Введение
Сегодня область информационных технологий является одной из самых динамично развивающихся. В среднем, глобальные изменения в этой сфере происходят через пять лет. Поэтому возникает вопрос о самообразовании взрослых, не зависимо от их возраста.
Чаще всего среднестатистический человек сталкивается с проблемой сбора и обработки информации по определенной теме своих профессиональных интересов. Как правило, эти данные надо не только собрать, но и сделать простейший анализ по заданным категориям. Проще всего такие данные собираются в таблицы, а обработка предполагает выполнение логических и арифметических действий с полученными данными: сортировка, группировка, пересчет совпадения и так далее.
Математический анализ поставленной задачи приводит человека к модели простейшей реляционной базы данных [2, c.32]. Она предполагает, что данные можно представить в виде таблиц. Эти таблицы можно разделить по типу представленных данных на таблицы объектов и таблицы связей. Таблицы объектов дают полное описание элемента объема информации (объекта), который самодостаточен и не зависит от описания других элементов. Таблицы связи определяют отношения между таблицами объектов. В них вносится объединяющая разные объекты информация.
Конечно, полная реализация такой модели предполагает проверку выполнения всех требований к реляционной базе: отсутствие аномалий, определение типа нормальной формы, определение типов отношений между таблицами. Для реализации такой базы данных было бы уместнее использовать приложение, являющееся системой управления базой данных, такой как, например, MS Access. Однако не каждый сможет сразу самостоятельно разобраться во всех правилах и тонкостях этой программы. Поэтому, для начала надо попробовать разобраться с работой с простейшими базами данных в MS Excel. Табличный редактор Excel обладает мощной системой поддержки работы и с логическим управлением таблиц с данными, и с математическим аппаратом. При этом, он не требует у пользователя глубоких знаний о теории реляционных баз данных и позволяет получить очень большое количество сведений о внесенной базе в виде таблиц в книгу.
Списки в Excel
Таблицы, являющиеся частью базы данных, должны быть представлены в табличном редакторе MS Excel в виде списков [1, c. 90].
Список — это прямоугольный непрерывный диапазон ячеек, определяемый адресом левой верхней и адресом правой нижней ячейки, удовлетворяющий следующим правилам:
1. Первая строка диапазона содержит заголовки столбцов.
2. В столбцах информация однородная, то есть одного типа: числа, даты, символы.
3. По строке идет описание равно одного события (покупка единицы товара, опрос одного человека, описание одного элемента).
4. В диапазоне отсутствуют пустые ячейки.
Это описание классического списка. В принципе его можно «транспонировать», то есть поменять местами строки и столбцы.
Рассмотрим работу с простейшей базой на примере файла MS Excel, в котором внесены данные о покупке строительных товаров в некой фирме (рис. 1).
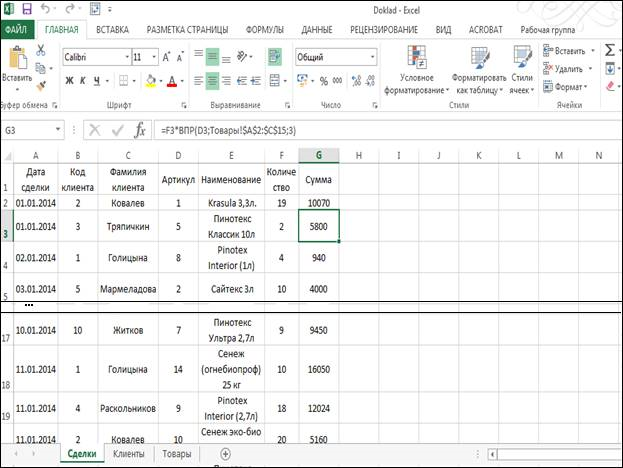
Рис. 1. Список на листе Excel
В этом файле существует три листа, названные Сделки, Клиенты и Товары. На листе Клиенты занесена информация о покупателя. Она оформлена в виде списка с заголовками: Код клиента, Фамилия, Отчество и Адрес. Такая таблица полностью описывает объект Клиент, и поэтому является таблицей объектов (рис. 2).
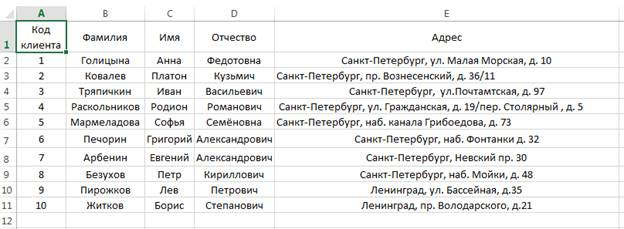
Рис. 2. Таблица Клиент
На листе Товары представлена таблица с полным описанием продаваемого товара. Эта таблица также является, во-первых, списком, а во-вторых, таблицей объекта. Очевидно отсутствие связи между таблицей Клиенты и таблицей Товары. При этом, описание каждого элемента в таблицах дано полное. Более того, для идентификации конкретной записи введены такие поля как Код клиента (в таблице Клиент) и Артикул (в таблице Товары). Благодаря им одна запись всегда может быть отличена от другой. Например, могут быть среди клиентов полные тезки, или, как видно из примера, может продаваться один и тот же по характеристикам товар, но в разной упаковке. Однако эти записи для табличного редактора отличаются, и поле отличия можно считать ключевым полем.
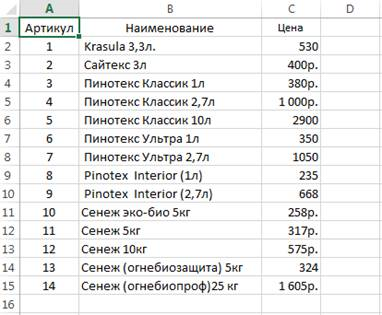
Рис. 3. Таблица Товары
Из теории баз данных известно, что ключевое поле в реляционной таблице может быть только простым, то есть может состоять только из одного поля. Это требование для таблиц Клиенты и Товары выполнено.
На рис. 1 представлена таблица — Сделки. В ней, помимо независимой информации о количестве товара, имеет зависимая информация, связывающая между собой таблицы Клиенты и Товары. К этим поля относятся: Фамилия клиента, Наименование и Сумма. Для внесения данных в поле Фамилия и для расчета суммы сделки в поле Сумма использовалась функция обработки массивов и ссылок ВПР (рис. 4). По значению в ячейке В2 восстанавливается информация из диапазона с листа Клиенты, то есть из таблицы объекта, из второго столбца. Как видно из рис. 2, во втором столбце стоит фамилия клиент
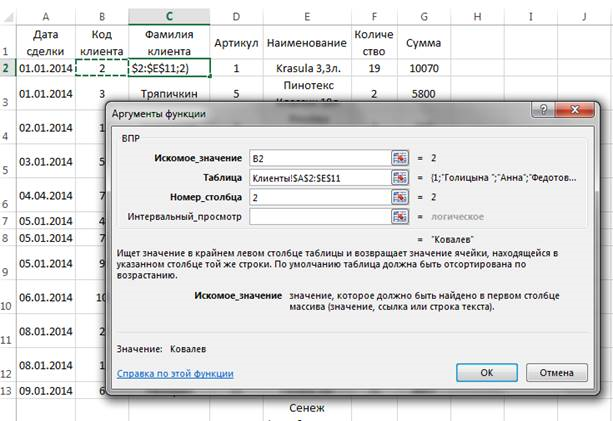
Рис. 4. Использование функции ВПР для заполнения столбца Фамилия клиента
Для поля Сумма из таблицы Товары восстанавливается информация из третьего столбца таблицы Товары. В этот столбце с наименованием Цена (рис. 3) введена стоимость единицы товара.
Итоговая сумма к выплате — это произведение количества товара (столбец Товар) на стоимость единицы товара. При этом стоимость единицы товара выбирается из таблицы Товары с помощью функции ВПР (рис. 5).
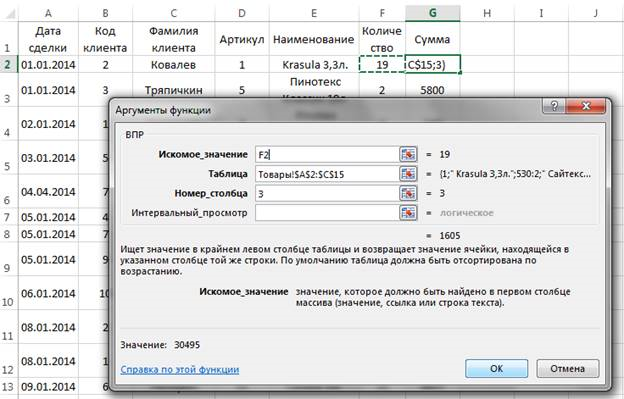
Рис. 5. Использование функции ВПР для заполнения столбца Сумма
Для восстановления данных в поле Наименование использовалась альтернативная функция обработки массивов и ссылок — ИНДЕКС (рис.6).
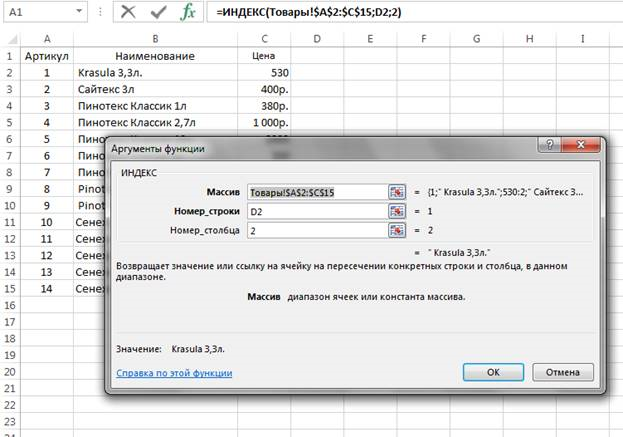
Рис. 6. Использование функции ИНДЕКС
Отличие этой функции от ВПР заключается в том, что в том, что в качестве первого параметра она получает диапазон, а далее она может динамически (через меняющееся значение в ячейках), или статически (через точное указание) находить данные, которые стоят на пересечении указанных строки и столбца. В нашем примере приведено смешанное определение: номер строки определяется по значению артикула D2, а номер столбца задан неизменным — второй(2).
Возможности функции ИНДЕКС более широкие, но требуют более внимательного отношения к задаче отбора данных. Поэтому, чаще пользователи обращаются к функции ВПР, у которой меньше возможностей, но которая более проста в использовании.
Сортировка
Основное назначение Excel, как уже отмечалось, — обработка данных. Наряду с простыми вычислениями здесь можно:
- отсортировать данные (Сортировка),
- выделить необходимое подмножество данных из совокупности имеющихся (Фильтр),
- подвести итоги (Итоги).
Все эти действия, применимые к данным в списках в программе MS Excel 2013 собраны в меню Данные [1, c.95]. На рис. 7. приведена лента, соответствующая вкладке Данные.

Рис. 7. Вкладка Данные
Для того, чтобы применить любое из вышеперечисленных действия необходимо расположить указатель курсора на любой из ячеек списка и выбрать необходимое средство.
При выполнении самых различных задач возникает необходимость упорядочить данные. Так, например, числовые данные могут быть отсортированы в порядке возрастания или убывания, а текстовые данные можно расположить в алфавитном порядке. Для этого используется средство Сортировка. Как правило, сортировка производится над данными, расположенными в списке. Результатом сортировки будет новая таблица, содержащая ту же информация, но переупорядоченная. Порядок данных в новой таблице будет зависеть от условий сортировки.
Сортировка представлена в двух вариантах реализации: одноключевая и многоключевая.
Одноключевая сортировка предполагает работу только в одном столбце (или строке, если список расположен горизонтально). Чтобы её применить надо установить указатель курсора в сортируемый заголовок и выбрать сортировка от А до Я (или от Я до А), нажав соответствующую кнопку.
Если требуется провести многоключевую (многоуровневую) сортировку, то необходимо обратиться к кнопке Сортировка. В диалоговом окне необходимо задать параметры уровней сортировки (рис. 8)
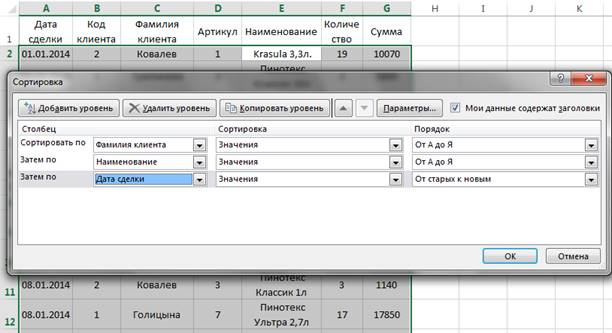
Рис. 8. Многоуровневая сортировка
После применения такой сортировки, в нашем примере сначала будут отсортированы клиенты по-фамильно, там, где данные клиентов совпали, отсортированы товары по наименованию, и где совпали оба поля: Фамилия и Наименование, будут отсортированы даты от начала года к концу.
Промежуточные итоги
Средство Промежуточный Итог меню Данные помогает организовать записи списка в группы, выводя под каждой из них итоговую информацию, другими словами позволяет вывести на экран данные, сгруппированные по тем или иным критериям и автоматически вычислять промежуточные и общие итоги в таблице [1, c. 107].
Таким образом, это действие связано с математической обработкой данных и их группировкой. При использовании этого средства данные в списке (таблице) необходимо предварительно отсортировать по нужному столбцу.
При каждом изменении в отсортированном поле, стоящем на первом уровне сортировки, добавляются итоги по выбранным полям записи. Причем функция операции — это не только суммирование данных, но и вычисление количества (то есть сколько раз встречается заданное поле среди записей), среднее значение, максимум, минимум, произведение, отклонение и дисперсия (рис. 9).
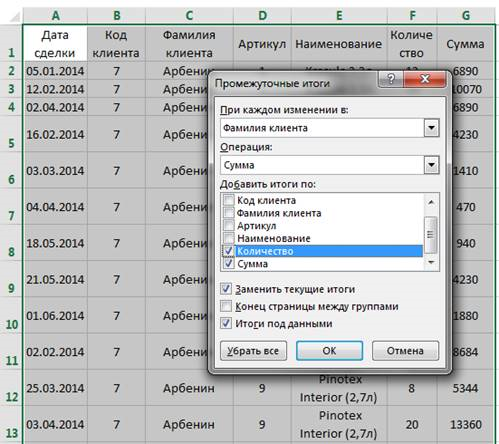
Рис. 9. Настройка диалогового окна Промежуточные итоги
В результате применения не только вычисляются указанные значения по поля, но и происходит группировка данных на три уровня: общий (по таблице), промежуточные (по каждому переходу) и полный.
На рис. 10 представлен промежуточный вариант группировки. Основным недостатком этого действия является то, что после расстановки промежуточных итогов список перестает быть списком, так как в строках с промежуточными итогами появляются пустые ячейки. На рис. 10 это ячейки А37, В37, D37 и так далее. Поэтому, для вычисления промежуточных итогов делается копия всего списка, или части списка, и уже на ней проводятся вычисления.
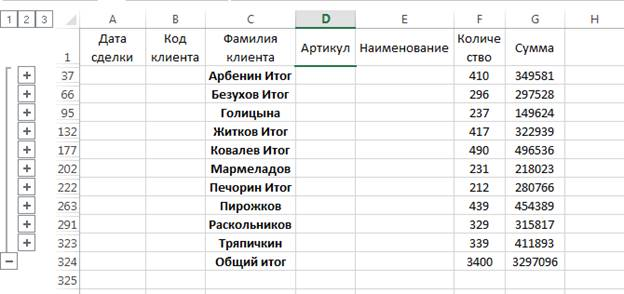
Рис.10. Результат группировки
Щелкая поочередно на знаки структуры  , можно создать итоговый отчет, скрыв подробности и отобразив только необходимые итоги.
, можно создать итоговый отчет, скрыв подробности и отобразив только необходимые итоги.
Если итоги у Вас не получились, для их отмены есть кнопка Убрать все в диалоговом меню Промежуточные итоги (рис. 9).
Фильтрация
Фильтрация — это отбор данных по заданному условию. Те данные, что не удовлетворяют условию фильтров, из списка не удаляются, а скрываются [1, c. 99]. Условия фильтрации могут представлять собой как требования полного совпадения, например, фамилии клиента, так и попадания в какой-то промежуток, например, отбор сделок за первый квартал.
Вызов функции фильтра происходит при нажатии кнопки Фильтр.
На рис. 11 приведен пример фильтрации данных по полю Фамилия клиента. Отбор в данном случае идет по совпадению двух фамилий: Арбенин и Печорин.
Все записи с другими фамилиями будут скрыты. О том, что применен фильтр, нам говорят три указателя: наличие знака воронки у заголовков, по которым идет фильтрация, выделенные синим маркером номера строк и запись в строке состояния о том, сколько записей соответствует заданному фильтру.
После применения первого фильтра, также как и в сортировке, можно продолжить фильтрацию и установить дополнительные правила отбора. Например, добавить отбор по наименованию.
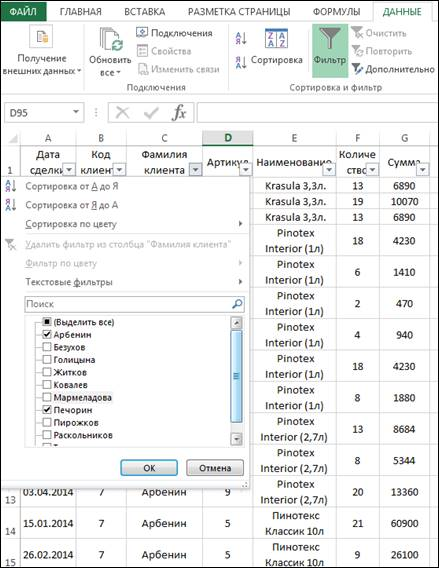
Рис. 11. Настройка Фильтра
Надо помнить, что существует жесткая система градации при выполнении фильтрации, и чтобы достигнуть правильного результата, надо заранее планировать последовательность фильтров.
Заключение
В заключении хотелось бы обратить внимание на то, что при самостоятельном изучении работы с пакетами прикладных программ очень важно заранее планировать направление исследования и начинать осваивать новое программное средство с простейших заданий.
Литература:
1. Бурнаева Э.Г, Белкова А. Л., Леора С. Н.. Информатика. Работа в MS Excel 2007: Учебное пособие. — СПб: СПбГУ, 2012, 135 стр.
2. Кириллов В.В, Громов Г. Ю. Введение в реляционные базы данных. — СПб: БХВ-Петербург, 2009, 464 стр.

