Цель работы — исследовать, разработать и популяризировать решение обучения оптического распознавания текста на русском языке, с использованием машинного обучения, нейронных сетей и программной роботизации.
В статье описывается проблематика использования распознавания на русском языке, подходы к улучшению машинного обучения с использованием нейронных сетей, и один из новейших примеров обучения на основе RPA (программной роботизации) продуктов отечественной компании PIX Robotics.
Актуальность работы
Практически с самого зарождения такого понятия, как «цифровизация» перед специалистами всего мира встал вопрос о том, как перевести большие массивы информации, зафиксированной на бумаге — в электронный формат.
Было разработано множество решений класса OCR (оптическое распознавание текста), но, как правило, самые качественные решения являются платными разработками иностранных компаний, и их закупка стала затруднена с начала 2022 года. Множество специалистов занялось вопросами эксплуатации свободно-распространяемых OCR-решений. Однако, большинство из них так же являются разработкой иностранных компаний, и как результат — прекрасное распознавание на английском языке (или языке страны производителя решения), и плохой результат для русского языка.
Как правило, большинство решений оптического распознавания текста видит текст с изображений не по заранее запрограммированной логике, а на основании обученных моделей данных. Именно благодаря тому, что моделям данных на других языках отдают больший приоритет, в стандартных поставках модели данных на русском языке имеют недостаточную проработку и дают неудовлетворительный результат.
В данной статье описываются существующие методы обучения моделей данных для OCR-решений, а также собственная технология на основе автоматизации процесса в области программной роботизации.
Изучение проблемы. Существующие решения
На данный момент существует три возможных способа улучшения качества работы оптического распознавания.
Решение 1 — Прямое использование возможностей движка Tesseract
Исходные данные для распознавания — это скан документа в формате *.pdf. Сначала запускается распознавание по документу, далее получаем текстовый результат, оператор (человек) смотрит за качеством распознавания, и если оно не соответствует, то запускает исправление, по средствам внутреннего инструмента корректировки распознавания (запретных символов).
Минусы : это процесс корректировки результатов вручную. Он не дает идеального результата после одной итерации, а лишь помогает справится со сложностями в одном типе документов. Если же изменится печать или подпись на документе, процесс корректировки придется запускать заново.
Как итог, улучшается лишь определенная малая выборка документов.
Решение 2 — Случайная выборка текстов из документов, книг
На случайных выборках уже узнаваемых текстов модель обучится быстрее, и возможность улучшения будет простой. Исходные данные — это документ или картинка, текст которой уже имеется в символьном формате. После процесса распознавания, результат будет сравниваться с эталонным текстом, в случае несоответствия модели будут предоставлены корректировки. Оператору необходимо будет лишь настроить автоматизацию и самозапуск этого решения.
Минусы : это процесс корректировки, так же не даст идеального результата после одной итерации, поможет справится лишь в одном типе документов. Но на этом решении уже не нужно влияние человека, ведь процесс автоматизирован.
Решение 3 — Использование посимвольной раскадровки в обучении
Данный способ базируется на популярном принципе обучения, включая в себя части нейронных технологий. Исходные данные — это большой документ, текст которого имеется в символьном формате.
В случае плохого распознавания, алгоритм или программа пользователя считает изображение документа и разделит его побуквенное представление в виде “A {122,144,166,170}”, где первый символ — это буква после распознавания, далее координаты левого верхнего угла начала буквы, и координаты правого нижнего угла конца буквы. Каждая буква будет показана решению по распознаванию. При следующем запуске, распознавание немного улучшится. Для лучшего результата рекомендуют использовать от нескольких тысяч итераций на один документ.
Минусы : решение сильно завязано на алгоритме обучения. Если в других решениях достаточно оператора, который будет корректировать результат или настраивать автоматизацию, то в этом кейсе необходим программист, который создаст систему раскадровки изображений и генерацию файлов для обучения оптического движка.
Предлагаемое решение
Основным ограничением существующих решений всегда является ограниченность набора данных, и именно эту проблему позволяют решать GPT-модели. Они могут давать текст, максимально приближенный к реальному на разную тематику, при этом каждый раз выдавать что-то новое и уникальное. Таким образом можно формировать изображения с текстом от GPT, проводить его через OCR-решение и сразу же корректировать первоначальным текстом. Этот новый способ обучения базируется на основе сочетания решения № 2 и № 3.
Сложность заключается в том, что, получив такой инструмент, по сути, усложняется процесс, и теперь специалист будет обучать модель дольше.
Но эта проблема решается применением программных роботов. Программные роботы — это такая технология, которая позволяет автоматизировать действия человека за компьютером. Другими словами, можно повторить все те действия по обучению моделей распознавания, которые выполняет профильный специалист.
Самое интересное то, что почти для всех действий в современных решениях программной роботизации есть готовые «активности» (заранее написанные блоки кода, которые просто нужно использовать без написания новых программ).
Алгоритм обучения оптической модели (рисунок 1):
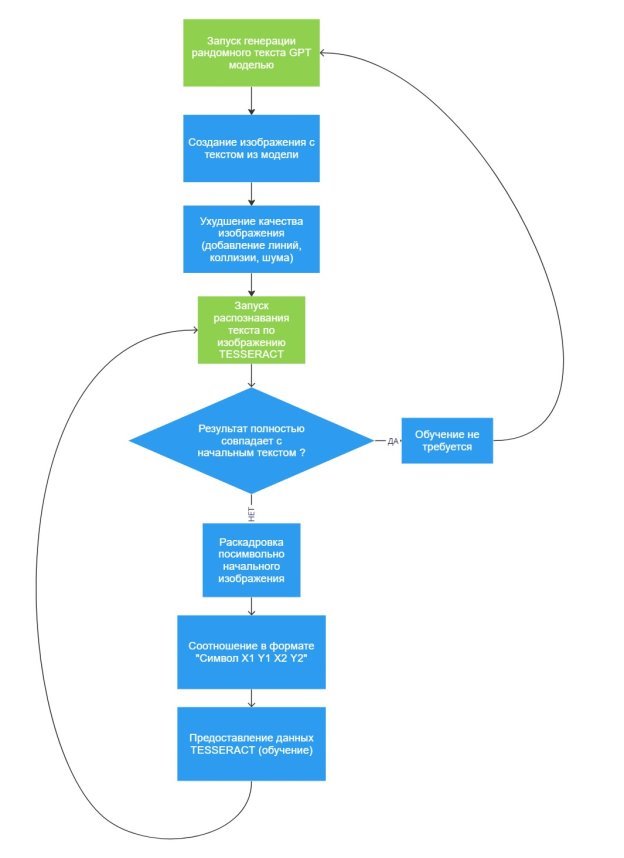
Рис. 1. Алгоритм обучения оптической модели
Рассмотрим построение нашего решения на базе отечественного продукта — PIX RPA, компании PIX Robotics.
В рамках экосистемы решений программной роботизации для создания предлагаемого решения понадобятся:
Studio — программа разработки робота;
Agent — компонент для взаимодействия, который будет отвечать за удаленное контролирование запуска робота;
Master — программа для запуска удаленных роботов.
Этой экосистемы вполне достаточно для реализации всех аспектов обучения оптического распознавания.
Разделим алгоритм робота на несколько составляющих блоков:
1) Блок создания документов для распознавания.
В данном модуле происходит запрос к GPT модели для создания текста образца документа. Результат — текстовое представление выдуманного документа.
Далее происходит копирование в документ и создание скриншота экрана с его последующей обрезкой до формата листа А4.
Затем картинка преобразуется с помощью дополнительных библиотек по ухудшению качества изображений.
2) Блок распознавания
Проверка полученного из модуля 1 изображения на корректность. Робот уже знает текстовое представление результата из GPT модели, необходимо только проверить Tesseract распознавание.
В случае идентичного текста, переходим к блоку 1 и начинаем процесс заново.
В случае ошибок — переходим в блок 3.
3) Блок корректировки
Производим раскадровку картинки текста из модуля 1. Как результат, получается массив из списка побуквенного представления в виде координат левого верхнего угла и правого нижнего.
Сопоставляя каждую координату с символом из оригинального текста GPT модели — получаем список всех символов в формате “Символ X1 Y1 X2 Y2”.
Записываем результаты в файл traineddata для обучения Tesseract.
Запускаем фиксацию результатов через командную строку lstmtraining.
Исходя из этого алгоритма действий, можно построить нескольких программных роботов на базе PIX Studio. Почти 80 % всех нужных действий реализованы в виде активностей. Отсутствующие инструменты можно разработать самостоятельно в виде собственных активностей.
После успешной разработки робота по обучению, необходимо развернуть удаленный стенд и настроить систему на удаленный запуск через связку PIX Agent и PIX Master.
Как итог, мы получаем автоматизированную систему обучения, которая не зависит от оператора и может выполняться круглые сутки, принося результат улучшения распознавания каждую итерацию цикла. С применением роботизации и GPT моделей решаются глобальные проблемы обучения оптического распознавания: уходит необходимость постоянного контроля над процессом высококвалифицированного специалиста. Для этого решения достаточно разработать робота и запустить его автоматическое поднятие в определенный момент времени.
Точки роста решения
Текущее решение позволяет добиться достаточно качественных результатов. Процесс обучения можно настраивать под конкретную фирму, а возможен и общий формат. Но уверен в том, что есть точки роста уже сейчас, и решение будет обновлено и улучшено.
Например:
1) Вариативность тематик для распознавания
2) Использование отечественных GPT-моделей
3) Использование моделей нейронных сетей для генерирования готовых изображений текстов
4) Перенесение решения в закрытый контур, добавление локальной GPT модели.
Заключение
Таким образом, предлагаемое решение позволяет открыть новый виток развития объединенных технологий. Совмещение передовых разработок в области GPT моделей, программных роботов и OCR решений — выдают новый технологический скачок.
Задачи обучения распознавания становятся легко решаемыми для среднего и малого бизнеса. Теперь не нужно искать команду разработки для улучшения технологий, достаточно лишь настроить и автоматизировать предлагаемый процесс.
Литература:
- Пронин К. Н. RPA (Robotic process automatisation) PIX Studio в педагогике основ программирования // Гуманитарные научные исследования. 2023. № 5 (141). 14–20 с.
- Пронин К. Н. Методология проектного обучения на основе принципов разработки программного обеспечения // Гуманитарные научные исследования. 2023. № 7 (143).

