Синтезом речи называется процесс восстановления формы речевого сигнала по его параметрам. Синтез речи по тексту может быть использован в информационно-справочных системах, для помощи людям с нарушениями опорно-двигательного или зрительного аппаратов, выдачи информации о технологических процессах. В целом речевой синтез может потребоваться во всех случаях, когда получателем информации является человек.
Обобщенную схему синтезатора речи можно представить следующим образом:
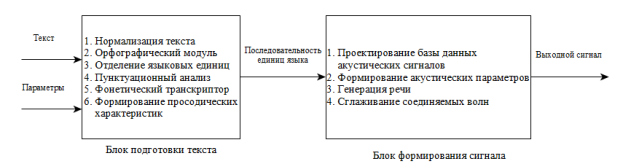
Рис. 1. Схема синтезатора речи
Входящим элементом системы является текст, поэтому необходимо отметить, что подход к решению проблемы синтеза речи главным образом зависит от языка. В каждом языке есть свои особенности произношения, фонетика. Именно поэтому первая и наиболее важная задача системы синтеза речи — анализ и подготовка текста конкретного языка.
Один из вариантов синтеза речи — использование комбинации конкатенативного метода и формантного синтеза. При такой конфигурации необходимый выходной сигнал создается на основе конкатенации фрагментов акустического сигнала, вырезанных из разговора спикера-донора. Таким образом, для создания системы синтеза речи необходимо составление базы данных фрагментов сигнала. Затем при синтезе фрагменты из базы данных изменяются по определенным правилам. Это требуется для того, чтобы дать сигналу необходимые просодические характеристики, такие как частота основного тона, длительность или энергия. Оперируя этими характеристиками, можно соединить фрагменты в единый сигнал без скачков.
Блок подготовки (нормализации) текста разделяется на следующие подсистемы:
- Начальная подготовка.
На этой стадии определяются особые части в тексте, такие как цифры, дроби, даты, время и другие. Эти данные преобразовываются в последовательность слов. Данный преобразователь для каждого типа таких спецсимволов проектируется отдельно в зависимости от языка синтезатора и контекста.
- Многие системы синтеза речи осуществляют проверку орфографии.
В таком случае необходимо спроектировать или экспортировать словарь и реализовать возможность отмены изменений и сохранения новых введенных пользователем слов в такой словарь.
- Отделение первых единиц языка — слов.
Входной текст преобразуется в список словоформ. Знаки препинания также оставляются в этом списке, поскольку они необходимы при дальнейшей обработке.
- Анализ пунктуации.
Наиболее простой способ реализации такого анализа — просмотр знаков препинания и расстановка пауз различной длительности в предложениях согласно просодическим правилам. Такие паузы повышают натуральность сгенерированного речевого сигнала. Примерную длительность пауз можно рассчитать экспериментально. [4]
Таблица 1
Паузы при синтезе речи
|
Знак препинания |
Длительность |
|
Точка(.) |
1 |
|
Восклицательный знак(!) |
0,9 |
|
Знак вопроса(?) |
0,8 |
|
Запятая(,) |
0,5 |
На данном этапе из сформированного ранее списка словоформ все знаки препинания заменяются на специальные команды, которые будут считаны в блоке формирования сигнала.
- Фонетический транскриптор.
Транскриптор обрабатывает полученный список слов, преобразуя их в необходимый набор минимальных единиц языка. В разработке транскриптора можно опираться на базу данных транскрипции различных слов, однако такая база будет занимать очень большое количество памяти. Другой подход связан с хранением базовых правил преобразования словоформ в фонемы. Необходимо спроектировать алгоритм, использующий такие правила и пропускать через него каждое слово.
- Формирование просодических характеристик.
Под просодическими характеристиками подразумевается тон, акцент, ритмика языка. Физическими аналогами этих понятий выступают частота основного тона, энергия и длительность сигнала, которые понадобятся для генерации речевого сигнала.
Рассмотрим основные подсистемы блока формирования сигнала.
- Проектирование базы данных сигналов
База данных акустических сигналов — базовая составляющая любых систем синтеза речи, построенных с помощью данного метода. Размерность элементов может быть различной в зависимости от реализации и предметной области. Это могут быть фонемы, аллофоны, или даже целые слова [1]. Формат для каждой конкретной системы синтеза речи определяется из учета особенностей языка и реализации. Языковые единицы, используемые в базе данных, лучше всего хранить в формате wav в связи с удобством обработки информации в данном формате.
Процесс создания базы данных состоит из 2 стадий:
а. Начальная стадия, на которой сохраняются все языковые единицы, произнесенные спикером-донором.
б. Языковые единицы обрабатываются перед занесением в базу данных. Обработка происходит по следующему принципу:
-
Звуковые сигналы записываются с частотой 16 кHz, что позволяет определить период T с точностью до
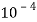 .
.
- Из записанных сигналов удаляются посторонние шумы. Для этого можно использовать алгоритм разделения на речь и паузы.
Предполагается, что первые 10 фреймов записанного сигнала не содержат речевой сигнал. Для этой части сигнала вычисляются среднее значение и дисперсия величин ![]() и
и ![]() , получая тем самым статистические характеристики шума.
, получая тем самым статистические характеристики шума.
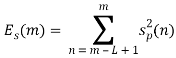
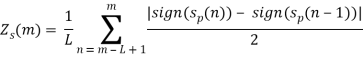
Где ![]() равен 1, если
равен 1, если ![]() ≥ 0 и -1 в противном случае; L – число фреймов звукового сигнала.
≥ 0 и -1 в противном случае; L – число фреймов звукового сигнала.
Учитывая данные характеристики и максимальные значения величин ![]() и
и ![]() , вычисляется пороговое значение
, вычисляется пороговое значение ![]() для кратковременной энергии речевого сигнала и пороговое значение
для кратковременной энергии речевого сигнала и пороговое значение ![]() для числа нулей интенсивности сигнала.[4]
для числа нулей интенсивности сигнала.[4]
![]()
![]()
Где 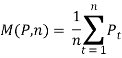 ,
, 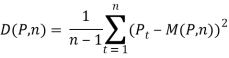
Если фрейм ![]() содержит речь, тогда новой переменной
содержит речь, тогда новой переменной ![]() присваивается значение 1, в противном случае 0. Необходимо таким образом присвоить значение 1 фреймам с кратковременной энергией
присваивается значение 1, в противном случае 0. Необходимо таким образом присвоить значение 1 фреймам с кратковременной энергией ![]() . Таким образом, фильтрация сводится к следующей процедуре. Рассчитаем для
. Таким образом, фильтрация сводится к следующей процедуре. Рассчитаем для ![]() значения
значения ![]() таким образом:
таким образом:
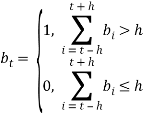
С помощью этого метода определяется непрерывная часть речи. Затем производится попытка расширить эту границу. Двигаясь от границы (налево от левой границы и направо от правой), производится проверка числа нулей интенсивности ![]() с порогом
с порогом ![]() . Значение не должно превышать 20 фреймов слева от левого значения. В случае, если число превышает его, началом речи обозначается место пересечения. Это же справедливо для 20 фреймов справа от правой границы. Если обе части перекрыты, их можно объединить в одну. Таким образом определяется непрерывные части звука.
. Значение не должно превышать 20 фреймов слева от левого значения. В случае, если число превышает его, началом речи обозначается место пересечения. Это же справедливо для 20 фреймов справа от правой границы. Если обе части перекрыты, их можно объединить в одну. Таким образом определяется непрерывные части звука.
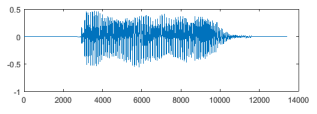
Рис. 2. Сигнал до использования алгоритма
Рис. 3. Сигнал после использования алгоритма
Эти стадии проделываются для каждого записываемого в базу данных сигнала.
- Формирование акустических параметров звукового сигнала.
Основная задача на этом этапе — определение энергетических, временных и частотных характеристик, которые будут отнесены к языковым единицам.
- Генерация речевого сигнала.
При соединении элементов базы данных акустических сигналов возникают искажения речевого сигнала. Для предотвращения данного эффекта применяется локальное сглаживание левой(i) и правой(j) соединяемых волн с помощью следующего алгоритма [3]:
а. При укорочении периода.
− От последнего (нулевого) отсчёта левой (i-й) стыкуемой волны отсчитываем 3-й отсчёт, для которого рассчитываем новое среднее значение Si3m из значений i-й и j-й волн по формуле:
− j-й волн по формуле:
![]()
− Далее процесс повторяется по следующей рекуррентной схеме вплоть до получения последнего нового значения для 0-го отсчёта i-й волны:
![]()
![]()
![]()
− Затем рассчитываются новые значения j-й волны:
![]()
![]()
![]()
Процесс заканчивается после получения нового значения для 4-го отсчёта j-й волны:
![]()
б. При удлинении периода алгоритм сглаживания аналогичен. Сохраняются также условия начала и конца процесса сглаживания. Добавляется лишь дополнительный k-й участок, повторяющий значение последнего (0-го) отсчёта i- волны, который вначале играет роль j-го участка, а затем i-го. Иначе говоря, единообразный алгоритм обеспечивает локальное сглаживание, начиная с 3-го отсчёта i–й волны и кончая 3–м отсчётом j–й волны независимо от присутствия или отсутствия дополнительного участка.
Нормализированный по длительности фонем, общему уровню амплитуд и плавно соединённый из различных фрагментов речевой сигнал изменяется, исходя из параметров, полученных на этапе 6 подготовки текста. Эти параметры нужны для того, чтобы сформировать контур частоты основного тона и наложить его на исходный речевой сигнал. После этого на сигнал накладывается амплитудные огибающие [5]. Благодаря этому можно получить нужную интонацию речевого сигнала.
Придерживаясь данных общих правил, на выходе можно получить качественный звуковой сигнал, имитирующий речь дикотра-донора.
Литература:
- Сорокин В. Н. Синтез речи. — М.: Наука, 1992. – 392 с.
- Фролов А., Фролов Г. Синтез и распознавание речи. — М.: Москва, 2008 г.
- Лобанов Б. М. Ретроспективный обзор исследований и разработок Лаборатории распознавания и синтеза речи. — Сб. «Автоматическое распознавание и синтез речи», ИТК НАН Беларуси, Минск, 2000.
- U. R. Aida–Zade, C. Ardil and A. M. Sharifova. The Main Principles of Text-to-Speech Synthesis System. — International Journal of Computer, Electrical, Automation, Control and Information Engineering Vol. 7, № 3, 2013.
- М. Н. Калимолдаев, Е. Н. Амиргалиев, Р. Р. Мусабаев Синтез интонационной составляющей речевого сигнала с применением сплайновой интерполяции. — КН МОН РК.

