В статье рассматриваются теоретические основы организации поиска в информационной системе.
Ключевые слова: поиск, поисковый индекс, релевантность, ранжирование.
По мере накопления документов в информационных системах неминуемо возникает необходимость в организации эффективного механизма поиска информации в системе. Современная система должна отвечать таким критерием поиска, как быстрая скорость поиска и высокая степень соответствия найденных документов поисковому запросу. Для достижения этих целей эффективно использовать полнотекстовый поиск информации, выполняющий поиск документов по их содержимому.
В общем виде применяется следующая стратегия информационного поиска:
1. Формулировка запроса.
2. Морфологические преобразования информативных слов запроса.
3. Поиск релевантных документов.
4. Определение степени релевантности документов.
5. Ранжирование документов.
6. Предоставление результата поиска.
Система поиска осуществляет полнотекстовый поиск документов в коллекции документов на основе информационно-поискового языка и соответствующих правил поиска. На основе текстовых данных выполняется построение инвертированного индекса, который представляет из себя структуру данных, состоящую из морфологического словаря, где каждому слову словаря соотносится список номеров документов, в которых это слово встречается (рис.1).
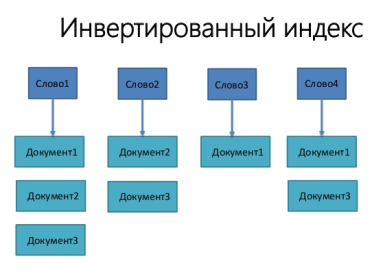
Рис. 1. Инвертированный индекс
Индексатор получает текст на вход, выполняет морфологические преобразования текста (приведение к лексемам или корневой основе слова, символьные фильтры, исключение стоп-слов) и сохраняет в поисковый индекс, сопоставляя каждому слову набор документов. Этот процесс называется индексированием. Также в индексе сохраняется метаинформация (позиция слова в документе, частота встречаемости слова в документе и во всей коллекции документов).
При получении поискового запроса система поиска выполняет предварительную обработку слов поискового запроса, которая включает: исключение стоп-слов и знаков пунктуации, приведение текста к нижнему регистру, лемматизация (приведение слов к начальной форме слова), исправление ошибок в словах поискового запроса, расшифровка аббревиатур и сокращений.
После прохождения разбора поисковой фразы формируется результат пересечения списков инвертированного индекса в виде набора документов, содержащих слова запроса. Сортировка документов выполняется на основе факторов ранжирования, выставляя каждому документу весовой коэффициент. Данный коэффициент является суммой величин факторов ранжирования, вычисленного для определенного документа. Документ с максимальным весовым коэффициентом будет на первом месте результатов поиска.
Факторы ранжирования являются характеристиками алгоритма поисковой системы, выполняющие анализ документов информационного массива на соответствие заданным требованиям с целью определения степени релевантности документов и представляют собой произвольные арифметические выражения, которые могут использовать константы, атрибуты документов, встроенные функции и логические операторы.
Основными факторами ранжирования системы поиска являются факторы встречаемости слов запроса в документе и во всей коллекции документов (насколько это частое либо редкое слово), а также порядка (близости) следования слов запроса в тексте документа.
Для оценки важности слова в контексте документа, являющегося частью коллекции документов, часто применяется статистическая мера TF-IDF, где вес некоторого слова пропорционален частоте употребления этого слова в документе и обратно пропорционален частоте употребления слова во всех документах коллекции. Рассмотрим далее одну из основных функций ранжирования, которая учитывает частоту встречаемости слов поискового запроса в коллекции документов.
TF (term frequency — частота слова) — отношение числа вхождений некоторого слова к общему числу слов документа. Таким образом, оценивается важность слова
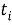
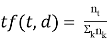
где
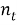
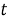
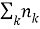
Чем больше значение TF, тем документ является более релевантным по отношению к слову
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. IDF уменьшает вес широкоупотребительных слов. Для каждого уникального слова в пределах конкретной коллекции документов существует только одно значение IDF. Чем более редкое слово, тем более релевантен документ, в котором оно найдено.
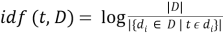
где
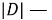
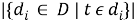
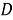
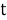
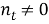
Выбор основания логарифма в формуле не имеет значения, поскольку изменение основания приводит к изменению веса каждого слова на постоянный множитель, что не влияет на соотношение весов.
Для того, чтобы учесть и частоту слова, и обратную частоту документа, необходимо перемножить эти 2 величины. Итого, для каждого слова и документа в коллекции документов можно рассчитать меру TF-IDF, которая является произведением двух сомножителей:
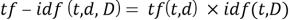
Наибольший вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
BM25 — поисковая функция на множестве документов, которые она оценивает на основе встречаемости слов запроса в каждом документе, без учета взаимоотношений между ними (например, близости). В формулу входят TF, IDF каждого из слов, свободные коэффициенты, длина документа и средняя длина документа в корпусе.
Пусть дан запрос
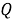
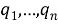
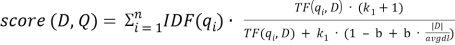
где
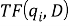
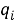
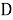
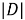
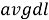
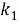
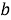
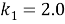
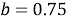
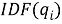
BM25 и его различные более поздние модификации представляют собой современные TF-IDF-подобные функции ранжирования, широко используемые на практике в поисковых системах. В веб-поиске эти функции ранжирования часто входят как компоненты более сложной, часто машинно-обученной, функции ранжирования.
Литература:
1. Кристофер Д. Маннинг, Прабхакар Рагхаван, Хайнрих Шютце Введение в информационный поиск. — Москва, 2011. — 483 с.
2. TF-IDF — Текст: электронный // Свободная энциклопедия Википедия: [сайт]. — URL: https://ru.wikipedia.org/wiki/TF-IDF (дата обращения: 08.05.2021).

