Работа посвящена разработке искусственного интеллекта для агентов, моделирующих поведение животных в компьютерных играх. Для достижения цели использовался метод разработки искусственного интеллекта Utility-based.
Ключевые слова: искусственный интеллект, utility-based метод, онлайн игры.
Поиск пути — одна из самых основных задач в разработке игрового искусственного интеллекта. Путь состоит из набора точек (узлов), которые необходимо последовательно посетить, чтобы добраться до конечной цели. При передвижении из начальной точки в конечную будет использовать следующий алгоритм:
- поиск следующего узла;
- передвижение к следующему узлу;
- когда агент дошёл до узла, происходит остановка;
- если конечный узел не достигнут, то перейти к пункту 1.
Анимации движения и ожидания агента переключаются на каждом узле. Такие переключения происходят доли секунды. В случае, если агент не имеет конечной цели и перемещается по миру строго от одного узла до другого до тех пор, пока не появится цель, то такой момент можно обыграть любой дополнительной анимацией, например, животное будет осматривать окружающую среду некоторое время, а далее продолжит своё движение.
Чтобы полностью избежать этого, нужно ориентироваться на «живой» мир — в природе каждое движение имеет тенденцию подчиняться принципу наименьших усилий. Например, если человек идёт по коридору, а дальше поворот, то он будет ходить близко к стенам, чтобы сократить расстояние. Такое поведение воссоздается при помощи добавления радиуса к каждому узлу (рисунок 1). Если расстояние между агентом и узлом меньше, чем радиус, то узел считается достигнутым [2].
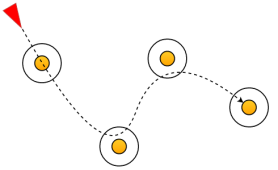
Рис. 1. Траектория движения через узлы, имеющие радиус
Логично предположить, что если агент преследует игрока, то конечной точкой в пути является сам игрок, а узлами — следы, оставленные игроком на местности при перемещении. Агент, наступая на такой след, знает порядковый номер следа, и какой игрок его оставил. Исходя из этих данных можно вычислить местоположение следующего следа. Также каждый след имеет собственный таймер, по истечению которого след удаляется, чтобы агент не смог найти игрока по следу, который он оставил в самом начале игры.
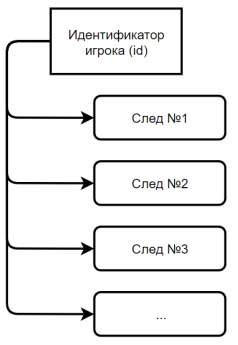
Рис. 2. Система хранения следов, оставленных игроком
Далее рассмотрим алгоритм атаки агрессивных агентов. У агрессивных агентов существует 4 области реакции:
- серая область — случайное передвижение агента. Если игрок находится в этой области, то агенты на него никак не реагируют;
- зеленая область — медленное преследование (шаг) игрока. Когда агент увидел игрока, он начинает к нему медленно приближаться;
- желтая область — быстрое преследование (бег) игрока. В этой области агент уже точно знает, что он будет атаковать игрока, и быстро сокращает расстояние до своей цели;
- красная область — нанесение урона игроку. Область атаки, в которой происходит сражение между агентом и игроком.
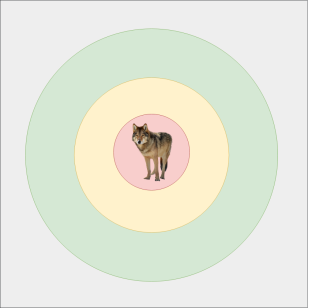
Рис. 3. Зоны агрессии
Рассмотрим метод табличной логики «стимул-реакция» [1]. Этот метод использует таблицы, содержащие несколько параметров (стимулов), которые в сумме дают значение вероятности реакции. Но использование только стимулов в конечном итоге дает неочевидные результаты. Например, если количество очков здоровья и значение усталости близки к нулю, а значения остальных стимулов близки к их соответствующему максимальному значению, то вероятность реакции в большинстве случаев будет близка к 1. Чтобы избежать этого вводятся коэффициенты влияния. Например, можно сделать первого агента, который очень агрессивен, у него отсутствует страх и чувство осторожности, и второго, для которого одновременно количество очков здоровья, страх и осторожность будут «на первом месте», следовательно, за всё время игровой сессии вряд ли нападет на игрока, независимо от чувства голода.
Примеры табличной логики изображены на 4, 5.
Чтобы каждый агент был более реалистичным у него должен быть свой «характер» с самого «рождения», поэтому коэффициенты значимости фиксируются после инициализации агента.
Но даже при таких условиях вероятность инициализации похожих по характеру агентов хоть и не велика, но значима (например, если коэффициенты значимости у двух агентов будут зеркально отражены). Чтобы сделать каждого агента уникальным, присвоим каждому стимулу следующие функции:
-
Очки здоровья:
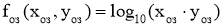
-
Голод:
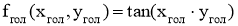
-
Усталость:
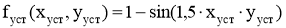
-
Страх:
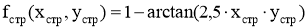
-
Агрессия:
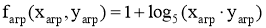
-
Осторожность:
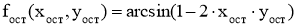
Вероятность реакции (в этом примере — атаки) будет вычисляться по следующей формуле:
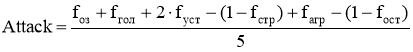 (1)
(1)
Таким образом, был реализован алгоритм перемещения агентов, который основывается на явлениях в игровом мире, а также алгоритм моделирования поведения животных, основанный на множестве стимулов.
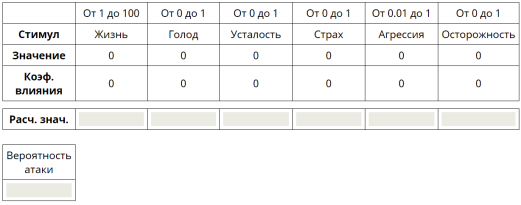
Рис. 4. Исходное состояние табличной логики
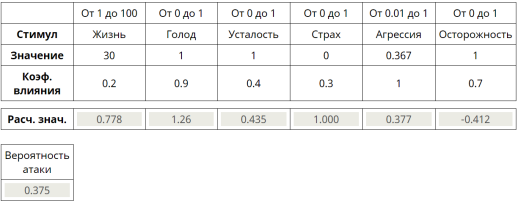
Рис. 5. Одно из состояний табличной логики
Литература:
- David Graham, GameAIPro — An Introduction to Utility Theory [Электронный ресурс] — URL: http://www.gameaipro.com/GameAIPro/GameAIPro_Chapter09
- _An_Introduction_to_Utility_Theory.pdf (Дата обращения: 18.07.2018)
- Understanding steering behaviors path fallowing [Электронный ресурс] — URL: https://gamedevelopment.tutsplus.com/tutorials/understanding-steering-behaviors-path-following--gamedev-8769 (Дата обращения: 19.07.2018)

