Индексирование таблиц в базах данных является отличным средством повышения производительности SQL-запросов. Физически все данные таблиц хранятся в файлах, которые разбиты на страницы (стандартный размер — 8КБ), без соблюдения какой-либо физической структуры. Индексы упорядочивают данные таблиц, оптимизируя время поиска данных (подобно бинарному поиску по упорядоченному массиву данных).
Глобально индексы можно разделить на два типа: кластеризованные и некластеризованные. Оба структурируют данные по индексируемому столбцу (столбцам) в сбалансированное дерево (B-Tree), однако кластеризованные индексы физически перераспределяют данные в файлах, тогда как некластеризованные создают отдельное дерево индексов, листья которого содержат ссылки на кортежи, согласно значениям индекса.
Оба механизма имеют свои преимущества и недостатки. Кластеризованный индекс может быть более эффективным за счет прямого доступа к записям таблицы. К сожалению, это влечет за собой последствия: временные затраты на перестройку и поддержания такого индекса выше, частое обновление данных в таблице приводит к дефрагментации файла, а также нельзя создать более одного такого индекса для таблицы.
В свою очередь, некластеризованные индексы требуют меньше времени на поддержание и перестройку, обладают более гибкими возможностями (например, создание фильтрованного индекса, о котором речь пойдет ниже), но требуется дополнительное время на обращение к самим данным по ссылкам. Также есть возможность хранить таблицу не построчно, а постолбцово (columnostore), в таком случае поиск сначала происходит по определенному столбцу, что может существенно ускорить процесс, а затем уже составляются необходимые кортежи. С другой стороны, это сопряжено с временными затратами на поддержание индекса, а так же на само составление кортежей, так как в файлах данные будут храниться по столбцам.
В данной статье будут приведены результаты работы, цель которой — изучить влияние использования различных индексов на скорость выполнения запросов к базе данных. Тестировать различные запросы будем на таблицах, содержащих два поля: числовое и текстовое. Таблицы будут заполнены случайными данными (числа до 1000000 в числовом поле и строка из 10 символов английского алфавита — в текстовом). Проверять скорость выполнения запросов будем на разных объемах данных: 10000, 100000, 1000000 и 10000000 записей.
Изначально таблицы не будут проиндексированы или секционированы. Сравнивать индексы будем по двум параметрам: эффективность относительно неиндексированной таблицы и увеличение времени выполнения запроса относительно увеличения объема данных.
Для начала, рассмотрим время выполнения запросов с выборкой только проиндексированного столбца. Будем рассматривать запросы на выборку по всей таблице с сортировкой, группировкой по числовому столбцу, выборку по условию (≈40 % от всей таблицы) и с группировкой по условию. Примеры запросов представлены на Рис. 1:
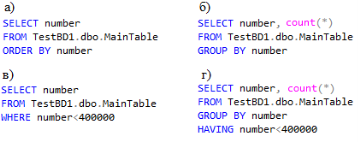
Рис. 1.Запросы к таблицам базы данных а) выборка всей таблицы с сортировкой; б) группировка по числовому столбцу; в) выборка по условию; г) группировка с условием
Отметим, что при каждом запуске запроса будет происходить очистка буфера. Сделано это для того, чтобы при повторном запуске запроса сервер БД не использовал предварительно скомпилированные данные от предыдущего выполнения. Это важно, так как каждый запрос будет запускаться несколько раз, и будет браться среднее время, чтобы результаты были более объективные. Также результаты запросов будут выводиться в текстовый файл, чтобы вывод данных занимал меньше времени.
Сравнение времени выполнения запросов для таблицы, содержащей 10000 строк, представлены на Рис. 2:
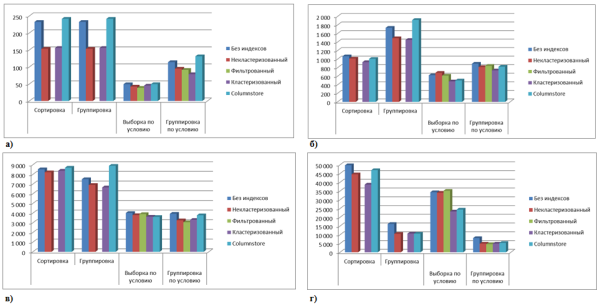
Рис. 2. Время выполнения запросов к таблицам данных а) 10000 строк; б) 100000 строк; в) 1000000 строк; г) 10000000 строк
Заметим, что если выборка идет только по индексу, то для небольших наборов данных индексирование малоэффективно, а columnstore эффективен только для наборов более 10000000 строк, особенно, если учесть затраты на перестройку и поддержание такого способа хранения. Некластеризованный индекс относительно эффективен для любых объемов, но стоит учесть, что он физически перестраивает хранение данных, соответственно, для одной таблицы может быть только один кластеризованный индекс. Некластеризованный индекс имеет в среднем схожую эффективность как с фильтром, так и без, но фильтрованный индекс эффективнее для небольших объемов данных.
Рассмотрим эффективность различных индексов на аналогичных запросах, но с возвратом полных кортежей данных. Снова проведем измерения на таких же объемах данных. Результаты представлены на Рис. 3а — 3г:
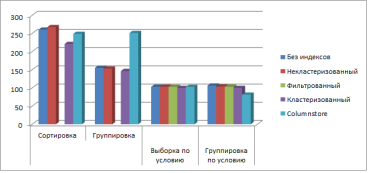
Рис. 3а. Время выполнения различных запросов к таблицам данных — 10000 записей
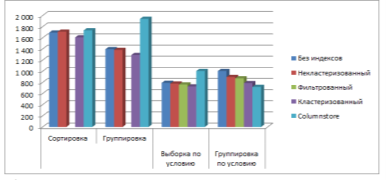
Рис. 3б. Время выполнения различных запросов к таблицам данных — 100000 записей
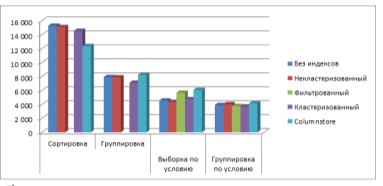
Рис. 3в. Время выполнения различных запросов к таблицам данных — 1000000
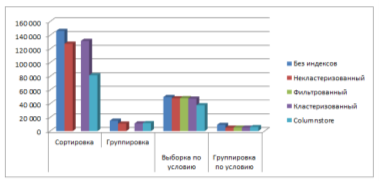
Рис. 3г. Время выполнения различных запросов к таблицам данных — 10000000 записей
Опираясь на полученные данные, можно заметить некоторые весьма примечательные детали. Главным образом — запросы на группировку для средних и больших объемов выполняются в разы эффективнее для всей таблицы относительно запросов на простую выборку. Кластеризованные и некластеризованные индексы оказались менее эффективны для маленьких наборов данных, для группировки данных индексы потеряли эффективность, которая была на предыдущих испытаниях.
Однако, в целом индексы остаются предпочтительными при использовании на больших объемах данных. Особенно для объемов от 10000000 записей эффективен columnstore — на всех запросах среднее время выполнения примерно на 40 % быстрее, чем без использования индексов, тогда как обычные индексы ускоряют процесс всего до 25–30 %. Заметим также, что максимальной эффективности индексы достигают, когда запросы предполагают выборку по условию.
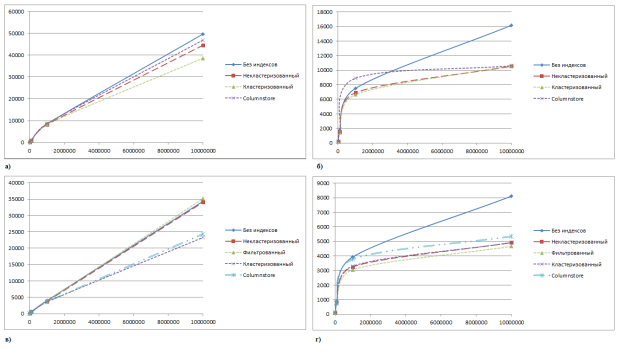
Рис. 4.График роста времени выполнения запросов при росте объема данных а) Запрос с сортировкой; б) Запросы с группировкой; в) Выборка по условию; г) Группировка по условию
На Рис. 4 можно проследить, как быстро растет время выполнения запросов при росте объема данных. Отметим, линейную зависимость запросов на выборку и логарифмическую — при запросах на группировку. Практически во всех случаях использование кластеризованного индекса гарантирует рост эффективности. Впрочем, так как первичный ключ является как раз кластеризованным индексом, то это — довольно частое явление. Если группировка данных будет производиться не по первичному ключу, то уместно использовать некластеризованные индексы по полям группировки, особенно, учитывая низкие временные затраты на их создание и поддержание.
Литература:
- Дунаев, В. В. Базы данных. Язык SQL для студента / В. В. Дунаев. — М.: БХВ-Петербург, 2017. — 288 c.
- Аллен, Г. Тейлор SQL для чайников / Аллен Г. Тейлор. — М.: Диалектика, Вильямс, 2015. — 416 c.
- Владимир, Михайлович Илюшечкин Основы использования и проектирования баз данных / Владимир Михайлович Илюшечкин. — М.: Юрайт, 2015. — 516 c.
- Карвин, Билл Программирование баз данных SQL. Типичные ошибки и их устранение / Билл Карвин. — М.: Рид Групп, 2018. — 336 c.

