С быстрым развитием алгоритмов глубокого обучения постоянно появляются новые модели для повышения точности и эффективности систем обнаружения лиц. В статье автор предоставил всесторонний сравнительный анализ точности трех новейших моделей глубокого обучения — MobileNetV2, InceptionV3 и EfficientNetV2M.
Ключевые слова: обнаружение лиц, алгоритмы глубокого обучения, YOLO, MobileNetV2, InceptionV3 и EfficientNetV2M.
В реальных сценариях системы обнаружения лиц часто сталкиваются с не идеальными условиями, которые могут снизить их точность. Такие факторы, как слабое освещение, частичные препятствия (такие как очки, маски или шарфы), а также различия в возрасте и внешности, усложняют задачу обнаружения лиц.
В качестве исходных данных был выбран набор изображений SoF (Specs of Faces) [1]. Набор данных SoF был собран для поддержки тестирования и оценки алгоритмов обнаружения, распознавания и классификации лиц с использованием стандартизированных тестов и процедур. Для анализа используются наборы данных SoF (Specs of Faces) и UFDD (Unconstrained Face Detection Dataset) [2]. Наборы данных включает в себя фотографии лиц, снятые в сложных условиях. Набор данных включает изображения с различной освещенностью, частичным закрытием лица и различными углами поворота. Также набор данных включает в себя дистракторы, чтобы избежать ложные срабатывания.
Для оценки точности модели использовалась функция потерь YOLO (You Only Look Once) [3]. Функция потерь:
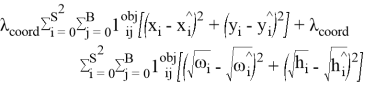
Это сумма отклонений между предсказанными координатами прямоугольника (x, y) и исходными координатами (x ^, y ^). В функции потерь YOLO используется переменная
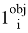
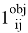
Для решения задачи обнаружения лица на изображении, нет необходимости использовать последний слой модели MobilnetV2 [4]. Вместо последнего слоя был добавлен слой для вывода результата классификации (в пределах от 0 до 1 будет выведена вероятность наличия лица на изображении) и для вывода регрессии (в данном случае это будут координаты для создания рамки вокруг области лица).
Структура модели MobilNetV2 для обнаружения лиц в сложных условиях, c учетом модификации выходного слоя, представлена рис. 1.
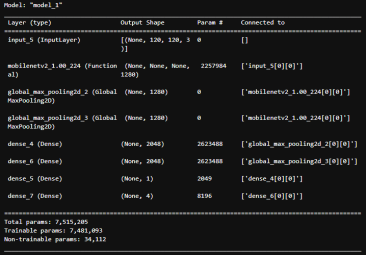
Рис. 1. Структура модели MobileNetV2
На каждом цикле обучения производился расчет потерь классификации и регрессии для тестового набора данных. График потерь классификации для каждой эпохи представлен на рис. 2.
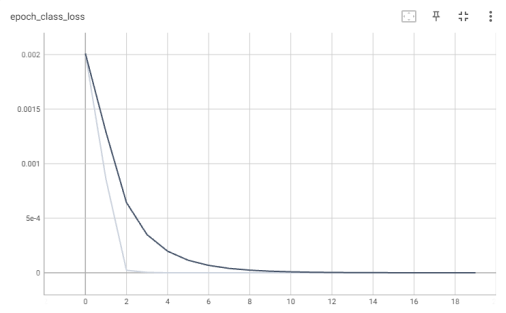
Рис. 2. График потерь классификации (модель MobilNetV2)
График потерь регрессии для каждой эпохи представлен на рис. 3.
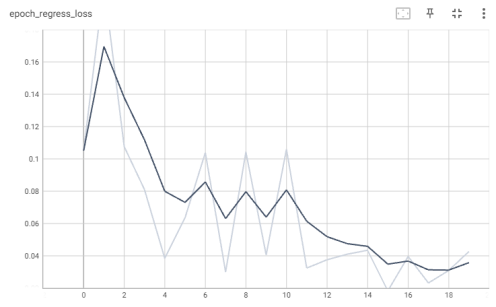
Рис. 3. График потерь регрессии (модель MobilNetV2)
Потери классификации минимальные, модель очень точно определяет наличие лица на изображении.
Точные значения потери регрессии на протяжении всего обучения представлены в таблице 1.
Таблица 1
Потери регрессии (модель MobilNetV 2)
|
Эпоха |
Потери |
|
0 |
0.10504406690597534 |
|
1 |
0.20822623372077942 |
|
2 |
0.1075989305973053 |
|
3 |
0.08101646602153778 |
|
4 |
0.038438551127910614 |
|
5 |
0.06355148553848267 |
|
6 |
0.10386467725038528 |
|
7 |
0.02997221238911152 |
|
8 |
0.10429469496011734 |
|
9 |
0.040532175451517105 |
|
10 |
0.10595577210187912 |
|
11 |
0.03241680562496185 |
|
12 |
0.03756047785282135 |
|
13 |
0.04101908951997757 |
|
14 |
0.04344494640827179 |
|
15 |
0.01833339035511017 |
|
16 |
0.039606355130672455 |
|
17 |
0.023190375417470932 |
|
18 |
0.030934931710362434 |
|
19 |
0.042713314294815063 |
Результат работы алгоритма на тестовом наборе данных представлен на рис. 4.

Рис. 4. Результат работы алгоритма (модель MobilNetV2)
Следующей моделью, на базе которой производился анализ работоспособности алгоритма обнаружения лиц в сложных условиях, является модель InceptionV3 [5].
Для решения задачи обнаружения лица на изображении, нет необходимости использовать последний слой модели InceptionV3. Вместо последнего слоя был добавлен слой для вывода результата классификации (в пределах от 0 до 1 будет выведена вероятность наличия лица на изображении) и для вывода регрессии (в данном случае это будут координаты для создания рамки вокруг области лица).
Структура модели InceptionV3 для обнаружения лиц в сложных условиях, c учетом модификации выходного слоя, представлена рис. 5.
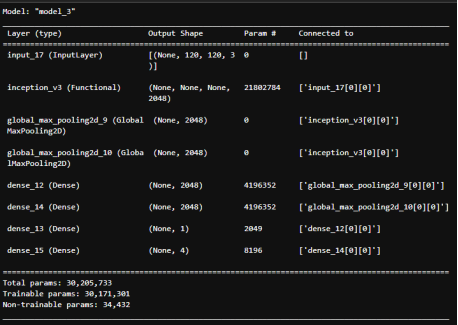
Рис. 5. Структура модели InceptionV3
На каждом цикле обучения производился расчет потерь классификации и регрессии для тестового набора данных. График потерь классификации для каждой эпохи представлен на рис. 6.
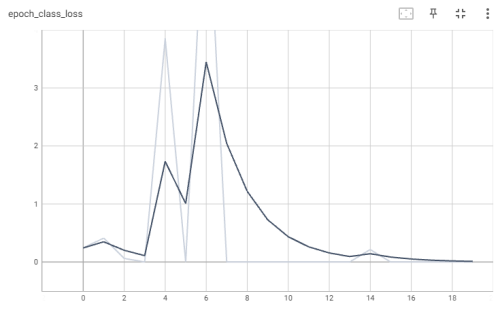
Рис. 6. График потерь классификации (модель InceptionV3)
График потерь регрессии для каждой эпохи представлен на рис. 7.
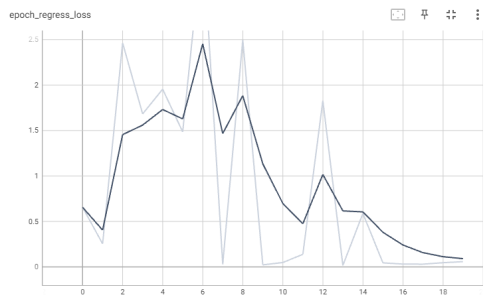
Рис. 7. График потерь регрессии (модель InceptionV3)
Одним из основных преимуществ модели InceptionV3 является значительное уменьшение размеров. Чтобы улучшить модель, большие свертки в модели были разложены на меньшие свертки, для повышения эффективности стала применяться ассиметричная свертка [4].
Точные значения потери регрессии на протяжении всего обучения представлены в таблице 2.
Таблица 2
Потери регрессии (модель InceptionV3)
|
Эпоха |
Потери |
|
0 |
0.6557143330574036 |
|
1 |
0.254692018032074 |
|
2 |
2.4627299308776855 |
|
3 |
1.682708740234375 |
|
4 |
1.9546241760253906 |
|
5 |
1.485050916671753 |
|
6 |
3.6339683532714844 |
|
7 |
0.027959946542978287 |
|
8 |
2.498767137527466 |
|
9 |
0.022721577435731888 |
|
10 |
0.04823381081223488 |
|
11 |
0.13830459117889404 |
|
12 |
1.8286422491073608 |
|
13 |
0.016260862350463867 |
|
14 |
0.5882518291473389 |
|
15 |
0.04462695121765137 |
|
16 |
0.03128504753112793 |
|
17 |
0.030403083190321922 |
|
18 |
0.046327508985996246 |
|
19 |
0.05808452516794205 |
Результат работы алгоритма на тестовом наборе данных представлен на рис. 8.

Рис. 8. Результат работы алгоритма (модель InceptionV3)
Следующей моделью, на базе которой производился анализ работоспособности алгоритма обнаружения лиц в сложных условиях, является модель EfficientNetV2M [6].
Для решения задачи обнаружения лица на изображении, нет необходимости использовать последний слой модели EfficientNetV2. Вместо последнего слоя был добавлен слой для вывода результата классификации (в пределах от 0 до 1 будет выведена вероятность наличия лица на изображении) и для вывода регрессии (в данном случае это будут координаты для создания рамки вокруг области лица).
Структура модели EfficientNetV2 для обнаружения лиц в сложных условиях, c учетом модификации выходного слоя, представлена рис. 9.
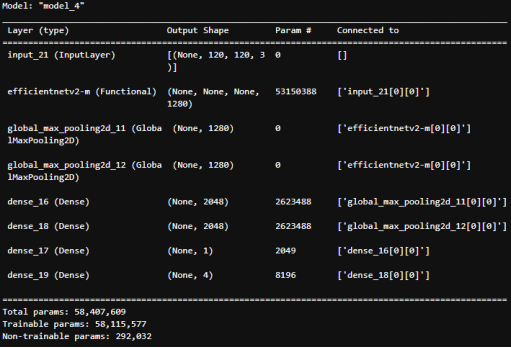
Рис. 9. Структура модели EfficientNetV2
На каждом цикле обучения производился расчет потерь классификации и регрессии для тестового набора данных. График потерь классификации для каждой эпохи представлен на рис. 10.
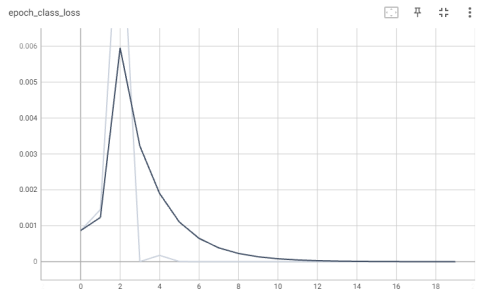
Рис. 10. График потерь классификации (модель EfficientNetV2)
График потерь регрессии для каждой эпохи представлен на рис. 11.
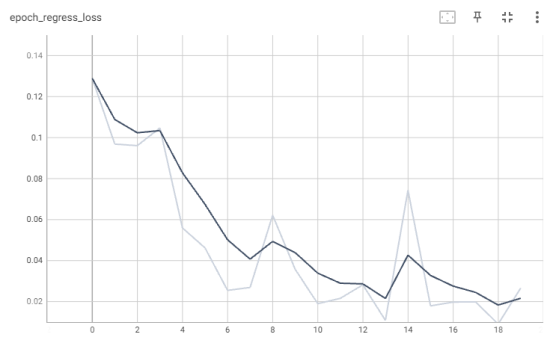
Рис. 11. График потерь регрессии (модель EfficientNetV2)
EfficientNetV2 — это улучшенная версия архитектуры EfficientNet, которая фокусируется на достижении баланса между размером модели и производительностью. Эта модель использует комплексное масштабирование для оптимизации глубины, ширины и разрешения сети, что приводит к повышению точности [6]. Точные значения потери регрессии на протяжении всего обучения представлены в таблице 3.
Таблица 3
Потери регрессии (модель EfficientNetV2)
|
Эпоха |
Потери |
|
0 |
0.1288861632347107 |
|
1 |
0.09682343155145645 |
|
2 |
0.09609387814998627 |
|
3 |
0.10471370816230774 |
|
4 |
0.05593157559633255 |
|
5 |
0.04620803892612457 |
|
6 |
0.025467902421951294 |
|
7 |
0.026901107281446457 |
|
8 |
0.062128305435180664 |
|
9 |
0.03572523593902588 |
|
10 |
0.018981970846652985 |
|
11 |
0.021587030962109566 |
|
12 |
0.028184417635202408 |
|
13 |
0.01083668414503336 |
|
14 |
0.0743752270936966 |
|
15 |
0.017897794023156166 |
|
16 |
0.019770247861742973 |
|
17 |
0.019880736246705055 |
|
18 |
0.009030135348439217 |
|
19 |
0.026617076247930527 |
Результат работы алгоритма на тестовом наборе данных представлен на рис. 12.

Рис. 12. Результат работы алгоритма (модель EfficientNetV2)
Минимальные средние значения потери регрессии для каждой модели представлены в таблице 4.
Таблица 4
Минимальные потери регрессии
|
Модель |
Минимальное значение потери |
|
MobileNetV2 |
0.01833339035511017 |
|
InceptionV3 |
0.016260862350463867 |
|
EfficientNetV2M |
0.009030135348439217 |
На основе проведенных экспериментов и анализа были сделаны следующие наблюдения:
MobileNetV2 демонстрирует высокую производительность в сложных условиях благодаря своей легкой архитектуре. Он эффективно фиксирует основные черты лица даже при слабом освещении и частичных окклюзиях.
InceptionV3 демонстрирует хорошую производительность по всем направлениям. Его многоотраслевая архитектура помогает захватывать функции в разных масштабах, что оказывается полезным в сложных условиях. Эта модель демонстрирует сбалансированный компромисс между точностью и отзывчивостью.
EfficientNetV2M превосходит другие модели с точки зрения точности, что предполагает его способность минимизировать ложноположительные прогнозы. Эта характеристика имеет решающее значение в сценариях, где ложные обнаружения не допустимы.
В этом отчете проведен всесторонний анализ трех моделей машинного обучения для распознавания лиц в сложных условиях: MobileNetV2, InceptionV3 и EfficientNetV2M. Эксперименты показали, что каждая модель имеет свои сильные и слабые стороны, что делает их подходящими для разных сценариев. Эффективность MobileNetV2, многоотраслевая архитектура InceptionV3 и ориентированный на точность подход EfficientNetV2M вносят свой вклад в их соответствующие достоинства производительности. Выбор модели должен основываться на конкретных требованиях приложения и важности компромиссов между точностью и отзывом.
Литература:
1. Specs on Faces (SoF) Dataset. — Текст: электронный // SoF dataset: [сайт]. — URL: https://ufdd.info/ (дата обращения: 30.08.2023).
2. Unconstrained Face Detection Dataset (UFDD). — Текст: электронный // UFDD_Dataset: [сайт]. — URL: https://ufdd.info/ (дата обращения: 30.08.2023).
3. You Only Look Once: Unified, Real-Time Object Detection. — Текст: электронный // arXiv.org e-Print archive: [сайт]. — URL: https://arxiv.org/abs/1506.02640 (дата обращения: 30.08.2023).
4. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. — Текст: электронный // arXiv.org e-Print archive: [сайт]. — URL: https://arxiv.org/abs/1704.04861 (дата обращения: 30.08.2023).
5. Rethinking the Inception Architecture for Computer Vision. — Текст: электронный // arXiv.org e-Print archive: [сайт]. — URL: https://arxiv.org/abs/1512.00567 (дата обращения: 30.08.2023).
6. EfficientNetV2: Smaller Models and Faster Training. — Текст: электронный // arXiv.org e-Print archive: [сайт]. — URL: https://arxiv.org/abs/2104.00298 (дата обращения: 30.08.2023).

