Введение
Технологии оптического распознавания символов (Optical Character Recognition, OCR) являются одним из ключевых инструментов цифровой обработки документов, которая имела революционный характер на первоначальном этапе своего развития. Основная задача заключалась в преобразовании текстовой информации, представленной, как правило, в виде изображений или сканированных документов, в машинно-читаемый формат. Первоначально OCR-системы ориентировались преимущественно на обработку печатного текста и успешно применялись для цифровизации архивов, библиотечных фондов и документооборота [4].
Существенным ограничением ранних решений являлась низкая эффективность при работе с рукописным текстом. Разнообразие почерков, наличие исправлений, неравномерность написания символов и влияние шумов на изображении значительно усложняли процесс распознавания. Развитие методов машинного обучения и появление нейронных сетей позволили существенно повысить качество обработки подобных данных. Для решения задач распознавания текста получили распространение многослойные персептроны (MLP), сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN), сети с долгой краткосрочной памятью (LSTM), а также современные архитектуры на основе механизма внимания и трансформеров [5].
В настоящее время наряду со специализированными OCR-системами широко используются облачные сервисы распознавания документов и мультимодальные большие языковые модели, например, такие как Gemini, GPT. В отличие от локально устанавливаемых решений, таких как Tesseract, EasyOCR и PaddleOCR, которые нередко требуют тонкой настройки и больших вычислительных мощностей, для обработки массивных дата сетов. Облачные платформы предоставляют готовую инфраструктуру обработки данных и не требуют настройки вычислительных ресурсов, обучения моделей и их последующего сопровождения. Кроме того, современные мультимодальные модели способны учитывать контекст текста, что позволяет повысить качество распознавания сложных рукописных документов, хоть иногда и имеет место быть «додумывание» некоторых символов.
Практическая значимость данной задачи особенно высока в образовательной сфере. Одним из перспективных направлений является создание автоматизированных систем проверки школьных работ, например, таких как диктанты, позволяющих снизить нагрузку на преподавателей и повысить объективность контроля знаний. В рамках исследования, будет использован разработанный программный комплекс проверки диктантов, в котором используется модель оценивания, основанная на принципах нечеткой логики, обеспечивающая формирование итоговой оценки по результатам анализа допущенных ошибок [2, 3]. Ключевым этапом работы такой системы является корректное распознавание рукописного текста учащихся.
В связи с этим возникает необходимость сравнительного анализа различных подходов к распознаванию текста в условиях реальных образовательных данных. Для этого был собран дата сет из реальных школьных работ, состоящий из 28 диктантов, а в качестве экспериментальной платформы используется разработанная автоматизированная система проверки школьных диктантов, позволяющая оценить эффективность традиционных OCR-библиотек, облачных сервисов распознавания документов и современных мультимодальных больших языковых моделей при обработке рукописных работ учащихся. Проведение такого исследования позволяет определить наиболее эффективные решения с точки зрения точности распознавания, скорости обработки, доступности внедрения и затрат на эксплуатацию.
Объект исследования
Объектом исследования является процесс автоматизированного распознавания рукописного текста в составе программы проверки школьных диктантов, функционирующей на основе гибридного подхода, который интегрирует аппарат оптического распознавания символов, лингвистической проверки и вычислительно-оценочного модуля с использованием нечеткой логики для формирования итоговой оценки [1, 6]. В рамках работы исследуется возможность применения различных технологий оптического распознавания текста для обработки рукописных работ учащихся [12, 13].
Рассматриваемые решения можно разделить на несколько групп. К первой относятся локально устанавливаемые OCR-системы, такие как Tesseract, EasyOCR и PaddleOCR, использующие различные нейросетевые архитектуры для обнаружения и распознавания текстовой информации. Ко второй группе относятся облачные сервисы распознавания документов, такие как Yandex Vision OCR и Google Cloud OCR, предоставляющие доступ к готовым моделям через программный интерфейс. Третью группу составляют современные мультимодальные большие языковые модели, способные выполнять распознавание текста на изображениях с учетом языкового контекста, такие как Gemini и GPT.
Исследование направлено на анализ применимости перечисленных подходов для обработки школьных диктантов, характеризующихся наличием рукописного текста, индивидуальных особенностей почерка, исправлений и различного качества исходных изображений. Особое внимание уделяется оценке качества распознавания, так как стоит острая необходимость максимально точной передачи текста для последующей эффективной обработки развернутых, неструктурированных или частично правильных ответов, что является значительной проблемой для стандартных методов проверки знаний [2, 3].
Цель и задачи исследования
Целью настоящего исследования является проведение сравнительного анализа современных технологий оптического распознавания текста для выбора наиболее эффективного OCR-решения в составе автоматизированной системы проверки школьных диктантов, использующей методы нечеткой логики для оценки знаний учащихся.
Работа носит смешанный теоретико-практический характер. Теоретическая часть исследования направлена на анализ существующих подходов к распознаванию текста и используемых в них нейросетевых архитектур [3, 5, 7, 8, 10, 11, 13]. Практическая часть заключается в экспериментальной оценке качества проверки рукописных работ различных OCR-решений на реальных образцах школьных диктантов и определении их пригодности для интеграции в разрабатываемую систему автоматизированной проверки.
Для достижения поставленной цели необходимо решить следующие задачи:
– Рассмотреть основные архитектурные подходы, применяемые в OCR-системах и выполнить классификацию существующих решений для распознавания текста. Для этого необходимо выделить основные группы исследуемых технологий;
– Подготовить дата сет, включающий реальные рукописные школьные диктанты, предназначенные для оценки качества распознавания текста в условиях, приближенных к практической эксплуатации системы и разработать методику сравнительного тестирования рассматриваемых OCR-решений. Для этого нужно определить набор критериев оценки, включающий точность распознавания текста, качество обработки рукописного ввода, скорость выполнения запросов, сложность интеграции и требования к вычислительным ресурсам;
– Провести экспериментальное исследование качества распознавания рукописных диктантов и выполнить сопоставительный анализ полученных результатов, выявить преимущества и недостатки каждого подхода, а также определить влияние качества распознавания на дальнейшую работу системы автоматизированного оценивания знаний;
– На основе проведенного исследования сформулировать рекомендации по выбору OCR-модуля для использования в автоматизированной системе проверки школьных диктантов и определить наиболее перспективные направления дальнейшего развития подобных образовательных систем.
Методы исследования
В основе данного исследования лежит комплексный подход, сочетающий методы теоретического анализа и экспериментального тестирования. Работа направлена как на изучение современных технологий оптического распознавания текста, так и на практическую оценку их эффективности в составе автоматизированной системы проверки школьных диктантов и её нечеткой модели оценивания.
Теоретическая часть исследования основана на анализе научных публикаций, технической документации OCR-систем, компьютерного зрения и больших языковых моделей [3, 5, 7, 8, 9, 10, 11]. В процессе работы были рассмотрены основные архитектурные подходы, применяемые для распознавания текста. Особое внимание уделялось особенностям их применения для обработки рукописного текста и возможностям интеграции в образовательные информационные системы.
Практическая часть исследования основывается на экспериментальном сравнении различных решений для распознавания текста. В качестве тестовой выборки использовались реальные образцы школьных диктантов, собранные в образовательной организации. Сформированный набор данных включал рукописные работы учащихся, содержащие различные стили письма, уровень разборчивости текста и характерные особенности оформления.
Для проведения сравнительного анализа были отобраны три группы технологий распознавания текста:
– локально устанавливаемые OCR-системы (Tesseract, EasyOCR, PaddleOCR);
– облачные сервисы распознавания документов (Google Cloud Vision OCR, Yandex Vision OCR);
– мультимодальные большие языковые модели (GPT и Gemini).
Таким образом, использованная методология сочетает теоретическое исследование существующих подходов с практической проверкой их эффективности на реальных образовательных данных, что обеспечивает точность и объективность полученных результатов.
Результаты исследования
В качестве экспериментальной платформы использовалась разработанная автоматизированная система проверки школьных диктантов (АСПШД) Программа предназначена для автоматизации процесса оценки знаний учащихся. Система объединяет модуль распознавания текста, модуль анализа орфографических ошибок и подсистему выставления итоговой оценки на основе методов нечеткой логики [2, 3].
Общая структура системы представлена на рис. 1. Кратко, работа программы следующая, что пользователь загружает фотографию или сканированное изображение рукописной работы учащегося, после чего ранее предустановленный или подключенный облачный OCR-модуль выполняет распознавание текста. В зависимости от используемой технологии обработка осуществляется либо локально на устройстве пользователя, либо посредством обращения к внешнему облачному сервису через программный интерфейс (API). Полученный текст передается в модуль анализа ошибок, где производится его сопоставление с эталонным вариантом диктанта. На основании выявленных ошибок формируется итоговая оценка с использованием механизмов нечеткого вывода.
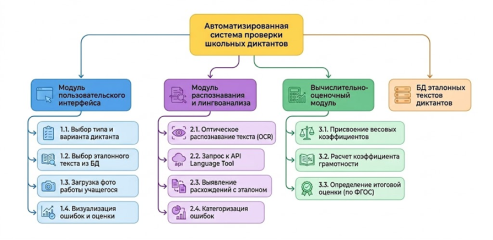
Рис. 1. Общая схема автоматизированной системы проверки школьных диктантов
Для проведения эксперимента был проведен диктант в одном из школьных классов. После проведения диктанта были собраны ученические тетради, содержащие рукописные работы. Далее работы были сфотографированы и переданы учителю на проверку. Результат его проверки будет необходим для независимой оценки в качестве эталонного значения при анализе качества распознавания текста различными OCR-решениями. Фотографии рукописных работ предоставлены на рис. 2.
Рис. 2. Фотографии рукописных работ, использованных в исследовании (фрагмент)
Анализ источников [14, 15, 16, 17, 18, 19, 20] показал, что в рамках эксперимента стоит внимания уделить рассмотрению трех групп технологий распознавания текста:
– локальные OCR-библиотеки (Tesseract, EasyOCR, PaddleOCR);
– облачные сервисы распознавания документов (Yandex Vision OCR, Google Cloud Vision OCR);
– мультимодальные большие языковые модели (GPT и Gemini).
Каждая технология применялась к одинаковому набору рукописных работ. Полученные результаты сравнивались по качеству распознавания текста, удобству интеграции, требованиям к вычислительным ресурсам, стоимости использования и доступности технологии.
Tesseract является одной из наиболее известных классических OCR-систем с открытым исходным кодом. Преимуществами решения являются бесплатное распространение, простота локального запуска. Однако была выявлена ужасно низкая устойчивость к особенностям рукописного текста, что привело к значительному количеству ошибок и полному провалу распознавания текста [14].
EasyOCR продемонстрировал более высокое качество обработки рукописных текстов по сравнению с Tesseract. Модуль обладает простой интеграцией и поддерживает русский язык без дополнительной настройки, хотя установка дополнительных библиотек или до обучения на обширных дата сетах, может значительно повысить работоспособность модели. Среди недостатков следует отметить повышенные требования к вычислительным ресурсам и нестабильность результатов на изображениях низкого качества [16].
PaddleOCR представляет собой современную OCR-платформу, использующую нейросетевые архитектуры для распознавания документов. Безусловно крайне приятный продукт с простой интеграцией и обширным количеством дополнительных библиотек, но несмотря на хорошие показатели при обработке печатного текста, в ходе исследования были выявлены сложности при работе с русскоязычными рукописными материалами, что ограничило практическую применимость решения [17].
Yandex Vision OCR показал высокое качество распознавания русскоязычных документов и удобство интеграции посредством API, но все же было место присутствию ошибок и неточностей, а также аномалий. Иногда требовалось проведение повторных тестов, так как только в одном из трех случаев удавалось добиться приемлемых результатов. Дополнительным преимуществом является отсутствие инфраструктурных ограничений для использования на территории Российской Федерации. Вместе с тем использование сервиса связано с оплатой запросов после исчерпания бесплатного лимита [18].
Google Cloud Vision OCR продемонстрировал стабильные результаты распознавания и высокую скорость обработки документов. Однако использование сервиса требует дополнительной настройки доступа и в ряде случаев может сопровождаться ограничениями, связанными с региональной доступностью сервисов [15].
Мультимодальная модель GPT показала высокий уровень качества распознавания рукописного текста благодаря использованию языкового контекста и способности восстанавливать отдельные слова даже при низком качестве изображения, хоть с оговоркой на то, что от модели требуется максимальная точность, без «додумывания» результатов. Основным ограничением данного решения является высокая стоимость использования API, что затрудняет его применение в образовательных проектах с ограниченным бюджетом и региональной доступностью сервиса [19].
Наиболее высокие результаты в проведенном исследовании продемонстрировала модель Gemini . Использование мультимодального подхода позволило обеспечить высокую точность распознавания рукописного текста и корректную обработку большинства ученических работ. Дополнительным преимуществом является наличие бесплатного лимита запросов (15 в минуту), достаточного для проведения экспериментальных исследований и тестирования образовательных систем. Основными недостатками являются ограничения региональной доступности сервиса и необходимость использования дополнительных средств доступа в отдельных странах [20].
Результаты сравнительного анализа рассмотренных решений представлены в таблице 1.
Таблица 1
Сравнительный анализ OCR-технологий

Проведенное исследование показало, что современные мультимодальные модели и облачные OCR-сервисы превосходят локальные OCR-библиотеки при обработке рукописных школьных диктантов. Наиболее сбалансированным решением по совокупности критериев качества распознавания, удобства интеграции и доступности оказался сервис Gemini, который был выбран в качестве базового OCR-модуля для дальнейшего развития автоматизированной системы проверки школьных диктантов.
Заключение
В рамках настоящего исследования был проведен анализ современных технологий оптического распознавания текста применительно к задаче автоматизированной проверки школьных диктантов. Рассмотрены различные подходы к распознаванию рукописного текста, включая локально устанавливаемые OCR-библиотеки, облачные сервисы обработки документов и современные мультимодальные большие языковые модели.
Для экспериментальной оценки разработана и использована автоматизированная система проверки школьных диктантов, включающая модуль распознавания текста и подсистему оценки знаний, основанную на принципах нечеткой логики. В качестве тестовых данных использовались реальные рукописные работы учащихся начальных классов, что позволило провести исследование в условиях, максимально приближенных к практической эксплуатации образовательной системы.
Результаты проведенного анализа показали, что традиционные OCR-библиотеки способны эффективно обрабатывать печатный текст, однако их качество при распознавании рукописных школьных работ остается ограниченным. Более высокие результаты продемонстрировали облачные сервисы распознавания документов, обеспечивающие качественную обработку русскоязычных материалов и удобство интеграции посредством программных интерфейсов.
Наиболее эффективными средствами распознавания рукописного текста в рамках проведенного исследования оказались мультимодальные большие языковые модели. Благодаря использованию языкового контекста данные решения способны корректно интерпретировать фрагменты текста даже при наличии особенностей почерка, шумов изображения и иных факторов, осложняющих процесс распознавания. Среди рассмотренных решений наиболее сбалансированные результаты по совокупности критериев качества распознавания, доступности и удобства использования продемонстрировала модель Gemini, которая была выбрана в качестве базового OCR-модуля для дальнейшего развития автоматизированной системы проверки школьных диктантов.
Полученные результаты подтверждают перспективность использования современных мультимодальных моделей в образовательных информационных системах и демонстрируют возможность их эффективного применения для автоматизации процессов контроля знаний. Дальнейшее развитие исследования может быть связано с расширением набора тестовых данных, проведением количественной оценки качества распознавания на более крупных выборках, а также совершенствованием алгоритмов анализа ошибок и механизмов нечеткого оценивания результатов проверки.
Литература:
- Григорьев, А. П., Мамаев, В. Я. О применении нейронных сетей в тестировании знаний // НП. 2016. № 4. URL: https://cyberleninka.ru/article/n/o-primenenii-neyronnyh-setey-v-testirovanii-znaniy (дата обращения: 04.06.2026).
- Рудинский, И. Д. Структурные основы тестологии / И. Д. Рудинский. — 2-е изд., испр. — Москва: Горячая линия–Телеком, 2015. — 244 с.
- Хоч, М. Д. Использование нечеткой модели в автоматизированной системе тестирования знаний / М. Д. Хоч // Материалы IV Национальной научно-технической конференции студентов и курсантов «Дни науки». — Калининград: Изд-во БГАРФ ФГБОУ ВО «КГТУ», 2025. — С. 288–290.
- Шевцов, Д. В. Системы распознавания изображений как средство автоматизации процессов документооборота / Д. В. Шевцов // Программная инженерия: методы и технологии разработки информационно-вычислительных систем (ПИИВС-2018): Сборник научных трудов II Международной научно-практической конференции, Донецк, 14–15 ноября 2018 года. Том 1. — Донецк: Донецкий национальный технический университет, 2018. — С. 185–193. — EDN UUMABC.
- Береснев, Д. В. Исследования методов распознавания текстовых документов с использованием компьютерного зрения / Д. В. Береснев // Искусственный интеллект в промышленных, коммерческих, медицинских и финансовых приложениях: сборник статей научно-технического семинара студентов кафедры «Инженерной кибернетики», Москва, 30–31 мая 2024 года. — Москва: Национальный исследовательский технологический университет «МИСИС», 2024. — С. 23–29. — EDN XIDCPH.
- Шилоносов, А. В. Интеллектуальная измерительная система на основе нейросетевых технологий и нечеткой логики // Вестник ТГТУ. 2022. № 2. URL: https://cyberleninka.ru/article/n/intellektualnaya-izmeritelnaya-sistema-na-osnove-neyrosetevyh-tehnologiy-i-nechetkoy-logiki (дата обращения: 04.06.2026).
- Тельбух, В. В., Глыбовский П. А., Гудков, А. С., Ратушняк, И. А. Подход к проектированию интеллектуальной вопросно-ответной системы, построенной на основе применения нейронных сетей// Известия ТулГУ. Технические науки. 2025. № 2. URL: https://cyberleninka.ru/article/n/podhod-k-proektirovaniyu-intellektualnoy-voprosno-otvetnoy-sistemy-postroennoy-na-osnove-primeneniya-neyronnyh-setey (дата обращения: 04.06.2026).
- Рогожина, А. О. Проектирование нейронной сети для оптического распознавания текста (OCR) / А. О. Рогожина // Публичное управление в России: новые импульсы, векторы, возможности: Сборник научных трудов IX Всероссийской научно-практической конференции, Саратов, 26–28 февраля 2025 года. — Саратов: Российская академия народного хозяйства и государственной службы при Президенте РФ, 2025. — С. 157–161. — EDN GDBXII.
- К. А. Бобров, В. Д. Шульман, К. П. Власов Анализ технологий распознавания текста из изображения // Международный журнал гуманитарных и естественных наук. 2022. № 3–2. URL: https://cyberleninka.ru/article/n/analiz-tehnologiy-raspoznavaniya-teksta-iz-izobrazheniya (дата обращения: 04.06.2026).
- Трифонов, К. В. Сравнение сверточной и рекуррентной архитектур нейронных сетей при решении задачи анализа тональности текста // Молодой исследователь Дона. 2024. № 2. URL: https://cyberleninka.ru/article/n/sravnenie-svertochnoy-i-rekurrentnoy-arhitektur-neyronnyh-setey-pri-reshenii-zadachi-analiza-tonalnosti-teksta (дата обращения: 04.06.2026).
- Mashru, D. Comparative Analysis of CNN, RNN, LSTM, and Transformer Architectures in Deep Learning / D. Mashru, K. Vora // Educational Administration: Theory and Practice. — 2023. — Vol. 29, No. 4. — P. 5439–5443.
- Зубрилин, А. А. Обучение студентов педагогического вуза работе с OCR-системами / А. А. Зубрилин // Цифровые образовательные технологии: методология и практика: Монография. — Саранск: Мордовский государственный педагогический университет им. М. Е. Евсевьева, 2024. — С. 39–54. — EDN MXSLFE.
- Сергеева, Н. А. К вопросу о технологии оцифровки архивных документов / Н. А. Сергеева, А. С. Кулагин, Г. М. Тростянский // Столица науки. — 2020. — № 11(28). — С. 46–51. — EDN WNVQBY.
- Tesseract OCR. — [Электронный ресурс]. — Режим доступа: https://github.com/tesseract-ocr/tesseract (дата обращения: 04.06.2026).
- Google Cloud Vision API. — [Электронный ресурс] — Режим доступа: https://cloud.google.com/vision/ (дата обращения: 04.06.2026).
- EasyOCR. — [Электронный ресурс]. — Режим доступа: https://github.com/JaidedAI/EasyOCR (дата обращения: 04.06.2026).
- PaddleOCR. — [Электронный ресурс]. — Режим доступа: https://github.com/PaddlePaddle/PaddleOCR (дата обращения: 04.06.2026).
- Yandex Vision OCR. — [Электронный ресурс]. — Режим доступа: https://aistudio.yandex.ru/docs/ru/vision/concepts/ocr/index.html (дата обращения: 04.06.2026).
- GPT. — [Электронный ресурс]. — Режим доступа: https://chatgpt.com/ru-RU (дата обращения: 04.06.2026).
- Gemini. — [Электронный ресурс]. — Режим доступа: https://aistudio.google.com/prompts/new_chat (дата обращения: 04.06.2026).

