Сегодня большая часть информации хранится в реляционных базах данных. Это связанно с тем, что такая модель данных проста, понятна и удобна для физической реализации на ЭВМ, а также имеет оптимизаторы выполнения транзакций и запросов к базе данных, обеспечивающих их «дробление» на более мелкие задания и параллельную реализацию этих работ на многопроцессорных или многомашинных комплексах. Благодаря этим факторам пользователи до сих пор выбирают и используют именно реляционные базы данных.
Но такая модель хранения данных отчасти устарела и подходит не для всех проектов. С тех пор, как придумали строчные реляционные базы данных, технические характеристики устройств резко выросли: мощности процессоров увеличились в 5000–10000 раз, время передачи данных с диска в память уменьшилось в 100 раз, время поиска данных на диске — в 10 раз. Различие в приросте мощностей обрабатывающих ресурсов значительно повлияло на рабочие нагрузки СУБД. Наблюдался также дисбаланс между ростом емкости диска и скоростью передачи данных:
- пропускная способность передачи информации по отношению к общему объему доступной информации уменьшилась на два порядка;
- отношение скорости доступа к последовательно расположенным на диске данным и при случайной выборке выросло на порядок. Стало понятно, что в СУБД нужно устранить случайный доступ к данным, а также уменьшить нагрузку на канал их передачи.
Часть этих проблем была решена с приходом колоночных баз данных. Но основным минусом и строчных и колоночных СУБД является поддержка реляционной модели, которая предполагает хранение данных в виде таблиц и наличие схемы базы данных. Из этого вытекают трудно решаемые задачи:
- Потеря соответствия.
- Масштабируемость.
- Реляционные базы данных не справляются с обработкой большого объёма неструктурированных данных (текстов).
Для решения этих проблем создаются новые варианты хранения и обработки данных, получившие название «базы данных NoSQL». Исходя из потребностей системы, выбирают одну из четырех типов хранилищ: «ключ-значение» (key-value store), документно-ориентированные (document store), хранилища семейств колонок (column database), графовые базы данных (graph database) [1]. В данной статье рассматривается только тип «ключ-значение». Это простейшее хранилище, которое использует ключ для доступа к значению. Именно такой тип используется для создания специализированных файловых систем, а также систем, ориентированных на масштабируемость.
MapReduce.
Базы данных, построенные на парадигме распределенных хранилищ «ключ-значение», обеспечивают доступ к неструктурированным данным посредством прямого чтения записей или выполнения заданий MapReduce [2].
MapReduce – это алгоритм, доступа к неструктурированным данным. Первым шагом этого алгоритма является выполнение функции Map ко всем элементам исходной коллекции. Результатом этого шага будет либо пустота, либо экземпляр «ключ-значение»:
![C:\Users\zabil_000\Desktop\статья\image[4].png](https://articles-static-cdn.moluch.org/articles/j/31425/images/31425.001.png)
Рис. 1. Первый шаг алгоритма MapReduce
На втором шаге происходит сортировка всех экземпляров и создание новых, где все значения сгруппированы по ключу:
![C:\Users\zabil_000\Desktop\статья\image[9].png](https://articles-static-cdn.moluch.org/articles/j/31425/images/31425.002.png)
Рис. 2. Второй шаг алгоритма MapReduce
Заключительным шагом выполнится функция Reduce, которая вернет новый экземпляр объекта, который будет включен в результирующую коллекцию:
![C:\Users\zabil_000\Desktop\статья\image[14].png](https://articles-static-cdn.moluch.org/articles/j/31425/images/31425.003.png)
Рис. 3. Третий шаг алгоритма MapReduce
Метод MRIJonRCFile.
Существуют различные методы доступа к хранилищу данных по технологии MapReduce. В [3] рассматриваются способы реализации соединения таблиц измерений и фактов, которые связаны по схеме «звезда». Они позволяют избежать перемещений записей таблицы фактов. Запрос для схемы с двумя измерениями (D1 и D2) и одной таблицей фактов (F) можно представить так:
SELECT D1.d11, D2.d21, F.m1
FROM D1 JOIN F ON (D1.d10 = F.fk1) JOIN D2 ON (D2.d20 = F.fk2)
WHERECD1 ANDCF1,
где CD1 и CF1 — некоторые дополнительные условия, накладываемые на измерения и факты.
Рассмотрим вариант соединения по методу MRIJonRCFile.
Таблица (измерений или фактов) разбивается на несколько горизонтальных разделов (rowgroup). В одном блоке HDFS таблицы может храниться несколько разделов. Внутри каждого раздела данные хранятся по столбцам (в сжатом виде). Данные можно читать по отдельным столбцам (или группам столбцов) в блоке. При этом считанный столбец раздела разжимается только в том случае, если он действительно используется. Блоки таблицы распределены по узлам произвольным образом.
Первый шаг выполнения запроса.
Map1:
- На узле читаются записи таблицы измерения; выделяются группы столбцов, удовлетворяющие условию поиска, в файловую систему MapReduce помещаются записи:
dkvi = <key,value>, </key,value>
где key — первичный ключ таблицы измерения, value — список значений других колонок данного измерения, которые необходимо поместить в результирующую таблицу.
Далее следует повторить пункт 1 для всех измерений, которые участвуют в запросе и блоки которых хранятся на данном узле.
Reduce1: — отсутствует.
Второй шаг выполнения запроса.
Map2:
- На узле читаются полученные записи измерения dkvi и для них строится хеш-индекс в ОП по ключу key.
Пункт 1 следует повторить для всех поступивших измерений.
- Читается столбец первого внешнего ключа таблицы фактов, участвующего в запросе, и проверяется наличие значений этого ключа в соответствующем хеш-индексе; при успешном сравнении сохраняются записи в ОП узла (т. е. локально):
fkv1= <позиция, value >,
где «позиция» — это номер строки таблицы фактов (нумерация сквозная по всем строкам таблицы фактов); value — список значений из соответствующей записи dkv1.
- Шаг 3 выполняется по числу измерений, участвующих в запросе (минус 1, так как для первого измерения выполнен шаг 2), т. е. i=2,…,n. По позициям промежуточной таблицы fkvi-1 читаются кортежи столбца i-го внешнего ключа таблицы фактов и проверяется наличие значений этого ключа в соответствующем хеш-индексе; при успешном сравнении сохраняются записи в ОП узла (т. е. локально):
fkvi= <позиция, value >,
где «позиция» — номер строки таблицы фактов; value= value![]() valuei, value справа от знака присваивания — это значение из записи предыдущей промежуточной таблицы fkvi-1, valuei — список значений из соответствующей записи dkvi.
valuei, value справа от знака присваивания — это значение из записи предыдущей промежуточной таблицы fkvi-1, valuei — список значений из соответствующей записи dkvi.
Предыдущая промежуточная таблица fkvi-1 удаляется. Пример, иллюстрирующий выполнение шага:
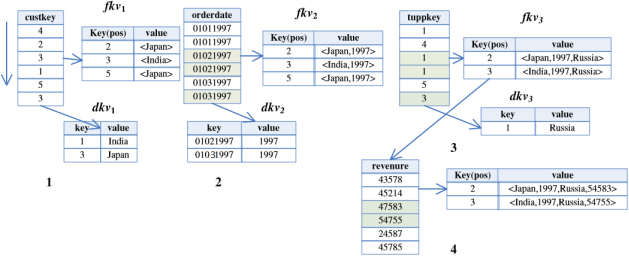
Рис. 4. Пример последовательного соединения таблиц измерений и таблицы фактов
- По позициям последней промежуточной таблицы fkvnчитаются значения столбцов фактов (они хранятся в том же блоке, что столбцы внешних ключей). На диске сохраняются записи результирующей таблицы:
<позиция, (value,vm1,…,vmk)>,
где value — значение в записи промежуточной таблицы fkvn(список значений атрибутов из таблиц измерений); vmi — значение i-го факта.
Reduce2: нет.
Заключение.
Таким образом мы получили общую картину о модели распределённых вычислений MapReduce и разобрались в методе доступа к хранилищу данных MRIJonRCFile. Реализацию данного метода рассмотрим в следующей статье.
Литература:
- NoSQL: [Электронный ресурс]. [http://ru.wikipedia.org/wiki/NoSQL] Проверено 30.05.2016.
- Редмон Э., Уилсон Д. Р. Семь баз данных за семь недель. Введение в современные базы данных и идеологию NoSQL. — М.: ДМК Пресс, 2013. — 384 с.
- Zhou G., Zhu Y., Wang, G. Cache Conscious Star-Join in MapReduce Environments. Cloud-I '13 Proceedings of the аnd International Workshop on Cloud Intelligence, August 26 2013.

