях;
- ANSYS — универсальная программная система конечно-элементного (МКЭ) анализа [14];
- FlowVision — комплексное многоцелевое решение для моделирования трехмерных течений жидкостей и газа;
- NX Nastran–инструмент для проведения компьютерного инженерного анализа (САЕ) проектируемых изделий методом конечных элементов (МКЭ) [15];
- SIESTA — компьютерная программа для эффективных расчётов электронной структуры и Abinitio методов в симуляции молекулярной динамики молекул и твердых тел.
Для распределения вычислительных ресурсов используется набор очередей TORQUE, разделяющих существующие ресурсы по совокупности вычислительных узлов. Доступ к очередям ограничен конкретными пользователями. Так, на базе кластера ВолгГТУ организованы следующие очереди:
- Packages — набор узлов, на которых установлены пакеты FlowVision, NX Nastran, ANSYS;
- Mathematica — набор узлов, на которых установленаWolframMathematica;
- Student — набор узлов, используемых для проведения лабораторных работ со студентами;
- All — очередь, содержащая все узлы для отдельных задач, для выполнения которых требуются все ресурсы.
Приведенные выше в таблице 2 значения производительности на тесте Linpackхарактеризуют производительность на известном и достаточно однобоком тесте, под который давно оптимизируют свои платформы всепроизводители и который давно подвергается жесткой критике как недостаточно объективный. Интересно оценить производительность кластера на тех задачах, для которых предполагается его использование, сравнив его условно с предыдущим кластером. Это было частично выполнено после основного конфигурирования кластера весной 2015 года на нескольких отдельных примерах. Результаты оценки приведены в таблице 3.
Таблица 3
Оценки роста производительности для ряда задач на одном узле кластера за счет применения новой серверной платформы и ускорителей
|
Задача / пакет |
Оценка роста производительности, раз |
|
Моделирование на SIESTA (MKL, MIC) |
2.5 |
|
Сравнение текста со списком текстов (MIC) |
2–12 |
|
Новый решатель для CFDFlowVision (CPU, AVX2) |
2 |
|
Новый решатель для пакета FRUND (CPU) |
4 |
|
Моделирование на ANSYS (MKL) |
2 |
|
Средняя OpenMP / MPI программа (AVX2) |
2.5 |
|
Пакет молекулярной динамки CP2K |
1,7–3 |
|
Программа моделирования методом Монте-Карло с использованием CPU / MIC |
5–8 |
Часть результатов получена опытным путем, часть — по доступным материалам [7–10, 13, 14]. В скобках приведена архитектура, используемая для ускорения в конкретном примере.
Заключение
В ходе работы был собран, настроен и протестирован обновленный вычислительный кластер ВолгГТУ. По результатам тестирования можно сделать вывод, что полученная система способна выполнять широкий круг вычислительных задач, связанных с инженерными расчетами, имитационным моделированием, а также с учебной деятельностью. Производительность на тесте Linpackсоставила 23,13 TFLOPS, что составляет более 65 % от пиковой, производительность одного узла в среднем — около 2 ТFLOPS, пиковая производительность обновленного кластера в 3,5 раза выше, чем у его предшественника, оценка производительности на прикладных пакетах и программах моделирования для одного узла в среднем также дает ускорение вычислений в 3,6 раза, при этом в отличие от предыдущего существенно неоднородного кластера, обновленный кластер легче использовать как единый вычислительный ресурс.
Используемые архитектура и настройки для данного кластера допускают как одновременную работу множества пользователей (при решении небольших задач на специализированном ПО), так и решение крупных задач, которым необходимы все вычислительные ресурсы системы.
1. Построение высокопроизводительной вычислительной кластерной системы на базе имеющегося парка компьютерной техники под управлением операционной системы GNU/Linux / Андреев А. Е., Попов Д. С., Жариков Д. Н., Сергеев Е. С. // Изв. ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в техн. системах». Вып. 6: межвуз. сб. науч. ст. / ВолгГТУ. — Волгоград, 2009. — № 6. — C. 48–51.
2. Обучение программированию многоядерных процессоров и многопроцессорных ЭВМ / Андреев А. Е., Жариков Д. Н., Сергеев Е. С. // Известия Волгоградского государственного технического университета. 2008. Т. 5. № 5 (43). С. 110–112.
3. Андреев, А. Е. Факультетский кластер ФЭВТ ВолгГТУ и участие ВолгГТУ в программе «Университетский кластер» [Электронный ресурс] / Андреев А. Е., Жариков Д. Н., Шаповалов О. В. // Облачные вычисления. Образование. Исследования. Разработки: тез.докл. конф. (Москва, 15–16 апр. 2010 г.): в рамках программы «Университетский кластер» / Ин-т системного программирования РАН. — [М.], 2010. — C. 60.- http://www.ispras.ru/ru/unicluster/.
4. Применение файловых операций в MPI программах для распараллеливания вычислительных задач, зависимых по данным / Андреев А. Е., Гетманский В. В., Жариков Д. Н., Сергеев Е. С. // Изв. ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в техн. системах». Вып. 6: межвуз. сб. науч. ст. / ВолгГТУ. — Волгоград, 2009. — № 6. — C. 45–47.
5. Решение систем дифференциально-алгебраических уравнений последовательным исключением множителей Лагранжа / Шаповалов О. В., Гетманский В. В., Андреев А. Е., Горобцов А. С. // Изв. ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в технических системах». Вып. 10:межвуз. сб. науч. ст. / ВолгГТУ. — Волгоград, 2011.- № 3. — C 31–33.
6. Система для расчёта тепловых технологических процессов машиностроения / Андреев А. Е., Громов Е. Г., Резников М. В., Шаповалов О. В. // Известия ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в технических системах». Вып. 7:межвуз. сб. науч. ст. / ВолгГТУ. — Волгоград, 2009. — № 12. — C. 124–126.
7. Применение векторных инструкций в алгоритмах блочных операций линейной алгебры / Андреев А. Е., Егунов В. А., Насонов А. А., Новокщенов А. А. // Известия ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в технических системах». Вып. 21:межвуз. сб. науч. ст. / ВолгГТУ. — Волгоград, 2014. — № 12 (139). — C. 5–11.
8. Андреев, А. Е. Реализация динамической балансировки нагрузки между ЦПУ и сопроцессорами архитектуры Intel MIC в пакете молекулярного моделирования CP2K / Андреев А. Е., Куц Д. В., Насонов А. А. // Известия ВолгГТУ. Серия «Актуальные проблемы управления, вычислительной техники и информатики в технических системах». Вып. 21:межвуз. сб. науч. ст. / ВолгГТУ. — Волгоград, 2014. — № 12 (139). — C. 11–16.
9. Шаповалов, О. В. Применение библиотеки параллельных шаблонов в разработке геометрического ядра / Шаповалов О. В., Андреев А. Е., Фоменков С. А. // Вестник компьютерных и информационных технологий. — 2014. — № 11. — C. 8–12.
10. Свободная интернет-энциклопедия Wikipedia [Электронный ресурс]. — Режим доступа: https://ru.wikipedia.org/wiki/InfiniBand, свободный (дата обращения: 06.06.2015).
11. Свободная интернет-энциклопедия Wikipedia [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/wiki/Закон_Амдала, свободный (дата обращения: 06.06.2015).
12. ТОП 50. Суперкомпьютеры. Текущий рейтинг. 22-ая редакция от 31.03.2015. [Электронный ресурс]. — Режим доступа: http://top50.supercomputers.ru/?page=rating, свободный (дата обращения 06.06.2015).
13. Свободная интернет-энциклопедия Wikipedia [Электронный ресурс]. — Режим доступа: https://ru.wikipedia.org/wiki/Intel_Parallel_Studio, свободный (дата обращения: 06.06.2015).
14. Свободная интернет-энциклопедия Wikipedia [Электронный ресурс]. — Режим доступа: https://ru.wikipedia.org/wiki/Mathematica, свободный (дата обращения: 06.06.2015).
15. SystemPLMSoftware [Электронный ресурс]. –Режим доступа: http://www.plm.automation.siemens.com/ru_ru/products/nx/for-simulation/, свободный (дата обращения: 08.06.2015).
