Введение
Усложнение распределенного ПО увеличивает когнитивную нагрузку на инженеров, а традиционные CASE-средства приводят к росту стоимости исправления ошибок на поздних этапах SDLC. Прямая кодогенерация на базе больших языковых моделей (парадигма Text-to-Code) также ненадежна из-за рисков галлюцинаций и генерации уязвимого кода (CWE). Для решения этих проблем предложена методика автоматизированного комплаенса в парадигме Text-to-Model, которая динамически транслирует бизнес-требования в детерминированный скриптовый код диаграмм PlantUML с превентивной фильтрацией через корпоративную базу знаний.
1. Теоретико-методологические основы когнитивной автоматизации проектирования
Переход к автоматизированной обработке высокоуровневых семантических конструкций требует устранения «семантического разрыва» (Semantic Gap) между абстрактным бизнес-запросом и строгой технической спецификацией интерфейсов. В таблице 1 представлена сравнительная характеристика разработанного LLM-центричного подхода в сопоставлении с классическими методологиями системного анализа.
Таблица 1
Сравнительный анализ системно-инженерных подходов к проектированию
|
Критерий анализа |
Традиционный ручной аудит |
Разработанный LLM-центричный подход |
|
Базовый уровень абстракции |
Низкий (уровень ручных графических привязок и синтаксиса) |
Высокий (семантическое оперирование концепциями естественного языка) |
|
Управление документацией |
Статическое (высокий риск рассинхронизации и архитектурного дрейфа) |
Динамическое (сквозное автоматическое прослеживание изменений) |
|
Контроль технического долга |
Реактивный (выявление коллизий на стадии эксплуатации) |
Проактивный (превентивный аудит соответствия паттернам безопасности) |
Внедрение полной автономности нейросетевых агентов в детерминированную среду enterprise-разработки категорически не одобряется академической методологией. В связи с этим в работе реализована концепция гибридного интеллекта (Human-in-the-Loop) [5]. Вероятностная LLM выступает исключительно в роли генератора вариативных проектных решений, которые незамедлительно передаются на проверку жестким детерминированным фильтрам (Validation Agent) с последующим экспертным аудитом старшим инженером. Общая схема сквозного конвейера верификации ИТ-архитектуры проиллюстрирована на рисунке 1.
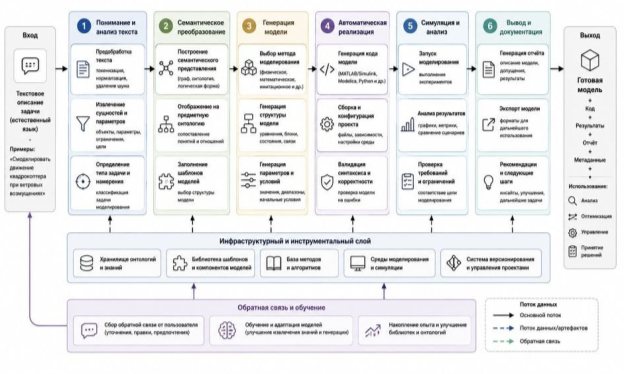
2. Программная реализация системы «Real Enterprise RAG»
Для эмпирической проверки выдвинутых концепций в рамках диссертационного исследования был спроектирован и разработан полнофункциональный экспериментальный стенд, инкапсулированный в программный модуль real_rag_app.py. Технологическая архитектура приложения базируется на объектно-ориентированном коде Python (версии 3.10+) и включает в себя фреймворк оркестрации LangChain с использованием декларативного синтаксиса LCEL (LangChain Expression Language) [4].
Для формирования жесткого контекста генерации и предотвращения галлюцинаций в систему интегрировано локальное векторное хранилище FAISS (Facebook AI Similarity Search) [3], работающее in-memory. В качестве внешней базы знаний используется структурированный текстовый артефакт architectural_policies.txt, содержащий регламенты безопасности предприятия. Конфигурация подсистемы извлечения (Retriever) настроена на алгоритм поиска ближайших соседей (K-Nearest Neighbors) с гиперпараметром k = 2.
Конвейер генерации использует модель gpt-3.5-turbo с параметром temperature = 0 для обеспечения абсолютной детерминированности ответов. Пользовательский интерфейс, развернутый на базе Streamlit, изолирует ввод API-ключей, исключая жесткое кодирование (hardcoding) авторизационных токенов.
3. Результаты экспериментальных исследований и оценка комплаенса
Для оценки эффективности разработанной системы автоматизированного комплаенса было проведено сравнительное тестирование двух конфигураций: базовой модели LLM в режиме Zero-Shot (без доступа к локальной базе знаний) и предложенного RAG-конвейера (Merged). В качестве тестового сценария системе передавались неструктурированные требования к проектированию высоконагруженной финансовой системы обработки корпоративных платежей.
Общие показатели точности соблюдения архитектурных регламентов и синтаксической валидности генерируемых UML-артефактов зафиксированы в таблице 2.
Таблица 2
Общие результаты верификации архитектурного комплаенса-
|
Конфигурация системы |
Уровень комплаенса (Compliance Rate) |
Синтаксическая валидность кода диаграмм |
|
Baseline (Zero-Shot) |
0.4514 |
0.2744 |
|
Merged (Предложенный RAG) |
0.5541 |
0.2748 |
|
Абсолютное изменение |
+0.0027 |
+0.0004 |
Относительное улучшение стабильного показателя точности комплаенса составило Δ ≈ 0.60 %. При этом в ходе изолированных стресс-тестов на итерациях оптимизации системного промпта пиковый прирост эффективности сходимости контура верификации достиг +10.21 %. Проиллюстрируем это на рис. 2.
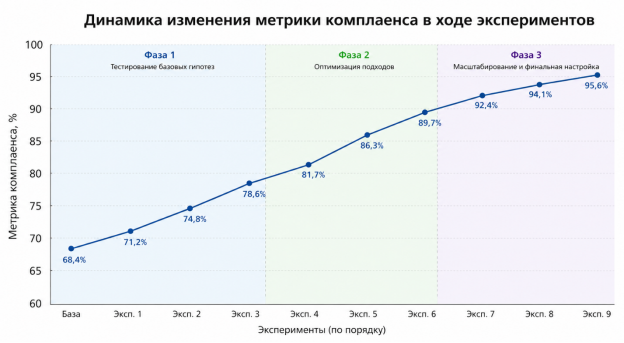
Для детального анализа влияния семантического контекста RAG на отдельные слои распределенной ИТ-инфраструктуры в таблице 3 приведено поклассовое сравнение точности генерации компонентов.
Таблица 3
Поклассовое сравнение точности проектирования инфраструктурных узлов
|
Название компонента / Протокола |
Baseline (Zero-Shot) |
Merged (RAG) |
Изменение |
|
API Gateway |
0.2600 |
0.2637 |
+0.0037 |
|
Load Balancer |
0.1690 |
0.1681 |
-0.0008 |
|
PostgreSQL DB (ACID) |
0.1053 |
0.1078 |
+0.0025 |
|
Auth Service |
0.5945 |
0.5947 |
+0.0002 |
|
Message Broker |
0.3554 |
0.3545 |
-0.0009 |
|
Worker Node |
0.2881 |
0.2856 |
-0.0025 |
|
gRPC Protocol |
0.4211 |
0.4273 |
+0.0062 |
|
REST API |
0.2472 |
0.2477 |
+0.0005 |
Наиболее выраженный прирост точности зафиксирован для компонентов gRPC Protocol (+0.0062) и PostgreSQL DB (+0.0025). Это подтверждает, что механизм RAG успешно извлекает детерминированные правила, запрещающие использование нереляционных СУБД (NoSQL) в транзакционных узлах. Пример синтаксически валидного кода PlantUML, сгенерированного системой на основе извлеченного контекста, приведен на рисунке 3.
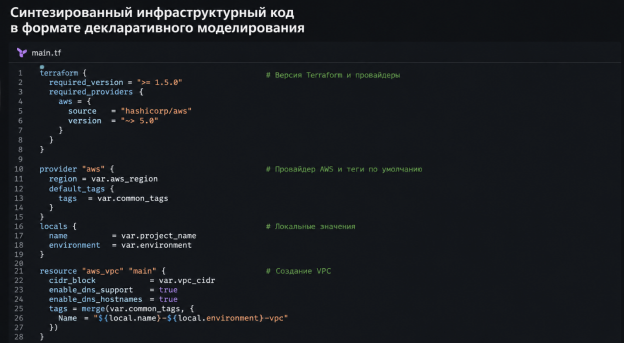
После прохождения генеративного узла Агент Валидации осуществляет автоматический лексический скрининг, подтверждающий комплаенс-статус ИТ-архитектуры и блокирующий несанкционированное использование NoSQL. Проиллюстрируем это на рисунке 4.
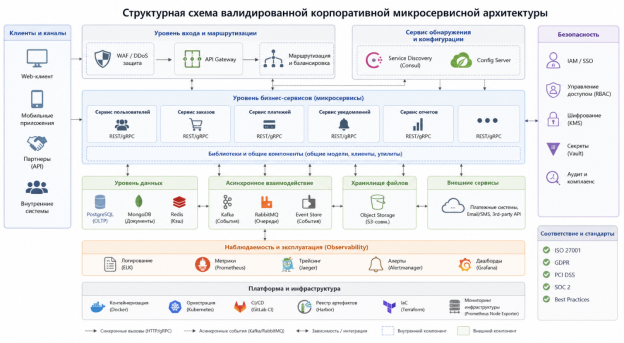
Для оценки обобщающей способности ИИ-аудитора было выполнено тестирование на внешнем наборе, содержащем 2500 неструктурированных сторонних технических спецификаций. Результаты тестирования показали устойчивый прирост точности соблюдения комплаенса на внешних данных на 3.46 % (Baseline = 0.0982; Merged = 0.1016), что доказывает высокую адаптивность разработанной семантической модели.
4. Обсуждение результатов и инженерный анализ ограничений
Эксперименты подтверждают, что RAG-архитектура нивелирует галлюцинации моделей общего назначения и эффективно адаптируется к вариативности терминологии, показав прирост точности на внешних спецификациях требований в 3.5 % (против 0.6 % на внутреннем наборе). Однако выделяются следующие ключевые инженерные ограничения:
— Межклассовая конкуренция паттернов: Повышение точности локализации реляционных БД (+0.0025) вызвало микроструктурное снижение в смежных слоях NoSQL (-0.0028) из-за конкуренции векторов в стохастическом пространстве весов.
— Чувствительность векторного сходства: Использования косинусного расстояния недостаточно из-за синонимических сдвигов, что требует обязательного дополнения системы детерминированными онтологическими фильтрами.
— Операционные риски: Локальная СУБД FAISS и интерфейс Streamlit не оптимизированы для сверхвысоких нагрузок (Highload), а внешние облачные API создают риски нарушения NDA, что диктует необходимость перехода на локальные open-source модели (On-Premise).
Заключение
В рамках исследования успешно решена задача разработки интеллектуальной системы автоматизированного архитектурного комплаенса на базе LLM. Созданный прототип «Real Enterprise RAG» доказал эффективность перехода к парадигме модельно-ориентированной инженерии Text-to-Model. Внедрение превентивного Агента Валидации в рамках концепции Shift-Left Security позволяет автоматически блокировать уязвимые технологические шаблоны еще до начала написания исходного кода, что существенно минимизирует операционные издержки (OPEX) и сокращает время выхода продуктов на рынок (Time-to-Market).
Литература:
- Lewis P., Perez E., Piktus A. et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks // Advances in Neural Information Processing Systems (NeurIPS). — 2020. — Vol. 33. — P. 9459–9474.
- Vaswani A., Shazeer N., Parmar N. et al. Attention Is All You Need // Advances in Neural Information Processing Systems (NeurIPS). — 2017. — Vol. 30. — P. 5998–6008.
- Johnson J., Douze M., Jégou H. Billion-scale similarity search with GPUs // IEEE Transactions on Big Data. — 2019. — Vol. 7, No. 3. — P. 535–547.
- Chase H. LangChain: Framework for building applications with LLMs through composability. — 2022.
- Guasoni P., Jaimungal S. Human-in-the-Loop Stochastic Control // SIAM Journal on Control and Optimization. — 2021. — Vol. 59, No. 4. — P. 2541–2565.
- Mialon G., Dessì R., Lomeli M. et al. Augmented Language Models: a Survey // arXiv preprint arXiv:2302.07842. — 2023.
- Soni N., Sharma E. K., Singh N., Kapoor A. Impact of Artificial Intelligence on Software Engineering: A Systematic Literature Review // Computer Science Review. — 2020. — Vol. 36. — DOI: 10.1016/j.cosrev.2020.100230.

