В представленной работе рассматриваются наиболее интересные и важные особенности поисковых движков и способы конструирования индексации с целью повышения скорости поиска в рамках контент-менеджмент системы Adobe Experience Manager. Данные основываются на открытых источниках документации технологий Apache Foundation, а так же официальной документации Adobe Experience Manager.
Ключевые слова: контент-менеджмент система, oak, lucene, индексация, репозиторий контента, SQL-2
Adobe Experience Manager изначально не индексирует содержимое без дополнительной настройки для его репозитория контента — для этих целей необходимо создавать отдельно конфигурируемые индексы, ровно так же, как и для реляционных баз данных. Если для определённого запроса нет конкретного индекса, значит, весь репозиторий будет пройден (англ. traversed). Из-за этого запрос, скорее всего, будет очень долгий. В таком случае, когда движок Oak обнаружит такой запрос, в логах будет выведено соответствующее сообщение, предупреждающее о медленном запросе.
Jackrabbit поддеживает следующие языки запросов:
– XPATH;
– SQL;
– SQL-2;
– JQOM.
- Типы идндексов ивычисление «стоимости» выполнения запроса
Apache Jackrabbit позволяет подключать различные индексы к использованию в запросах к репозиторию:
– стандартный индекс — PropertyIndex, определение которого находится в самом репозитории;
– внешний полнотекстовый индекс — конкретная реализация которого может быть ApacheLucene или ApacheSolr;
– Traversal Index — индекс, используемый в случае, когда никакой другой индекс не задействован. Это означает, что данные не индексируются и все ячейки репозитория будут пройдены в поисках данных, подходящих под запрос.
Если для запроса доступны сразу несколько индексов, то для каждого доступного индекса будет высчитано время выполнения. Oak затем выберет наилучший, по его мнению, индекс.
На рисунке 1.1 представлен схематически описанный процесс.
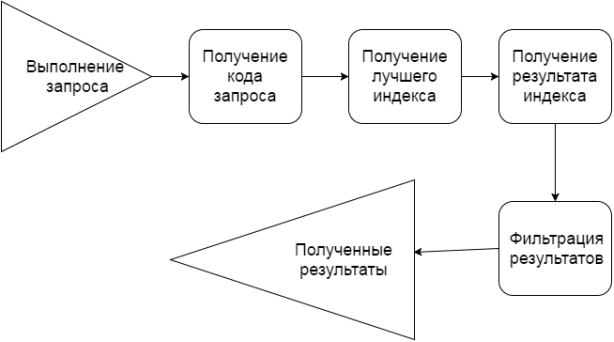
Рисунок 1.1. Схема высокоуровневого представления механизма выполнения запроса движком Apache Oak
- Конфигурация индексов
Индексы в Adobe Experience Manager конфигурируются в репозитории в виде ячеек и находятся под ячейкой oak:index. Чтобы система распознала данную ячейку как конфигурацию индекса, ей следует задать тип oak:QueryIndexDefinition.
2.1 PropertyIndex
Property Index подходит для запросов, которые используют свойства, но не задействуют полнотекстовый поиск. У Property Index существуют следующие параметры конфигурации:
– type — тип индекса, в данном случае «property»;
– propertyNames — показывает список свойств, которые будут храниться в индексе;
– флаг unique — установлены в значение «true», добавляет уникальность поля;
– declaringNodeTypes — позволяет указывать определённый тип ячейки, которая может быть индексирована таким образом;
– reindex — флаг, установленный в значение «true», запустит переиндексацию всех индексов.
2.2 Ordered Index
Ordered Index — расширение Property Index. Он позволяет устанавливать порядок индексируемого свойства в репозитории. У Ordered Index существуют следующие параметры конфигурации:
– type — тип индекса, в данном случае «ordered»;
– propertyNames — показывает список свойств, которые будут храниться в индексе;
– reindex — флаг, установленный в значение «true», запустит переиндексацию всех индексов;
– опциональный параметр direction — может иметь значения убывания и возрастания — «ascending» и «descending» соответственно. По-умолчанию выставлено значение «ascending»;
– async — установка типа индекса как асинхронного.
2.3 LuceneFullTextIndex
Полнотекстовый поиск в Adobe Experience Manager представлен средствами Apache Lucene и доступен с шестой версии контент-менеджмент системы. Если полнотекстовый поиск сконфигурирован, то все запросы, имеющие свойство полнотекстового поиска станут использовать этот индекс.
Если полнотекстовый поиск не сконфигурирован, то запросы имеющие свойство полнотекстового поиска могут работать не так, как ожидается. Базовый движок имеет функции полнотекстового поиска, но не имеет всех возможностей Lucene.
Lucene Full Text Index имеет следующие параметры, доступные для конфигурации:
– type — тип индекса, в данном случае «lucene»;
– propertyNames — показывает список свойств, которые будут храниться в индексе;
– includePropertyTypes — определяет, какой набор типов свойств будет подходить под это определение индекса;
– excludePropertyNames — определяет, список типов свойств, которые не будут индексироваться данной конфигурацией;
– reindex — флаг, установленный в значение «true», запустит переиндексацию всех индексов;
– async — установка типа индекса как действующего асинхронно.
На рисунке 2.1 показана примерная конфигурация Luene полнотекстового индекса в репозитории.

Рисунок 2.1. Примерная конфигурация Luene полнотекстового индекса в репозитории
- Рекомендации по выбору типа индекса
В первую очередь архитектору проекта следует определить: следует ли вообще использовать индексацию свойств репозитория в данном случае. Если запрос будет выполнен единожды или иногда в периоды, когда система не нагружена, возможно, использование индексации станет излишним.
После создания индекса, каждый раз как данные репозитория обновляются, индекс должен быть так же обновлён. Так как это влечёт дополнительные издержки для системы, индексы должны создаваться только тогда, когда они действительно необходимы.
Индексы используются только тогда, когда индексируемые данные достаточно уникальны, чтобы оправдать использование. Представьте себе индекс, как книгу и темы, которые она покрывает. Когда индексируется набор тем текста, обычно будет сотни или тысячи точек входа, позволяющих Вам быстро попасть в нужную часть по ключевому слову. Но если этот индекс содержит всего две или три точки входа, указывающих на пару-сотню страниц, индекс будет не нужен. Такой же подход применим к индексам базам данных. Если имеется всего несколько уникальных значений, значит нет необходимости в индексировании.
3.1 Lucene Index или Property Index?
Lucene Index были представлены в Oak версии 1.0.9 и предлагают мощные оптимизации над Property индексацией.
Если выбор стоит между Lucene и Property индексами, то следует учитывать следующее:
– Lucene индекс предлагает намного больше возможностей, чем Property индекс. Например, Property индекс может индексировать только единственное свойство, тогда как Lucene может и индексировать несколько;
– Lucene индекс асинхронный. С одной стороны это даёт прирост производительности, но с другой стороны это влечёт за собой задержку между тем, как данные записываются в репозиторий и когда закончится обновление индекса. Если важно иметь запросы возвращающие 100 % точные результаты, следует выбирать Property индекс;
– будучи асинхронным, Lucene индекс не может выставлять уникальные значения данных. Если это является необходимостью, то следует выбирать Property индекс.
В целом, рекомендуется использовать Lucene Index, за исключением случаев, когда есть острая необходимость использовать именно Property Index.
Заключение
Рассмотренные виды конфигурации поиска являются основными в контент-менеджмент системе Adobe Experience Manager и репозитории контента Apache Jackrabbit 2. Предложенные решения по оптимальному выбору технологий поиска основываются на предпочтениях разработчиков самих индексов и лучших практик разработки сайтов под управлением контент-менеджмент системы Adobe AEM.
Литература:
- Lunka, R. D. Adobe Experience Manager: Classroom in a Book: A Guide to CQ5 for Marketing Professionals [Текст] / Adobe Press, 2013. — 368 с.
- Closser, S. Adobe Experience Manager Quick-Reference Guide: Web Content Management [Текст] / Adobe Press, 2013. — 240 с.
- Adobe Corporation. Adobe Experience Manager Documentation [Электронныйресурс]. URL: https://docs.adobe.com (Дата обращения: 29.05.2016).
- Adobe Corporation. Adobe Blogs — Experience Delivers [Электронныйресурс]. URL: http://blogs.adobe.com/experiencedelivers (Дата обращения: 29.05.2016).
- The Apache Software Foundation. Apache Felix Documentation [Электронныйресурс]. URL: http://felix.apache.org/documentation.html (Датаобращения: 29.05.2016).

