Введение
В последние годы системы обнаружения объектов получили широкое распространение в задачах транспортного мониторинга, интеллектуального управления инфраструктурой, анализа аэрофотоснимков и автоматизированного наблюдения. Существенное повышение качества таких систем стало возможным благодаря развитию методов глубокого обучения и появлению современных архитектур обнаружения объектов, таких как семейство YOLO (You Only Look Once).
Среди множества архитектур особого внимания заслуживает YOLOv8 — последняя версия одностадийного детектора, разработанная компанией Ultralytics [5].
Архитектура YOLOv8 включает три основных компонента: backbone для извлечения признаков, neck для агрегации признаков различных масштабов и detection head для прогнозирования координат ограничивающих рамок и классов объектов [5]. Общая архитектура модели показана на рисунке 1.
![Общая архитектура YOLOv8 [4, с. 3]](https://articles-static-cdn.moluch.org/articles/j/138099/images/138099-1.png)
Рис. 1. Общая архитектура YOLOv8 [4, с. 3]
Одной из ключевых особенностей YOLOv8 является отказ от anchor-based механизма в пользу anchor-free подхода [5], что упрощает настройку модели и повышает устойчивость обучения. В настоящем исследовании используется модификация YOLOv8n (nano), выбранная как компромисс между вычислительной сложностью и качеством обнаружения.
Несмотря на достигнутые результаты, эффективность моделей обнаружения во многом определяется объёмом и разнообразием обучающих данных. На практике формирование крупных размеченных наборов изображений связано со значительными затратами времени и ресурсов. Особенно остро данная проблема проявляется при работе с редкими категориями объектов и объектами малого размера.
В качестве базового набора данных в настоящем исследовании используется VisDrone2019-DET (Vision Meets Drone) [10]. Этот набор данных содержит 6471 изображение для обучения и 548 изображений для валидации, полученных с помощью беспилотных летательных аппаратов в различных условиях съёмки: разная высота полёта, различные погодные условия, высокая плотность объектов и частичные перекрытия. Набор включает 10 классов объектов: pedestrian, people, bicycle, car, van, truck, tricycle, awning-tricycle, bus, motor. Распределение объектов по классам является существенно несбалансированным: классы car и pedestrian представлены тысячами экземпляров, тогда как классы bicycle, tricycle и awning-tricycle — сотнями.
Одним из перспективных способов решения данной проблемы является использование генеративных моделей, способных формировать дополнительные обучающие примеры. Среди современных подходов особый интерес представляют диффузионные модели, обеспечивающие высокое качество синтезируемых изображений и возможность управления процессом генерации с помощью текстовых описаний.
Целью исследования является оценка влияния синтетических изображений, полученных с использованием диффузионной модели Stable Diffusion XL [6] [7], на качество обучающих данных и точность обнаружения объектов моделью YOLOv8 на наборе VisDrone [10], а также оценка обобщающей способности на внешнем наборе UAVDT [12].
1. Анализ исходного набора данных VisDrone и выбор целевого класса
Для выявления классов, наиболее сложных для обнаружения, была обучена базовая модель YOLOv8n на исходном наборе VisDrone. Результаты представлены в таблице 1.
Таблица 1
Результаты базовой модели YOLOv8n на наборе VisDrone
|
Класс (EN) |
Класс (RU) |
mAP50 |
|
car |
автомобиль |
0.839 |
|
bus |
автобус |
0.568 |
|
pedestrian |
пешеход |
0.541 |
|
motor |
мотоцикл |
0.537 |
|
van |
фургон |
0.489 |
|
people |
группа людей |
0.421 |
|
truck |
грузовик |
0.399 |
|
tricycle |
трицикл |
0.333 |
|
bicycle |
велосипед |
0.218 |
|
awning-tricycle |
трицикл с тентом |
0.169 |
|
Total mAP50 |
Общая mAP50 |
0.451 |
На рисунке 2 представлен типичный график обучения YOLOv8, демонстрирующий снижение функции потерь и рост метрики mAP с увеличением количества эпох.
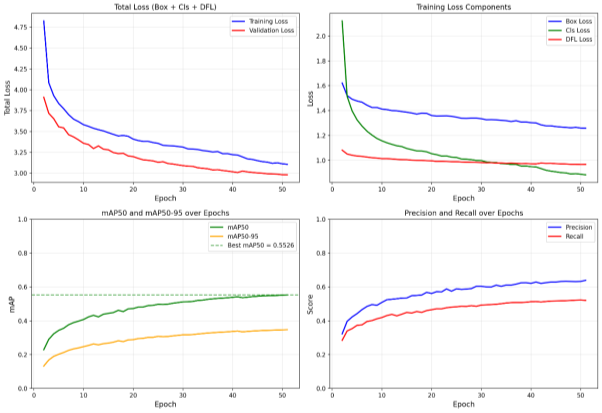
Рис. 2. Типичный график обучения YOLOv8
Как показано в таблице 1, наиболее сложными для обнаружения являются классы малых объектов: bicycle (0.218), tricycle (0.333) и awning-tricycle (0.169). Для улучшения качества обнаружения именно этих классов в настоящем исследовании используются синтетические изображения, сгенерированные диффузионной моделью. Для наглядности значения mAP50 по всем классам визуализированы на рисунке 3.
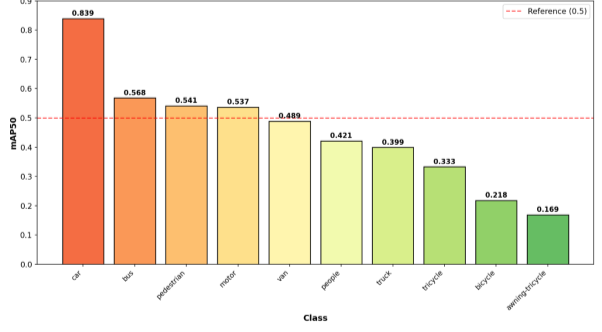
Рис. 3. Диаграмма значений mAP50 для различных классов VisDrone
2. Теоретические основы расширения обучающих данных
Расширение обучающих данных является важным этапом подготовки наборов изображений для обучения нейронных сетей. Традиционно для увеличения разнообразия данных используются методы геометрической и фотометрической аугментации [8]: вращение, масштабирование, отражение, изменение яркости и контрастности, случайное кадрирование, добавление шума. Однако подобные преобразования создают новые варианты уже существующих изображений и не позволяют формировать принципиально новые сцены.
Развитие генеративного искусственного интеллекта позволило использовать иной подход к подготовке данных. Вместо модификации существующих изображений генеративные модели создают новые примеры, сохраняющие статистические характеристики исходного набора данных.
Процесс расширения обучающего набора данных включает несколько последовательных этапов: от исходных реальных изображений до обучения модели на объединённых данных. Общая схема этого процесса представлена на рисунке 4.
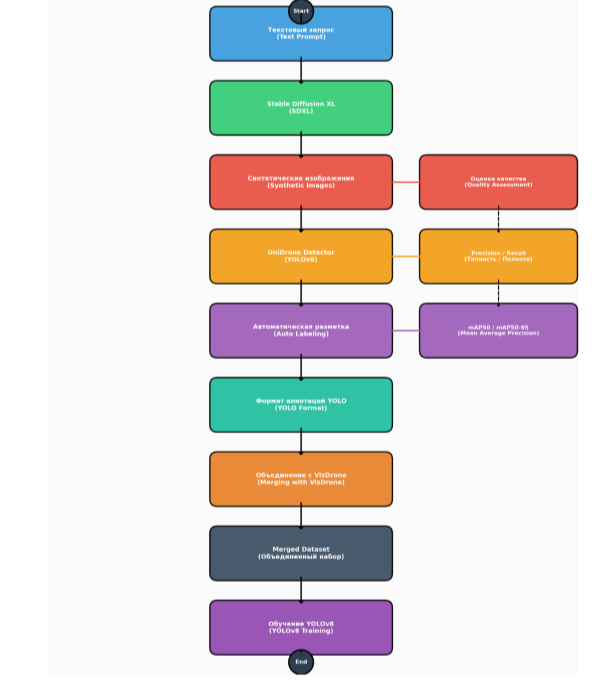
Рис. 4. Общая схема использования генеративных моделей для расширения обучающего набора данных
Схема включает следующие этапы:
- Исходные данные (реальные изображения VisDrone)
- Генеративная модель (Stable Diffusion XL)
- Синтетические изображения
- Автоматическая разметка (псевдоразметка)
- Объединённый обучающий набор
- Обучение модели YOLOv8
3. Методика исследования
В рамках исследования использовалась генеративная модель Stable Diffusion XL Base 1.0 , разработанная компанией Stability AI. Модель относится к классу латентных диффузионных моделей и обладает следующими преимуществами: высокое качество синтезируемых изображений, поддержка генерации сцен высокой детализации, возможность управления содержимым изображения с помощью текстового описания.
3.1 Процесс подготовки данных
Подготовка данных включала несколько этапов:
- Формирование текстовых запросов — для обеспечения разнообразия сцен использовалась система комбинирования нескольких категорий: описание объектов (cyclists riding bicycles), тип городской среды (busy downtown intersection, modern city avenue), положение камеры (top-down drone shot, bird's-eye drone view).
- Генерация синтетических изображений — было сгенерировано 500 изображений класса bicycle с использованием Stable Diffusion XL. Параметры генерации: размер 1344×768 пикселей, 50 шагов денойзинга, guidance scale от 4.5 до 9.5.
- Автоматическая разметка объектов — выполнялась с использованием предварительно обученной модели UniDrone на основе YOLOv8 с порогом уверенности 0.25 и размером входного изображения 1920 пикселей.
- Объединение синтетических и исходных данных — синтетические изображения добавлялись к обучающей выборке VisDrone. Отношение синтетических данных к исходным составило R = 500/6471 ≈ 0.0773 (7.73 %).
3.2 Обучение модели YOLOv8
Обучение выполнялось на графическом процессоре NVIDIA Tesla T4. Параметры обучения:
– Архитектура: YOLOv8n
– Размер изображения: 1280×1280
– Размер батча: 8
– Количество эпох: 50
– Early stopping: 10 эпох
– Количество классов: 10
Для оценки качества использовались метрики:
– Precision = TP / (TP + FP)
– Recall = TP / (TP + FN)
– mAP50 — средняя точность при IoU = 0.5
– mAP50–95 — усреднение для порогов IoU от 0.5 до 0.95
4. Результаты экспериментов
Для оценки эффективности предложенного подхода было проведено обучение двух моделей YOLOv8n:
- Baseline — обучение только на исходном наборе VisDrone (6471 изображение)
- Merged — обучение на расширенном наборе (6471 + 500 синтетических изображений)
4.1 Результаты на валидационном наборе VisDrone
Для оценки эффективности расширенного набора данных было проведено сравнение двух моделей: базовой (Baseline) и обученной на объединённых данных (Merged). Сравнение общих показателей качества представлено в таблице 2.
Таблица 2
Общие результаты на наборе VisDrone Validation
|
Модель |
mAP50 |
mAP50–95 |
|
Baseline |
0.4514 |
0.2744 |
|
Merged |
0.4541 |
0.2748 |
|
Разница |
+0.0027 |
+0.0004 |
Относительное изменение mAP50 составило:
Δ = (0.4541–0.4514) / 0.4514 × 100 % ≈ 0.60 %
На рисунке 5 показана разница между двумя весами до объединения обучающих данных и после объединения
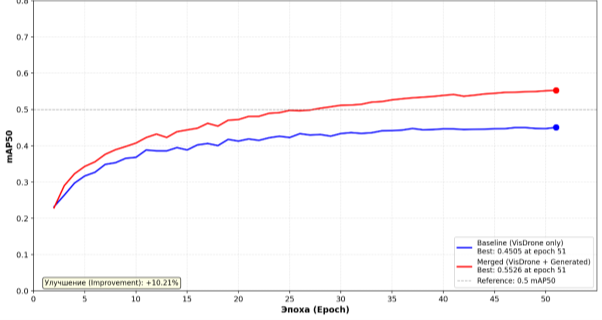
Рис. 5. изменение mAP50
Для более детального анализа влияния синтетических данных на отдельные классы объектов в таблице 3 приведено поклассовое сравнение моделей.
Таблица 3
Поклассовое сравнение моделей (mAP50–95)
|
Класс |
Baseline |
Merged |
Изменение |
|
pedestrian |
0.2600 |
0.2637 |
+0.0037 |
|
people |
0.1690 |
0.1681 |
-0.0008 |
|
bicycle |
0.1053 |
0.1078 |
+0.0025 |
|
car |
0.5945 |
0.5947 |
+0.0002 |
|
van |
0.3554 |
0.3545 |
-0.0009 |
|
truck |
0.2881 |
0.2856 |
-0.0025 |
|
tricycle |
0.1943 |
0.1919 |
-0.0023 |
|
awning-tricycle |
0.1092 |
0.1063 |
-0.0028 |
|
bus |
0.4211 |
0.4273 |
+0.0062 |
|
motor |
0.2472 |
0.2477 |
+0.0005 |
4.2 Результаты на специализированной выборке bicycle
Поскольку основное внимание в исследовании уделяется классу bicycle, в таблице 4 представлены результаты оценки моделей на специализированном подмножестве изображений, содержащих только объекты данного класса.
Таблица 4
Результаты на подмножестве изображений с bicycle
|
Модель |
mAP50 (bicycle) |
|
Baseline |
0.2306 |
|
Merged |
0.2311 |
|
Разница |
+0.0005 |
Относительное изменение: ≈ 0.22 %
С помощью модели Stable Diffusion XL было сгенерировано 500 синтетических изображений велосипедов. Примеры таких изображений приведены на рисунке 6.

Рис. 6. Примеры синтетических изображений
Для сравнения с синтетическими данными на рисунке 7 представлено реальное изображение из набора VisDrone, содержащее объекты класса bicycle.

Рис. 7. Реальное изображение VisDrone
Как показано на рисунках 6 и 7, существует заметное различие между синтетическими изображениями, созданными генеративной моделью, и реальными изображениями из набора VisDrone, что связано с различиями в текстурах, освещении и плотности объектов
После генерации синтетических изображений выполнялась их автоматическая разметка с использованием модели UniDrone. Пример результата автоматической разметки показан на рисунке 8.
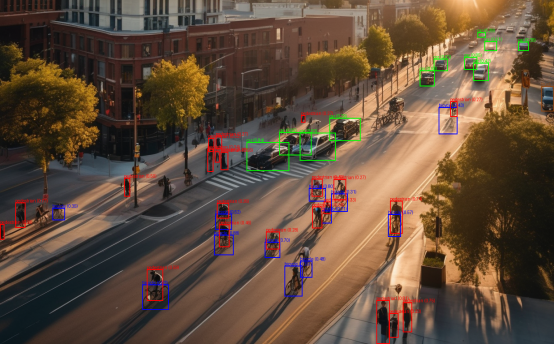
Рис. 8. Визуализация результатов автоматической разметки синтетического изображения
4.3 Результаты на внешнем наборе данных UAVDT
Для оценки обобщающей способности модели было выполнено тестирование на внешнем наборе UAVDT [12], содержащем 2500 аэрофотоснимков, отличающихся от VisDrone условиями съёмки, плотностью объектов и масштабами. Результаты сравнения базовой и расширенной моделей приведены в таблице 5.
Таблица 5
Результаты оценки на наборе UAVDT
|
Модель |
mAP50 |
|
Baseline |
0.0982 |
|
Merged |
0.1016 |
|
Изменение |
+0.0034 |
Относительное изменение: ≈ 3.46 %
Для более детального анализа влияния синтетических данных на отдельные классы объектов на внешнем наборе UAVDT в таблице 6 приведено поклассовое сравнение моделей.
Таблица 6
Поклассовое сравнение на UAVDT
|
Класс |
Baseline |
Merged |
Изменение |
|
pedestrian |
0.1466 |
0.1512 |
+0.0046 |
|
people |
0.0214 |
0.0235 |
+0.0021 |
|
bicycle |
0.1267 |
0.1303 |
+0.0036 |
Наиболее заметное улучшение наблюдается для класса bicycle — относительный прирост составил около 2.8 % .
5. Обсуждение результатов
Проведённое исследование показывает, что применение диффузионных моделей может рассматриваться как эффективный инструмент расширения обучающих выборок. В отличие от классических методов аугментации, генеративные модели способны формировать новые комбинации объектов и условий наблюдения.
Основные наблюдения:
- Незначительное улучшение на исходном наборе VisDrone — прирост mAP50 составил всего 0.6 %. Это объясняется тем, что добавлено лишь 500 синтетических изображений (7.7 % от исходного объёма), что недостаточно для кардинального изменения распределения данных.
- Более выраженное улучшение на внешнем наборе UAVDT — прирост 3.5 % свидетельствует о том, что синтетические изображения улучшают способность модели к обобщению. Это особенно важно, поскольку улучшение обобщающей способности обычно достигается значительно сложнее, чем улучшение результатов внутри обучающего распределения.
- Неоднородное влияние на разные классы — улучшение для класса bicycle (+0.0025) сопровождалось небольшим ухудшением для визуально схожих классов tricycle и awning-tricycle. Это может объясняться межклассовой конкуренцией.
- Ограничения подхода — качество автоматической разметки и наличие распределительного сдвига (domain shift) между синтетическими и реальными изображениями остаются ключевыми проблемами.
6. Ограничения и вызовы (Ограничения и вызовы)
Несмотря на полученные результаты, предложенный подход имеет ряд ограничений:
Во-первых , качество синтетических изображений напрямую зависит от точности текстовых запросов и выбранных параметров генерации (guidance scale, количество шагов денойзинга). Неоптимальный выбор этих параметров может приводить к появлению артефактов.
Во-вторых , автоматическая разметка синтетических изображений с использованием предварительно обученной модели вносит шум в обучающие данные. Ошибки локализации bounding boxes и неверная классификация объектов могут накапливаться.
В-третьих , существует проблема распределительного сдвига (domain shift) между синтетическими и реальными изображениями. Даже при высоком визуальном качестве, генеративные модели могут не полностью воспроизводить статистические характеристики реальных аэрофотоснимков.
В-четвёртых , предложенный метод демонстрирует неоднозначное влияние на разные классы объектов. Улучшение обнаружения одного класса может сопровождаться ухудшением для визуально схожих классов.
В-пятых , вычислительная стоимость генерации больших объёмов синтетических данных остаётся высокой. Для создания 500 изображений потребовалось несколько часов работы GPU Tesla T4.
Преодоление перечисленных ограничений является направлением дальнейших исследований, включая разработку более совершенных методов автоматической разметки, применение техник domain adaptation и оптимизацию процесса генерации.
Заключение
В статье исследовано влияние генеративных диффузионных моделей на качество обучающих данных и эффективность обнаружения объектов моделью YOLOv8 на аэрофотоснимках.
Основные результаты:
- Синтезировано 500 изображений класса bicycle с использованием Stable Diffusion XL.
- Расширенная выборка (VisDrone + 500 синтетических изображений) позволила повысить mAP50 на 0.6 % на исходном наборе и на 3.5 % на внешнем наборе UAVDT.
- Наиболее заметное улучшение наблюдается на внешнем наборе данных, что свидетельствует о повышении обобщающей способности модели.
- Выявлены основные ограничения метода: шум автоматической разметки, распределительный сдвиг, вычислительная сложность.
Полученные результаты подтверждают перспективность применения генеративных моделей в задачах компьютерного зрения и дальнейшего развития методов автоматизированного формирования обучающих данных.
Литература:
- Goodfellow I., Bengio Y., Courville A. Deep Learning. — Cambridge: MIT Press, 2016. — 800 p.
- Redmon J., Farhadi A. YOLOv3: An Incremental Improvement // arXiv preprint arXiv:1804.02767. — 2018.
- Bochkovskiy A., Wang C.-Y., Liao H.-Y. M. YOLOv4: Optimal Speed and Accuracy of Object Detection // arXiv preprint arXiv:2004.10934. — 2020.
- Biswas S., Acharjee S., Ali A., Chaudhuri S. S. YOLOv8 based Traffic Signal Detection in Indian Road // Proceedings of 2023 7th International Conference on Electronics, Materials Engineering and Nano-Technology (IEMENTech). — Kolkata, 2023. — DOI: 10.1109/IEMENTech60402.2023.10423520.
- Jocher G., Chaurasia A., Qiu J. Ultralytics YOLOv8 Documentation. — 2023.
- Rombach R., Blattmann A., Lorenz D., Esser P., Ommer B. High-Resolution Image Synthesis with Latent Diffusion Models // Proceedings of the IEEE/CVF CVPR. — 2022. — P. 10684–10695.
- Podell D., English Z., Lacey K. et al. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis // arXiv:2307.01952. — 2023.
- Shorten C., Khoshgoftaar T. M. A Survey on Image Data Augmentation for Deep Learning // Journal of Big Data. — 2019. — Vol. 6, No. 60. — DOI: 10.1186/s40537–019–0197–0.
- Zhu P., Wen L., Du D. et al. Vision Meets Drones: A Challenge // International Journal of Computer Vision. — 2021. — Vol. 129. — P. 1604–1622.
- Du D., Zhu P., Wen L. et al. VisDrone-DET2019: The Vision Meets Drone Object Detection Challenge Results // Proceedings of ICCV Workshops. — 2019.
- Lin T.-Y., Goyal P., Girshick R. et al. Focal Loss for Dense Object Detection // IEEE TPAMI. — 2020. — Vol. 42, No. 2. — P. 318–327.
- Du D., Wen L., Zhang Z. et al. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking // Proceedings of ECCV Workshops. — 2018. (UAVDT)

