





Процент аудитории, которая пользуется интернетом растет, увеличиваясь каждый год на 2 % начиная с 2000 года. Соответственно, в результате ежедневного увеличения интернет пользователей, каждый день растет и количество созданных ими данных. Поисковые системы или социальные сети производят огромное количество данных, которые хранятся в одном месте, на кластерах частных предприятий и фирм. Подобные предприятия хотят придать ценность, не только путем поиска данных, но также и путем выстраивания сложного анализа и обработки данных. В этой статье мы рассмотрим, как новые требования привели к созданию новых инструментов для обработки данных. Мы также, детально рассмотрим две платформы Apache Hadoop et Apache Spark.
Недостатки реляционных баз данных
Эдгар Кодд в 1970—х годах создал реляционную модель данных, и почти все использовали реляционные базы данных до конца 2000-х годов. Математическая модель, на основе которой они созданы, имеет следующие преимущества: согласованность, быстрый доступ к данным на унифицированном языке SQL, возможность делать сложные запросы.
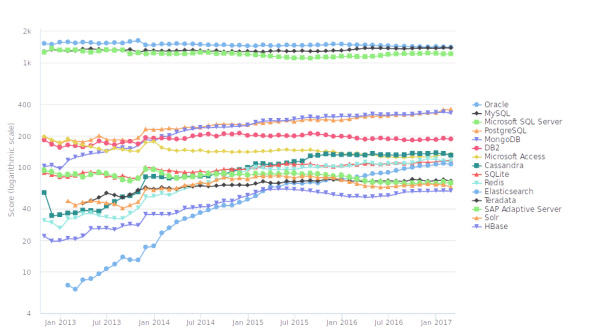
Рис. 1. Популарность баз данных. Нерелационные базы завоёвывают популярность за последние 5 лет. Источник: db-engines.com
Такие базы составляют большинство. Но данные, которые можно сегодня найти в больших компаниях и исследовательских проектах, требуют новых свойств обработки, которыми не обладают традиционные реляционные базы данных.
Первое из этих свойств — это возможность управлять огромным объёмом данных. И хотя реляционные базы работали продуктивно с несколькими миллионами записей, с миллиардами им работать уже труднее. Подобные большие объёмы невозможно хранить на одном сервере. К тому же, компании предпочитают иметь много дешёвых серверов, чем обладать, например, одним суперкомпьютером, стоимость которого в разы больше. Это новое качество данных потребовало нового подхода к их хранению и обработке. Для решения этой проблемы были созданы первые базы и фреймворки, которые стали известны под общим названием Big Data.
Второе свойство — это более свободная структура данных. Первые базы данных NoSQL стали популярными, благодаря их ориентированности на обработку документов, то есть благодаря тому, что они «умели» хранить и запрашивать данные, у которых нет общей структуры.
Нужно заметить, что традиционные структуры реляционных хранилищ данных не всегда подходят под новые типы данных.
Существует множество решений вышеперечисленных проблем, но мы затронем здесь лишь одну, не менее интересную, чем остальные: обработку данных в среде Hadoop и Spark.
Почему появилась платформа Hadoop
В 2003 году три исследователя компании Google опубликовали статью «The Google Filesystem». В этой статье они объяснили, как они разработали файловую систему, которая могла противостоять сбоям, хранить файлы больших размеров (включая файлы, которые не могут храниться на одном диске) и была оптимизирована под большое количество клиентов. Файловая система работает следующим образом: один из компьютеров кластера содержит «мастер», который управляет метаданными файлов, разделяет их на множество фрагментов одинакового размера и определяет их местонахождение на разных узлах кластера. Каждый фрагмент отправляется на несколько узлов, чтобы предотвратить потерю данных при сбое одного или нескольких серверов. При чтении данных нужно запросить у мастера метаданные, но сами данные читаются напрямую с сервера, где они хранятся. Это позволяет увеличить скорость чтения.
Годом позже, в 2004 году, другая команда исследователей Google, в составе которой находился учёный уже работавший над предыдущей статьёй, опубликовала исследование (Simplified Data Processing on Large Clusters) об обработке больших объёмов данных. В этом исследовании они продемонстрировали новый подход к обработке данных, который они назвали MapReduce. MapReduce больше не базируется на реляционной модели данных. В частности, больше нет как таковой СУБД, которая выполняет запросы. Вместо этого пишутся функции преобразования (Map) и агрегирования (Reduce) данных. В этой статье исследователи указывают, что благодаря этой системе Google обрабатывает терабайты данных на тысячах компьютерах ежедневно, и что в случае поломки одного или нескольких компьютеров система будет продолжать свою работу.
Дуг Каттинг, программист, который тогда работал в компании Yahoo над системой поиска документов Lucene и над поисковым роботом Nutch, прочитал эту статью и понял её важность для будущих поисковых систем и обработки больших объёмов данных в целом. Системы, описанные Google в этих статьях, были проприетарны (доступ к коду ограничен). Дуг Каттинг же работал в области свободного программирования. Поэтому он стал с нуля реализовывать концепции Google и внедрять их в систему Nutch. Затем в 2006 году команда, работавшая с Каттингом, отделила от Nutch два других проекта: файловую систему HDFS (Hadoop File System), основанную на принципах, описанных в статье 2003 года, и платформу Hadoop, которая реализовывает принцип MapReduce, описанный Google в 2004 году.
С момента создания проект Hadoop быстро набрал популярность. Разные компании и организации стали применять его в работе для более разносторонних потребностей нежели Yahoo. Он быстро вышел за предела своей начальной роли, то есть из роли поисковой системы, чтобы стать расширенной платформой BigData. Hadoop используют как для обработки научных данных и для анализа системных журналов больших приложений, так и для создания систем машинного обучения.
Как видно, платформа Hadoop появилась изначально, чтобы устранить недостатки традиционных баз данных в сфере индексации данных в поисковых системах. Но эта платформа быстро оказалась хорошим решением проблем, связанных с обработкой больших объёмов данных, распределенных на множестве серверов.
Почему появился Spark
Hadoop стали применять в разных проектах, в том числе и в проектах, связанных с машинным обучением. В действительности, многие обладатели больших объёмов данных пытаются использовать их не только для вычисления статистики или поиска данных, но и для построения моделей, способных прогнозировать изменение тех или иных данных, а также автоматически классифицировать уже существующие данные.
Задолго до создания Hadoop существовали алгоритмы, позволяющие создавать подобные модели (регрессионный анализ, байесовский классификатор, метод k-средних, дерево принятия решений и т. д.). Часто такие алгоритмы трудно или невозможно реализовать на платформе Hadoop. И даже в случае, когда это возможно, время выполнения модели в Hadoop может быть велико. Hadoop обрабатывает данные в циклах Map и Reduce, каждый раз читая и записывая данные на диск.
Изучив эту проблему, Матей Захария в рамках своей диссертации «An Architecture for Fast and General Data Processing on Large Clusters», которую он защитил в 2009 году, начал работать над новой платформой, которая могла бы использовать уже существующие компоненты Hadoop, но позволила бы также реализовать итеративные алгоритмы, более эффективно используя оперативную память компьютеров, не читая лишний раз данные с жёсткого диска.
Первая версия Spark была разработана в 2010 году, и она оправдала ожидания разработчика. Spark позволяет не только проще писать программы, но и работает быстрее Hadoop даже при решении типичных задач Hadoop. Также он предоставляет большое количество готовых инструментов для классических задач машинного обучения. Это способствовало успешному использованию этого продукта во многих областях. В 2014 году Spark побил рекорд по сортировке данных, обработав миллиард записей объёмом 100 терабайтов на 206 компьютерах за 23 минуты. Сегодня он используется тысячами предприятий в мире, включая Facebook и Microsoft.
Классификация методов выполнения запросов в Hadoop и Spark
В реляционных базах данные хранятся в рамках заранее разработанной схемы, и единственный способ получить к ним доступ — это использовать язык структурированных запросов SQL. Как говорилось выше, одна из основных идей Hadoop и Spark — хранить данные без изменений в форме простых файлов в системе, оптимизированной под большие объёмы.
Методы выполнения запросов SQL в Hadoop были разработаны, но они больше не являются доминирующим средством доступа к данным. Вместо них аналитик, желающий получить быстрый доступ к данным и управлять ими, должен написать не простой запрос, а полную программу. Это требует больших временных затрат, но и позволяет реализовывать то, что невозможно было сделать в SQL.
Ниже показано, как строится структура таких программ в Hadoop и Spark.
Архитектура MapReduce в Hadoop
MapReduce — это и парадигма программирования, позволяющая обрабатывать большие объёмы фрагментированных по разным узлам данных.
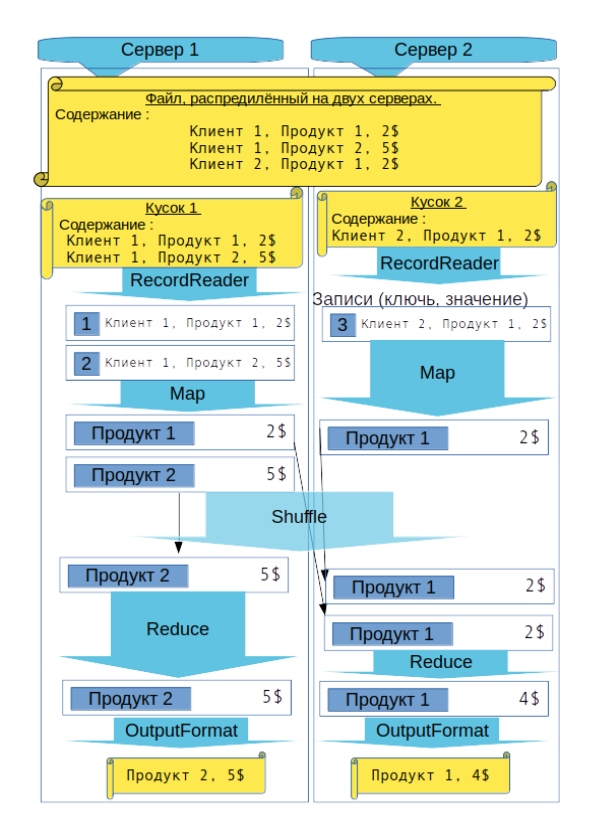
Архитектура MapReduce состоит из 4-х главных компонентов, которые мы рассмотрим подробнее: 1) разделение файлов на записи вида <ключ,значение> (RecordReader), 2) трансформация этих записей (Map), 3) управление сортировкой и передача («перетасовка») данных функциям агрегации (shuffle), 4) сортировка, группирование и агрегация данных (Reduce).
Мы рассмотрим принцип работы каждого из этих компонентов, которые соответствуют каждому этапу программы MapReduce. Чтобы не делать объяснения абстрактными, мы продемонстрируем работу MapReduce на конкретном примере.
Предположим, что у нас есть один текстовый файл, который содержит данные о продажах одного предприятия, и мы пытаемся узнать выручку от продажи каждого продукта, изготовленного предприятием.
Наш файл «продажи» выгладит следующим образом (покупатель, продукт, цена продукта):
Клиент 1, Продукт 1, 2€
Клиент 2, Продукт 1, 2€
Клиент 1, Продукт 2, 5€
Мы хотим узнать результат в следующей форме (продукт, суммарная выручка по нему):
Продукт 1, 4€
Продукт 2, 5€
Для реляционной базы данных мы могли бы написать следующий запрос SQL:
SELECT product, SUM(price)
FROM sells
GROUP BY product
ORDER BY product;
Обработка запроса по технологии MapReduce выглядит иначе.
RecordReader
RecordReader получает фрагмент файла, хранящийся в узле, и создаёт записи в форме <ключ, значение>. Сам файл — всего лишь череда байтов, а ключи и значения имеют тип данных, который может быть определён программистом.
В нашем примере, файл — это всего лишь простой текстовый файл, и нет необходимости писать наш собственный RecordReader. Мы можем использовать класс LineRecordReader, который используется в Hadoop по умолчанию. Он создаёт одну запись для каждой текстовой строки обрабатываемого файла. Ключом записи является номером строки, а значение — это сама строка.
Таким образом, в нашем примере, мы получаем следующий результат работы RecordReader:
|
Ключ |
Значение |
|
1 |
Клиент 1, Продукт 1, 2€ |
|
2 |
Клиент 1, Продукт 2, 5€ |
|
3 |
Клиент 2, Продукт 1, 2€ |
Map
Функция Map отвечает за обработку извлечённых записей. Она должна изменить ключ, который позволит в дальнейшем сгруппировать записи и выполнить агрегацию данных. В результате выполнения этого этапа, данные будут частично отсортированы и записаны на диск перед этапом shuffle.
В нашем примере новый ключ — это название продукта, а значение записи — его цена (имя клиента удаляется из новой записи). Записи затем будут сгруппированы по названию продукта и для каждого продукта вычислена суммарная выручка. Таким образом, функция map отвечает за обработку строки, которую ей на вход автоматически передал RecordReader, и формирование записи <продукт, цена продукта>.
Важно отметить, что это только в нашем примере функция map создаёт лишь одну новую запись для каждой прочитанной записи. В других случаях функция может создавать множество записей или же не создавать их вообще.
В нашем примере, функция map создаёт следующие записи (может быть на разных узлах кластера):
|
Ключ |
Значение |
|
Продукт 1 |
2 |
|
Продукт 2 |
5 |
|
Продукт 1 |
2 |
Shuffle
Этап shuffle делает так, чтобы все записи, имеющие одно и тоже значение ключа, могли быть обработаны вместе одной функцией reduce. До этого этапа записи с одним значением ключа могут находиться на разных узлах.
Этап shuffle организован так. Экземпляр reduce определяет, что функция map завершилась на каком-то узле, открывает локальный файл и читает раздел файла с новыми записями, которые предназначены для этого экземпляра reduce. В общем случае записи передаются по сети. Разные экземпляры reduce могут быть запущены Hadoop на разных узлах.
В нашем примере две записи со значением ключа «Продукт 1» будут обработаны одним экземпляром reduce, а третья запись со значением ключа «Продукт 2» — другим экземпляром (конечно, если значения хеш-функции для значений «Продукт 1» и «Продукт 2» не совпадают).
Reduce
Экземпляр reduce группирует записи и передаёт на вход функции reduce эти группы по одной. Например, 1-й экземпляр reduce сформирует группу <Продукт 1, (2, 2)>, а соответствующая функция reduce поместит в выходной поток запись <Продукт 1, 4>.
Таким образом, мы получим следующий результат:
|
Ключ |
Значение |
|
Продукт 1 |
4 |
|
Продукт 2 |
5 |
OutputWriter
Полученные результаты записываются на диск. Роль OutputWriter — конвертировать записи в последовательность байтов файла, который будет записан на диск.
Ниже приведена схема, демонстрирующая взаимосвязь рассмотренных выше этапов MapReduce.
Схема, объясняющая функционирование MapReduce (на основе нашего примера)
Программирование в Hadoop
В Hadoop программы map и reduce пишутся на языке Java, следуя вышеописанной структуре.
Надо отметить, что лишь в нашем примере данные — это простые текстовые файлы. Но вообще Hadoop может поддерживать любой формат файлов. Для структурированных данных (как в нашем примере) в реальности программы используют специализированные форматы, как например Parquet.
Также нужно отметить, что сам аналитик не обязательно каждый раз пишет новую программу для Hadoop. Существуют расширения, которые позволяют формулировать запросы на более простом языке. Эти запросы транслируются в последовательность заданий Hadoop. В качестве примеров можно назвать следующие расширения: Apache Pig (это средство имеет свой собственный язык программирования), Hive (это расширение выполняет запросы в языке SQL).
Hive анализирует запрос на SQL и выполняет для него ряд операций Map и Reduce (заданий). Это позволяет избежать написание сложных программ на Javа в случае, если необходимо выполнить простой запрос. Но для каждого задания Hadoop читает исходные данные с диска и пишет результаты на диск. Это повышает надёжность системы, но существенно увеличивает время выполнения запроса.
Программирование в Spark
Spark был создан для того, чтобы устранить недостатки Hadoop, но в тоже время использует множество его идей и компонентов.
Spark имеет гибкую модель программирования и позволяет легко «сцеплять» циклы MapReduce (последовательность заданий). Также он позволяет хранить данные в оперативной памяти, чтобы подвергать их многократной обработке. Hadoop требует написания программ на языке Java, а Spark позволяет писать их также на языках Python, Scala и R.
Spark предлагает свою эффективную имплементацию SQL для реляционных запросов, которая совместима с Hive.
Основная концепция Spark: RDD
Основа функционирования Spark — это RDD (Resilient Distributed Dataset). RDD — это своеобразная таблица (коллекция), где хранятся упорядоченные типизированные данные. Тип данных может быть парой <ключ, значение>, как в Hadoop, но также может являться любым типом данных используемого языка программирования (Java, Scala, Python и др.). Программа в Spark позволяет запускать операции высокого уровня, используя эти данные. Эти операции выполняются параллельно и, таким образом, увеличивается производительность системы.
Spark может использовать файловую систему Hadoop: он может создавать RDD из файла, хранящегося в HDFS, а также читать данные из базы данных Hive.
Обработка данных RDD
После того, как RDD создан, можно выполнять разнообразные действия с этой таблицей, включая операции Map и Reduce, описанные выше. Как и в Hadoop, операция shuffle автоматический выполняется, чтобы выполнить группирование данных. Но с другой стороны, Spark может выполнять и такие операции, которых нет на Hadoop. Spark обладает такой возможностью, как отправка данных с главного узла на все остальные с помощью протокола торрент (broadcast). Другая возможность — это управление размерами разделов данных (partitions), которое позволяет контролировать эффективность выполнения этапа Shuffle.
Основная разница между технологиями MapReduce в Hadoop и Spark заключается в том, что операции, которые указаны в программе Spark, не выполняются сразу, когда они встречаются. Вместо этого Spark строит граф действий, которые выполняются только тогда, когда их результаты нужны для дальнейшей обработки. Это позволяет Spark выполнять оптимизацию, которую Hadoop не мог делать. Spark знает заранее, какие данные будут нужны и в каком месте, а также может обрабатывать поток данных в кластере, не записывая на диск промежуточные файлы.
Spark предлагает три основных типа операций:
- Трансформации — это ленивые операции, которые не выполняются сразу, а участвуют в построении графа. Они из одного RDD формируют новый RDD. Это главные операции, которые обрабатывают данные. К ним относятся операции map, reduceByKey, group, sort и др.
- Действия. Они выполняют операции, описанные в одном месте графа, и возвращают одно значение. Они являются единственным способом получить доступ к результатам трансформаций. Действия выполняются при обращении к таким методам, как reduce, collect, saveAsTextFile и др.
- Операции сохранения. Они позволяют оптимизировать программы с указанием, какие данные должны сохраняться после одной трансформации, чтобы их можно было бы снова использовать позже. Операции можно вызывать с такими методами, как cache и persist.
Конкретный пример использования Spark
Ту программу, которую мы взяли как пример для описания функционирования MapReduce, можно тоже реализовать на платформе Spark. В Spark программа состояла бы из двух основных операций: одна трансформация, которая читает записи, и одно действие, которое сохраняет сумму выручки для каждого вида продукта.
Программа на scala с использованием RDD приведена ниже

Важно отметить, что операции начинают выполняться только в последней строке кода. До неё мы использовали только описание трансформаций.
Программа на scala с использованием SQL
Spark позволяет использовать язык SQL, чтобы обрабатывать данные, даже когда их источником не является база данных. Поэтому можно реализовать программу нашего примера еще проще, используя SQL. Spark сам будет строить нужные фазы map и reduce, чтобы получить результат. Код этого варианта немного объёмнее чем предыдущий. Но он всё-таки меньше, чем программа на Java, которую надо было бы писать в Hadoop. К тому же, он работает эффективнее, чем предыдущий вариант, когда объём данных большой.

Действительно, и хотя мы добавляем анализ SQL и трансформирование запроса в циклы MapReduce, мы всё-таки уменьшаем время, убирая необходимость использовать типы данных Java и предоставляя Spark больше свободы для оптимизации расчётов.
Заключение
Подытоживая вышесказанное, надо отметить, что недостатки реляционных баз данных в области хранения и обработки больших объёмов данных «спровоцировали» появление новых подходов к обработке данных. Среди этих подходов следует выделить модель распределённых вычислений MapReduce. Платформа Hadoop стала одной из первых, которая реализовала эту модель. Она используется до сих пор. Но в 2010 году была разработана платформа Spark, которая добавляет интересные инструменты и часто работает быстрее. Как мы видели при рассмотрении нашего небольшого примера, эти платформы позволяют запрашивать данные, используя даже SQL. В этой статье не рассмотрена операция соединения таблиц (аналог оператора JOIN в SQL). Мы решили намеренно не включать её в эту публикацию, т. к. вопрос соединения распределённых в кластере данных является непростым, и эта тема будет освещена в следующей нашей статье.
Литература:
- http://db-engines.com/en/
- http://db-engines.com/en/ranking_trend
- https://en.wikipedia.org/wiki/Relational_database_management_system
- https://en.wikipedia.org/wiki/Apache_Hadoop
- https://en.wikipedia.org/wiki/Apache_Spark
- https://en.wikipedia.org/wiki/Matei_Zaharia
- Статистики об использовании интернета: http://www.itu.int/ITU-D/ict/statistics/ict/
- Статья Google о новой файловой системе: http://www.cs.cornell.edu/courses/cs614/2004sp/papers/gfs.pdf
- Статья Google о MapReduce: https://static.googleusercontent.com/media/research.google.com/en//archive/mapreduce-osdi04.pdf
- http://hadoop.apache.org/
- список компаний: https://wiki.apache.org/hadoop/PoweredBy
- документация: http://hadoop.apache.org/docs/stable/
- Вики проекта: https://wiki.apache.org/hadoop/
- исходный код Hadoop: https://github.com/apache/hadoop
- Официальный сайт: http://spark.apache.org/
- Spark programming guide: http://spark.apache.org/docs/latest/programming-guide.html
- О Spark SQL: http://spark.apache.org/docs/latest/sql-programming-guide.html
- Mastering Apache Spark 2: https://www.gitbook.com/book/jaceklaskowski/mastering-apache-spark/details
- О внутреннем функционировании: http://datastrophic.io/core-concepts-architecture-and-internals-of-apache-spark
- Исходный код Spark: https://github.com/apache/spark
- Качественная общая информация: https://www.quora.com/topic/Apache-Spark
- Презентация второй версии Spark создателем: https://www.youtube.com/watch?v=Zb9YW8XjxnE
