Председатель совета директоров Google Эрик Шмидт утверждает: «С момента возникновения цивилизации до 2003 года человечество создало 5 эксабайтов данных. Теперь мы создаем 5 эксабайтов за два дня, и скорость лишь увеличивается». Это показывает, насколько актуальна проблема обработки и анализа больших объёмов данных.
Сегодня начинают терять актуальность прежние технологии обработки и анализа данных в следствие того, что объём данных стремительно увеличивается. Разумеется, когда база данных имеет сравнительно небольшой объём, а вычислительных средства справляются с их обработкой, то никаких новых проблем не возникает, но со стремительным ростом объёмов информации появляется необходимость в новых технологиях и методах её обработки. Для рассмотрения данной проблемы был введён термин Big Data (рус. Большие Данные) — совокупность подходов, инструментов и методов обработки данных огромных объёмов, которые призваны совершать три операции:
‒ обрабатывать большие по сравнению со «стандартными» сценариями объемы данных;
‒ уметь работать с быстро поступающими данными в очень больших объемах. То есть данных не просто много, а их постоянно становится все больше и больше;
‒ они должны уметь работать со структурированными и плохо структурированными данными параллельно в разных аспектах.
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
- Горизонтальная масштабируемость. Поскольку нету ограничений на объём хранимой информации, система обработки и хранения больших данных должна быть расширяемой: с увеличением объёма данных необходимо пропорционально улучшать аппаратную конфигурацию системы.
- Отказоустойчивость. Возможные выходы из строя оборудования не должны оказывать существенного влияния на методы работы с большими данными.
- Локальность данных. При использовании больших распределенных систем требуется соответственно множество вычислительных машин. И если физически данные расположены на одном сервере, а обработка выполняется на другом, то это приводит к увеличению расходов, превышающих порой расходы на саму обработку данных. Поэтому одним из важнейших принципов проектирования Big Data-решений является принцип локальности данных — по возможности обрабатываем данные на той же машине, на которой их храним.
Для выполнения перечисленных принципов существует метод MapReduce.
MapReduce — это прежде всего модель распределенной обработки больших объемов данных на компьютерных кластерах, предложенная компанией Google. Принцип работы представлен на рис. 1.
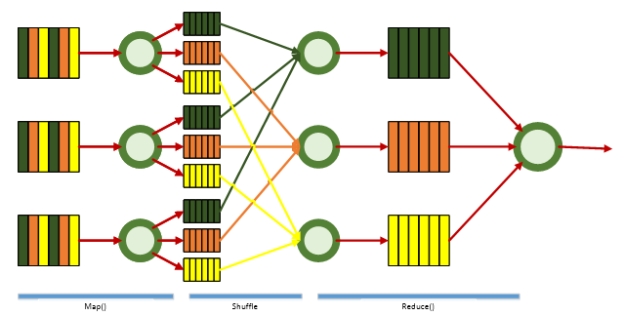
Рис. 1. Принцип работы MapReduce
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. Пользователь определяет функцию map(). Работа этой стадии заключается в предобработке и фильтрации данных. Пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество может как вообще не содержать значений, так содержать несколько пар ключ-значение. Что будет находится в ключе и в значении — определяет пользователь, но ключ — очень важный объект, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Вэтой стадии вывод функции map «разбирается по корзинам» — каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce. Также стоит отметить, что данный этап проходит незаметно для пользователя
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Литература:
- Donald Miner, Adam Shook. MapReduce Design Patterns: Building Effective Algorithms and Analytics for Hadoop and Other Systems. —:, 2012. — 230 с.
- Большие данные // Википедия. URL: https://ru.wikipedia.org/wiki/Большие_данные (дата обращения: 13.03.2017).
- Что такое Big Data? // ПостНаука. URL: https://postnauka.ru/faq/46974 (дата обращения: 13.03.2017).

