В статье автор исследует возможности применения искусственных нейронных сетей в решении некоторых задач информационной безопасности. В статье рассматривается модель ИНС для обнаружения вредоносного ПО на Android и потенциал методов машинного обучения в эффективном предотвращении киберугроз.
Ключевые слова: искусственные нейронные сети, информационная безопасность, разработка программного обеспечения, предварительная обработка данных, машинное обучение.
Информационная безопасность является важнейшим аспектом современного общества, поскольку зависимость от цифровых систем и Интернета продолжает расти. Утечки данных, несанкционированный доступ к конфиденциальной информации и кибератаки могут привести к серьезным последствиям для отдельных лиц и организаций. Быстро меняющийся ландшафт киберугроз и растущая изощренность злоумышленников сделали задачу защиты информации и систем еще более сложной. Следовательно, растет спрос на инновационные и адаптивные решения для задач информационной безопасности.
Традиционные меры безопасности, такие как брандмауэры, системы обнаружения вторжений (IDS) и шифрование, доказали свою эффективность в борьбе с различными киберугрозами. Однако эти методы имеют свои ограничения. Они часто полагаются на предопределенные правила или сигнатуры, которых может быть недостаточно для обнаружения новых или неизвестных атак. Кроме того, традиционные методы могут страдать от высокого уровня ложных срабатываний и могут быть неспособны адаптироваться к меняющемуся ландшафту угроз. Это побудило исследователей и практиков изучить альтернативные подходы, такие как машинное обучение и искусственный интеллект (ИИ), для повышения эффективности и адаптивности систем информационной безопасности.
Принимая во внимание рост потребности в адаптивных и эффективных решениях по информационной безопасности, успешное внедрение ИНС в системах информационной безопасности может дать несколько преимуществ по сравнению с традиционными методами. Во-первых, способность ИНС учиться на данных позволяет им обнаруживать и адаптироваться к новым и ранее неизвестным угрозам. Эта адаптивность особенно важна в контексте кибератак, поскольку злоумышленники постоянно разрабатывают новые стратегии обхода мер безопасности. Во-вторых, ИНС могут быстро и эффективно обрабатывать большие объемы данных, что делает их подходящими для обнаружения и устранения угроз в режиме реального времени. Эта возможность может помочь организациям и отдельным лицам более эффективно реагировать на киберугрозы, потенциально снижая воздействие атак.
Более того, ИНС можно использовать для улучшения существующих мер безопасности, предоставляя дополнительные решения, устраняющие ограничения традиционных методов. Например, ИНС можно интегрировать с системами обнаружения вторжений, чтобы повысить их точность и уменьшить количество ложных срабатываний. Их также можно использовать в области криптографии для разработки более безопасных алгоритмов шифрования или при анализе журналов безопасности для выявления закономерностей вредоносной деятельности, которые в противном случае могли бы остаться незамеченными.
В этом исследовании были тщательно проанализированы различные основополагающие и недавние работы, относящиеся к области машинного обучения, применяемого для обнаружения вредоносного ПО и обеспечения информационной безопасности, что заложило прочную основу для теоретических и эмпирических компонентов исследования.
Омер и др. [1], Матур [2] и Серадж с соавторами [3] углубляются в область обнаружения вредоносных программ в системе Android, подчеркивая широту применения машинного обучения в информационной безопасности.
Некоторые работы, такие как Gadde и др. [4] и Navaney и др. [5], объединяют обнаружение спама по электронной почте и SMS, в то время как другие, такие как GuangJun и др. [6], исследуют обнаружение спама в мобильных сообщениях. Лай [7] проводит эмпирическое исследование трех методов машинного обучения для фильтрации спама, предоставляя сравнительную информацию об эффективности этих методов.
Наконец, исследование выиграло от работы Амера и Эль-Саппага [8] над моделью раннего прогнозирования тревог с глубоким обучением для вредоносных программ Android, усиливающей ценность упреждающих подходов к обнаружению вредоносных программ.
Этот богатый объем литературы сыграл важную роль в формировании направления исследования и аналитической основы, предоставляя как теоретические, так и эмпирические перспективы, которые являются неотъемлемой частью научной строгости исследования и актуальности для текущего дискурса в этой области.
Эффективность моделей ИНС при решении проблем информационной безопасности оценивается с использованием различных оценочных показателей, каждый из которых дает разные точки зрения на эффективность моделей. Выбор метрик оценки определяется конкретной предметной областью и желаемыми свойствами решения на основе ИНС. Следующие метрики оценки обычно используются в контексте информационной безопасности и используются в этом исследовании:
Точность: эта метрика представляет собой долю правильно классифицированных экземпляров (истинно положительных и истинно отрицательных) от общего числа экземпляров в наборе данных.
Положительное прогностическое значение: измеряет долю истинно положительных результатов от общего числа предсказанных положительных результатов.
Отзыв: Отзыв, также известный как чувствительность или процент истинных положительных результатов, измеряет долю истинных положительных результатов от общего числа фактических положительных результатов.
Оценка F1: Оценка F1 представляет собой гармоническое среднее значение точности и полноты, обеспечивая единую метрику, которая уравновешивает компромисс между этими двумя показателями.
В следующей части статьи описана модель машинного обучения для обнаружения вредоносных программ для Android с использованием набора данных NATICUSdroid. Модель построена с использованием библиотеки TensorFlow и предназначена для классификации Android-приложений как безопасных или вредоносных в зависимости от запрошенных ими разрешений.
Набор данных NATICUSdroid. Содержит разрешения, полученные из более чем 29000 безопасных и вредоносных приложений для Android, выпущенных в период с 2010 по 2019 год. Это было сделано для создания системы обнаружения вредоносных программ для Android с использованием последних приложений. Автор набора данных — Акшай Матур
Набор данных представлен CSV таблицей, содержащей атрибуты — запрашиваемые приложением для Android разрешения и двоичные метки указывающие, является ли приложение безопасным или вредоносным. Метки атрибутов разрешений записаны в двоичном формате — 0 и 1, где 0 — не запрашивает разрешение, 1 — запрашивает разрешение.
Ниже представлено описание слоев модели. Определение соответствующих слоев и функции активации в зависимости от проблемы.
Входной слой: Плотный слой со 128 нейронами и функцией активации Rectified Linear Unit (ReLU). Входная форма этого слоя соответствует количеству объектов в нашем предварительно обработанном наборе данных (т. е. количеству уникальных разрешений).
Слой отсева: чтобы уменьшить переоснащение, мы применяем коэффициент отсева 0,5 после первого плотного слоя, что означает, что 50 % нейронов в этом слое выпадают во время обучения.
Второй плотный слой: еще один плотный слой с 64 нейронами и функцией активации ReLU. Этот слой помогает модели изучить более сложные представления входных данных.
Второй слой отсева: чтобы еще больше уменьшить переоснащение, мы применяем еще один слой отсева со скоростью 0,5 после второго слоя Dense.
Выходной слой: Плотный слой с 2 нейронами и функцией активации softmax. Этот слой выводит вероятности для каждого класса (доброкачественные или вредоносные). Функция активации softmax гарантирует, что сумма вероятностей для обоих классов равна 1.
Мы компилируем нашу модель, указав следующее:
Оптимизатор: мы используем оптимизатор Адама, который представляет собой адаптивный алгоритм оптимизации скорости обучения. Оптимизатор Adam регулирует скорость обучения во время обучения на основе первого и второго моментов градиента, что помогает добиться более быстрой сходимости.
Функция потерь: мы используем категориальную кроссэнтропию в качестве нашей функции потерь, которая подходит для задач классификации нескольких классов. Эта функция потерь вычисляет разницу между предсказанными вероятностями и истинными метками класса и минимизирует ее во время обучения.
Показатели: мы используем точность(accuracy) в качестве основного показателя для отслеживания во время обучения. Точность рассчитывается как отношение количества правильных прогнозов к общему количеству прогнозов.
Далее следует процесс обучения модели. Можно заметить, что в каждом поколении (Epoch), точность (accuracy) модели увеличивается, значение потерь (loss) уменьшается. Представленная модель прошла 50 поколений обучения, размером в 514 объектов. Мы можем точно настроить количество эпох и размер партии во время обучения, чтобы оптимизировать производительность модели.
После обучения мы оцениваем модель на тестовом наборе, используя точность и другие соответствующие показатели, чтобы оценить ее способность обнаруживать вредоносные программы для Android.
На рисунке 1 представлен график точности модели при обучении и тестировании.
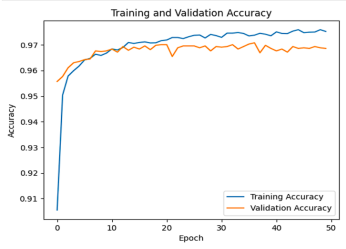
Рис. 1. Кривая точности при обучении и тестировании
На рисунке 2 представлена кривая потерь модели при обучении и проверке.
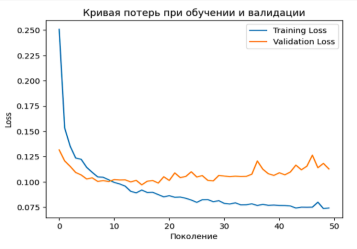
Рис. 2. Кривая потерь при обучении и проверке
На рисунке 3 представлено табличное представление значений оценки модели по метрикам, с четкой разбивкой по классам.
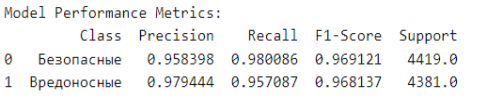
Рис. 3. Оценка модели по метрикам и классу
Основываясь на результатах этапа тестирования, модель глубокого обучения для обнаружения вредоносных программ для Android достигла точности примерно 96,86 % на тестовом наборе. Это указывает на то, что модель правильно классифицировала большинство приложений Android в тестовом наборе как безопасные или вредоносные.
В дальнейших исследованиях важно убедиться, что модель может хорошо обобщаться на новые, невиданные данные. Один из способов добиться этого — использовать такие методы, как перекрестная проверка, для проверки производительности модели на разных подмножествах набора данных.
Наша модель демонстрирует потенциал методов глубокого обучения в области информационной безопасности и обнаружения вредоносных программ для Android. Будущая работа может включать изучение различных архитектур нейронных сетей, использование дополнительных функций помимо разрешений или включение трансферного обучения для дальнейшего повышения производительности модели.
Литература:
- Omer M. A. et al. Efficiency of malware detection in android system: A survey //Asian Journal of Research in Computer Science. — 2021. — Т. 7. — №. 4. — С. 59–69.
- Mathur A. Building Android Malware Detection Architectures using Machine Learning: дис. — University of Toledo, 2022.
- Seraj S. et al. HamDroid: permission-based harmful android anti-malware detection using neural networks //Neural Computing and Applications. — 2022. — Т. 34. — №. 18. — С. 15165–15174.
- Gadde S., Lakshmanarao A., Satyanarayana S. SMS spam detection using machine learning and deep learning techniques //2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS). — IEEE, 2021. — Т. 1. — С. 358–362.
- Navaney P., Dubey G., Rana A. SMS spam filtering using supervised machine learning algorithms //2018 8th international conference on cloud computing, data science & engineering (confluence). — IEEE, 2018. — С. 43–48.
- GuangJun L. et al. Spam detection approach for secure mobile message communication using machine learning algorithms //Security and Communication Networks. — 2020. — Т. 2020. — С. 1–6.
- Lai C. C. An empirical study of three machine learning methods for spam filtering //Knowledge-Based Systems. — 2007. — Т. 20. — №. 3. — С. 249–254.
- Amer E., El-Sappagh S. Robust deep learning early alarm prediction model based on the behavioural smell for android malware //Computers & Security. — 2022. — Т. 116. — С. 102670.

