В современных системах управления рисками, внедрённых на крупных промышленных предприятиях, ключевой этап — количественная и качественная оценка риска — в значительной степени зависит от личного опыта и квалификации владельца риска. Как показывают исследования, доля рисков, оцениваемых преимущественно качественными (экспертными) методами без количественного подтверждения, может достигать 70–80 % [1, 2]. Следствием этого является систематическая недооценка угроз: от 20 до 30 % значимых рисков не идентифицируются на этапе предварительной оценки.
Одной из причин сложившейся ситуации является неиспользование накопленного корпоративного опыта. За годы функционирования систем управления рисками на предприятиях формируются обширные архивы информации о значимых рисках — о тех угрозах, которые прошли полный цикл согласования, получили высокие оценки критичности и, возможно, уже реализовались с финансовыми потерями. Однако в большинстве систем этот архив играет роль пассивного хранилища. Он не используется для анализа новых рисков, не помогает выявлять «слабые сигналы» и не служит базой для обучения сотрудников [3].
Настоящая статья посвящена методике превентивной идентификации рисков, которая позволяет устранить указанный недостаток за счёт автоматического сопоставления новых предварительных рисков с архивом значимых инцидентов прошлых лет.
Проблематика существующего процесса
Типовой процесс идентификации и согласования рисков на крупном промышленном предприятии представлен на рис. 1. Он включает следующие этапы:
– доступ и авторизация в системе;
– идентификация риска (заполнение базовых полей и паспорта риска);
– интеграция с системой электронного документооборота (СЭД) и отправка на согласование;
– доработка по замечаниям и утверждение;
– реализация мероприятий по управлению риском.
Ключевое узкое место существующего процесса — не предусмотрен этап проверки нового риска на предмет его сходства с уже известными значимыми инцидентами. Владелец риска заполняет паспорт, после чего сразу направляет его на согласование, полагаясь исключительно на собственный опыт. При этом архив прошлых значимых рисков остаётся невостребованным.

Рис. 1. Схема существующего процесса идентификации и согласования рисков
2. Предлагаемый модуль и его место в процессе
Для устранения выявленного недостатка предлагается дополнительный аналитический модуль «Проверка на аналогии», который встраивается между этапом детализации паспорта риска и этапом отправки на согласование (рис. 2).
Модуль выполняет следующие функции:
– анализирует текстовые описания нового риска (причина, рисковое событие, последствия);
– выполняет автоматический поиск совпадений в архиве значимых рисков;
– отображает владельцу найденные аналоги с указанием их критичности и фактического ущерба (при наличии);
– предлагает скорректировать оценку риска на основе полученной информации или оставить без изменений.
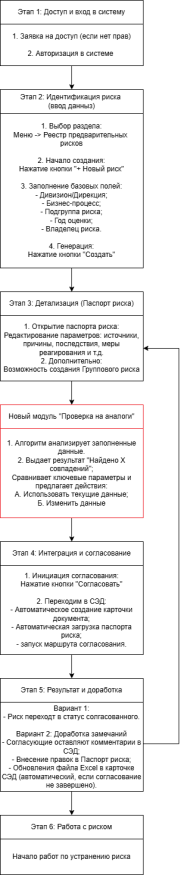
Рис. 2. Схема предлагаемого процесса с модулем «Проверка на аналогии»
Модуль включает три основных компонента:
- Хранилище данных (архив значимых рисков). В базу данных автоматически заносятся все риски, получившие по итогам согласования высокую оценку критичности. Для каждого риска сохраняются: текстовое описание (причина, событие, последствия), итоговая критичность, применённые меры управления, фактический ущерб (при наличии).
- Механизм сравнения (поисковый движок). Сопоставление текста нового риска с архивом осуществляется на основе анализа ключевых полей с использованием методов предобработки текста и расчёта степени сходства.
- Пользовательский интерфейс. Взаимодействие организовано через кнопку «Проверить аналоги» в форме создания риска, окно с результатами поиска и дашборд риск-менеджера.
Алгоритм функционирования модуля включает семь последовательных шагов:
- Создание записи о риске. Владелец риска заполняет текстовые поля «причина», «рисковое событие», «последствия».
- Запуск проверки. Владелец нажимает кнопку «Проверить аналоги» (либо проверка запускается автоматически при сохранении записи).
- Извлечение текста. Система извлекает текстовые значения из указанных полей.
- Поиск в архиве. Алгоритм выполняет поиск в архиве значимых рисков, вычисляя степень сходства с каждой записью.
- Ранжирование результатов. Результаты сортируются по убыванию степени сходства (от наиболее похожих к менее похожим).
- Отображение подсказки. Система отображает список найденных аналогов с указанием их критичности и фактического ущерба.
- Корректировка оценки (опционально). Владелец риска анализирует полученную информацию и при необходимости корректирует свою первоначальную оценку, после чего риск направляется на согласование.
Ключевым элементом модуля является механизм формализованного сопоставления текстов. Он включает следующие этапы.
Текстовые поля проходят следующую обработку:
– разбивка на отдельные слова (токены) с удалением знаков препинания;
– приведение к нижнему регистру;
– удаление стоп-слов (предлоги, союзы, местоимения, а также общеупотребительные слова без смысловой нагрузки);
– стемминг — приведение слов к начальной форме (например: «насосного» → «насос», «абразивного» → «абразив»).
Различным текстовым полям присваиваются весовые коэффициенты в зависимости от их значимости для идентификации риска:
– поле «рисковое событие» — коэффициент 0,5 (наиболее значимо);
– поле «причина» — коэффициент 0,3;
– поле «последствия» — коэффициент 0,2.
Сумма коэффициентов равна 1, что позволяет при расчёте итоговой степени сходства учитывать вклад каждого поля.
Для каждого поля вычисляется сходство по метрике Жаккара:
Сходство_поле = |A ∩ B| / |A ∪ B|
где:
A — множество токенов текста нового риска в соответствующем поле;
B — множество токенов текста архивного риска в соответствующем поле.
Метрика принимает значения от 0 (полное отсутствие общих слов) до 1 (полное совпадение).
Итоговая степень сходства для записи в архиве рассчитывается как взвешенная сумма:
Сходство = (Сходство_событие × 0,5) + (Сходство_причина × 0,3) + (Сходство_последствия × 0,2)
В результатах поиска отображаются только те архивные риски, у которых итоговая степень сходства превышает пороговое значение 0,25 (настраиваемый параметр). При обнаружении более трёх аналогов система отображает топ-5 наиболее релевантных результатов.
Рассмотрим гипотетическую ситуацию. Владелец риска на горно-металлургическом предприятии создаёт новый риск с описанием:
«Риск выхода из строя насосного оборудования на участке гидротранспорта пульпы ввиду повышенного износа рабочих колёс по причине абразивного воздействия»
Без модуля владелец полагается исключительно на собственный опыт и может оценить риск как средний. После нажатия кнопки «Проверить аналоги» модуль находит в архиве два значимых риска за прошлые годы:
– риск № 1 с критичностью B: «Выход из строя насоса на гидротранспорте», фактический ущерб — 8 млн условных единиц;
– риск № 2 с критичностью A: «Аварийная остановка участка гидротранспорта», фактический ущерб — 15 млн условных единиц, простой — 14 дней.
Увидев эту информацию, владелец корректирует свою оценку в сторону повышения. Риск, который мог бы остаться незамеченным, получает корректную оценку и направляется на согласование как значимый.
Таблица 1
Рекомендации по внедрению модуля
|
Этап |
Содержание |
Длительность |
|
1.Подготовительный |
Аудит данных, формирование архива значимых рисков, «чистка» данных |
1–2 месяца |
|
2. Разработка прототипа |
Создание интерфейса, настройка механизма поиска, интеграция с существующей системой |
2–3 месяца |
|
3. Пилотное внедрение |
Выбор пилотной группы, обучение пользователей, сбор обратной связи |
1–2 месяца |
|
4. Масштабирование |
Доработка по итогам пилота, развёртывание на всех подразделениях |
1–2 месяца |
Таблица 2
Расчет оценки эффективности модуля
|
Показатель |
Способ расчёта |
Целевое значение |
|
Коэффициент принятия подсказок |
(Число рисков, чья оценка скорректирована) / (Общее число рисков, проверенных модулем) |
≥ 30 % |
|
Точность (Precision) |
TP / (TP + FP) |
≥ 0,70 |
|
Полнота (Recall) |
TP / (TP + FN) |
≥ 0,60 |
|
Пользовательская удовлетворённость |
Оценка по 5-балльной шкале |
≥ 4 балла |
Предложенная методика превентивной идентификации рисков на основе анализа корпоративного архива значимых инцидентов позволяет:
– Использовать накопленный архив как активный инструмент — от пассивного хранения к активной поддержке принятия решений.
– Снизить занижение оценок — владелец риска получает объективную информацию о прошлых инцидентах (критичность, фактический ущерб).
– Создать систему раннего предупреждения — риск, который мог бы быть недооценён, получает корректную оценку ещё до отправки на согласование.
– Измерить эффективность — предложенная система KPI позволяет количественно оценить вклад модуля в повышение качества идентификации рисков.
Разработанная методика может быть реализована на различных технологических платформах (SharePoint, «1С», SAP и т. п.) и не требует кардинальной перестройки существующих систем управления рисками.
Литература:
- Казакова Н. А., Когденко В. Г. Подходы к мониторингу и прогнозированию секторальных рисков финансовой безопасности компаний в цифровой среде // Плехановский научный бюллетень. 2022. № 1 (21). С. 100–109.
- Когденко В. Г. Разработка алгоритмов стресс-тестирования компаний (на примере металлургии) // Финансы и кредит. 2023. Т. 29. № 10 (838). С. 2376–2408.
- Тивоненко В. А. Риск-ориентированный подход в вопросах ведения финансовой деятельности в горно-металлургической отрасли // Российский экономический интернет-журнал. 2024. № 3.

