Введение
Волатильность — статистический финансовый показатель, характеризующий изменчивость цены на что-либо. Волатильность в финансах обычно определяется как стандартное отклонение или дисперсия доходности актива за определенный период времени.
Количественно определять степень изменчивости цены важно в трейдинге, волатильность используется везде: от риск-менеджмента до использования в торговых стратегиях, основанных на прогнозировании волатильности.
Революционный прорыв в моделировании волатильности был сделан Робертом Энглом в 1982 году, когда он предложил модель ARCH (Autoregressive Conditional Heteroskedasticity). В модели ARCH условная дисперсия в текущий момент времени представляется как линейная функция квадратов прошлых значений процесса.
Математически модель ARCH(q) можно представить следующим образом:
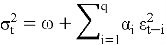
где:
— σ(t)^2 — условная дисперсия в момент времени t;
— ω — константа (обычно положительная);
— α(i) — параметры модели, которые должны быть положительными для обеспечения положительности дисперсии;
— ε(t-i) — инновации процесса (обычно предполагается, что они независимы и одинаково распределены с нулевым средним).
За разработку модели ARCH Роберт Энгл был удостоен Нобелевской премии по экономике в 2003 году, что подчеркивает значимость этого вклада в финансовую эконометрику.
В 1986 году Тим Болерслев предложил обобщение модели ARCH, которое получило название GARCH (Generalized Autoregressive Conditional Heteroskedasticity). Ключевая идея заключалась в том, чтобы включить прошлые условные дисперсии в уравнение для текущей условной дисперсии:
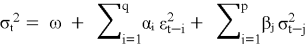
где β(j) — параметры, отражающие влияние прошлых условных дисперсий.
Эта формулировка оказалась более экономной в параметрах и часто модель GARCH(1,1) была достаточна для адекватного описания волатильности, тогда как эквивалентная модель ARCH потребовала бы бесконечного числа параметров.
Модели машинного обучения позволяют обрабатывать огромное количество данных, они используются в том числе и в трейдинге, в частности и в прогнозировании волатильности. Для этого в большинстве случаев используют бустинговые модели машинного обучения, они не требуют слишком много данных как нейронные сети, но при этом их прогнозы не отстают от прогнозов нейросетевых моделей.
Цель данной работы — сравнить точность прогнозов волатильности на 1 шаг вперед на 7 различных активах, используя модели семейства GARCH и модели градиентного бустинга. GARCH модели будут взяты из библиотеки arch, модели градиентного бустинга — из авторской библиотеки dquant. Точность прогнозов будут сравниваться на метриках MAE и QLIKE. Статистическая значимость самых точных моделей будет проверятся на тесте Диболда-Мариано.
1 Методология
1.1 Данные
Данные взяты из python библиотеки yfinance. Для обучения был взят промежуток в 9 лет OHLC данных дневного тайм фрейма. Для валидации — 2 года. Используются следующие активы: BTC-USD (биткоин/доллар), ETH-USD (эфир/доллар), EURUSD=X (евро/доллар), BZ=F (нефть), GC=F (золото), SI=F (серебро), SPY.
Важно использовать разные рынки с разными движениями цен. Например, если уже есть пара евро/доллар, то пару фунт/доллар использовать не обязательно. Из-за сильной корреляции этих двух инструментов, результаты будут похожими.
После получения данных нужно их разделить на тренировочные и валидационные. На тренировочных данных будут обучаться наши модели. Валидационные данные будут использоваться только после обучения. Код на python предоставляется:
START_DATE = '2014-01-01'
SPLIT_DATE = '2023-01-01'
END_DATE = '2024-12-31'
def get_data ( ticker , start_date , end_date ):
print( f"Загрузка {ticker} с {start_date} по {end_date}..." )
raw = yf . download ( ticker , start = start_date , end = end_date , auto_adjust =True)
df = pd . DataFrame ({
'open' : raw [( 'Open' , ticker )]. values ,
'high' : raw [( 'High' , ticker )]. values ,
'low' : raw [( 'Low' , ticker )]. values ,
'close' : raw [( 'Close' , ticker )]. values ,
'volume' : raw [( 'Volume' , ticker )]. values
}, index = raw . index )
return df
df = get_data ( 'BTC-USD' , START_DATE , END_DATE )
train_mask = df . index < SPLIT_DATE
test_mask = df . index >= SPLIT_DATE
df_train = df [ train_mask ]. copy ()
df_test = df [ test_mask ]. copy ()
1.2 Используемые модели их обучение и валидация
1.2.1 Модели машинного обучения
Будут использованы модели машинного обучения XGBoost и LightGBM из python библиотеки DQuant. Эта библиотека представляет удобный интерфейс, для обучения ML моделей для прогноза волатильности, она была создана специально для этого.
Мы будем использовать доходности в качестве входных данных и волатильность Паркинсона в качестве таргетов. Формула волатильности Паркинсона:
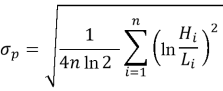
В библиотеке реализован удобный интерфейс для создания признаков и таргетов, но для наглядности мы реализуем эти функции вручную, библиотека позволяет встраивать свои функции для создания признаков и таргетов.
def parkinson_func ( df ):
df = df . copy ()
df = df . iloc [ 1 :]
return np . array ( np . sqrt (
( 1 / ( 4 * np . log ( 2 ))) * ( np . log ( df [ 'high' ] / df [ 'low' ]))** 2
))
def return_func ( df ):
return np . array ( df [ 'close' ]. pct_change (). dropna ())
Встраиваем эти функции в код обучения модели:
from dquant . models import VolClustXGB , VolClustLightGBM
def dquant_xgb_train ():
model_dq = VolClustXGB ({}, early_stopping =True, output =False)
model_dq . fit (
df_train ,
feature_list = FEATURES ,
input_bars = INPUT_BARS ,
horizon = HORIZON ,
trees_count = TREES_COUNT ,
show_results =False,
feature_func = return_func ,
target_func = parkinson_func
)
return model_dq
Библиотека по умолчанию использует функцию потерь QLIKE, которая была создана специально для обучения прогнозировать волатильность.
Обучение проводилось с гиперпараметрами по умолчанию. Для XGBoost это:
{
'learning_rate' : 0.1 ,
'max_depth' : 6 ,
'min_child_weight' : 5 ,
'gamma' : 0.1 ,
'subsample' : 0.8 ,
'colsample_bytree' : 0.8 ,
'reg_alpha' : 0.0 ,
'reg_lambda' : 1.0 ,
'random_state' : 42 ,
'tree_method' : 'hist' ,
'device' : 'cpu'
}
Для LightGBM:
{
'learning_rate' : 0.1 ,
'max_depth' : 6 ,
'num_leaves' : 2 ** 6 - 1 ,
'min_child_samples' : 5 ,
'min_split_gain' : 0.1 ,
'bagging_fraction' : 0.8 ,
'bagging_freq' : 1 ,
'feature_fraction' : 0.8 ,
'reg_alpha' : 0.0 ,
'reg_lambda' : 1.0 ,
'random_state' : 42 ,
'verbosity' : - 1 ,
'boosting_type' : 'gbdt'
}
Оптимальное количество деревьев подбирается в процессе обучения.
Код для получения прогнозов модели:
def dquant_xgb_forecasting ():
model_dq = dquant_xgb_train ()
dquant_preds = []
dquant_dates = []
for i in range( INPUT_BARS , len( df_test )):
test_date = df_test . index [ i ]
available_data = df . loc [: test_date ]. iloc [- INPUT_BARS :]. copy ()
if len( available_data ) < INPUT_BARS :
continue
try:
forecast_vals = model_dq . forecast ( available_data , show =False)
pred_vol = forecast_vals [- 1 ] if HORIZON > 1 else forecast_vals [ 0 ]
except Exception as e :
print( f"Ошибка прогноза DQuant на {test_date . date () }: {e}" )
continue
actual_vol = df_test . loc [ test_date , 'parkinson_vol' ]
dquant_dates . append ( test_date )
dquant_preds . append ({
'date' : test_date ,
'actual' : actual_vol ,
'predicted' : pred_vol
})
df_dquant = pd . DataFrame ( dquant_preds ). set_index ( 'date' )
return df_dquant
Все то же самое нужно сделать и с VolClustLightGBM
1.2.2 Модели условной гетероскедастичности
Будут использованы модели условной гетероскедастичности: GARCH(1,1), EGARCH(1,1), GJR-GARCH(1,1) из python библиотеки arch.
GARCH (Generalized Autoregressive Conditional Heteroskedasticity) — модель условной гетероскедастичности.
Формула выглядит следующим образом:
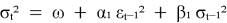
Где:
—
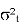
—
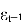
—
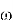
—
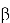
—
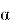
Реализация в python:
def garch_forecasting ():
garch_preds = []
returns_full = df [ 'returns' ]. dropna () * 100 # масштабирование для GARCH
for test_date in df_test . index :
hist_returns = returns_full [: test_date ]. iloc [:- 1 ]
if len( hist_returns ) < 500 :
continue
try:
model_garch = arch_model ( hist_returns , vol = 'GARCH' , p = 1 , q = 1 , dist = 'normal' )
fitted = model_garch . fit ( disp = 'off' )
forec = fitted . forecast ( horizon = HORIZON , reindex =False)
cond_var = forec . variance . values [- 1 , 0 ]
pred_vol = np . sqrt ( cond_var ) / 100.0 # обратное масштабирование
except Exception as e :
print( f"Ошибка GARCH на {test_date . date () }: {e}" )
continue
actual_vol = df . loc [ test_date , 'parkinson_vol' ]
garch_preds . append ({
'date' : test_date ,
'actual' : actual_vol ,
'predicted' : pred_vol
})
df_garch = pd . DataFrame ( garch_preds ). set_index ( 'date' )
return df_garch
EGARCH (Exponential GARCH) — модификация GARCH, которая учитывает асимметричные эффекты волатильности.
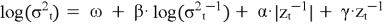
Где:
—
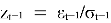
—
—
—
—
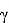
Код будет тот же самый, кроме кода самой модели:
model_garch = arch_model ( hist_returns , vol = 'EGARCH' , p = 1 , q = 1 , dist = 'normal' )
GJR-GARCH — еще одна модель для асимметричных эффектов, названная в честь ее авторов (Glosten, Jagannathan, и Runkle).
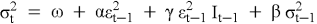
Где:
—
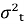
—
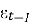
—
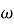
— β — коэффициент персистентности;
— α — влияние величины шока;
—
—
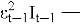
Код будет тот же самый, кроме кода самой модели:
model_garch = arch_model ( hist_returns , vol = 'GARCH' , p = 1 , q = 1 , o = 1 , dist = 'normal' )
o=1 добавляет эффект GJR-GARCH.
Библиотека берет реализацию всей математики на себя.
1.3 Метрики
Использованы метрики качества Mean Absolute Error (MAE) и Quasi-Likelihood (QLIKE).
Mean Absolute Error (MAE) — это метрика оценки качества моделей регрессии, вычисляемая как среднее арифметическое абсолютных значений ошибок (разностей между предсказанными и реальными значениями).
Формула:
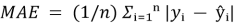
Где:
—
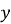
—
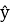
Она будет взята из python библиотеки scikit-learn:
from sklearn . metrics import mean_absolute_error
Quasi-Likelihood (QLIKE) — метрика, созданная специально для оценки прогнозов волатильности.
Формула:
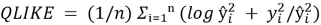
Где:
—
—
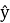
В scikit-learn нет такой функции, поэтому она будет реализована вручную:
def qlike ( y_true , y_pred ):
sigma2_true = y_true ** 2
sigma2_pred = np . maximum ( y_pred ** 2 , 1e-10 )
return np . mean ( np . log ( sigma2_pred ) + sigma2_true / sigma2_pred )
1.4 Тест
После выявления самых точных моделей машинного обучения и условной гетероскедастичности, сравним результаты их прогнозов на тесте Диболда-Мариано, для выявления статистического превосходства в прогнозах какой-либо из моделей.
Тест Диболда-Мариано используется для определения на сколько сильно отличаются 2 прогноза. Для начала мы вычисляем ряд ошибок. Для MAE:
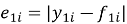
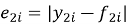
Для QLIKE:
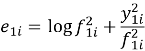
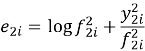
Где:
— e — ряд ошибок
— y — ряд истинных значений
— f — ряд прогнозов
Далее мы вычисляем разницу в потерях между двумя рядами.
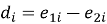
Если разница в потерях
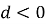
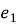
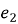
Так как у нас прогноз на 1 шаг вперед, то учитывать автокорреляцию не обязательно.
Формула теста без учета автокорреляции:
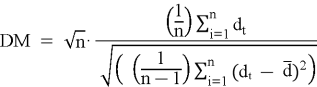
Вычисляем p-value:
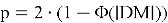
Где
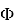
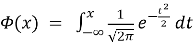
Код:
def dm_test(d):
n = len (d)
mean_d = np. mean (d)
var_d = np. var (d)
dm_stat = np. sqrt (n) * mean_d / np. sqrt (var_d)
p_value = 2 * (1 - stats. norm . cdf (np. abs (dm_stat)))
return dm_stat, p_value
err_dq = abs( the_best_dquant_aligned [ 'actual' ] - the_best_dquant_aligned [ 'predicted' ])
err_garch = abs( the_best_garch_aligned [ 'actual' ] - the_best_garch_aligned [ 'predicted' ])
d = err_dq - err_garch
dm_stat , p_value = dm_test ( d )
dquant_sigma2_true = the_best_dquant_aligned_qlike [ 'actual' ]** 2
dquant_sigma2_pred = np . maximum ( the_best_dquant_aligned_qlike [ 'predicted' ]** 2 , 1e-10 )
garch_sigma2_true = the_best_garch_aligned_qlike [ 'actual' ]** 2
garch_sigma2_pred = np . maximum ( the_best_garch_aligned_qlike [ 'predicted' ]** 2 , 1e-10 )
err_dq = np . log ( dquant_sigma2_pred ) + dquant_sigma2_true / dquant_sigma2_pred
err_garch = np . log ( garch_sigma2_pred ) + garch_sigma2_true / garch_sigma2_pred
d = err_dq - err_garch
dm_stat_qlike , p_value_qlike = dm_test ( d )
print( f"\n========== РЕЗУЛЬТАТЫ {i} ==========" )
print( f"По результатам MAE, для {i} лучшая GARCH модель – {the_best_garch}, лучшая DQuant модель – {the_best_dquant}" )
print( f"MAE DM-тест: статистика = {dm_stat:.4f}, p-value = {p_value}" )
if p_value < 0.05 :
print( "Различие статистически значимо." )
else:
print( "Различие не является статистически значимым." )
print( f"По результатам QLIKE, для {i} лучшая GARCH модель – {the_best_garch_qlike}, лучшая DQuant модель – {the_best_dquant_qlike}" )
print( f"QLIKE DM-тест: статистика = {dm_stat_qlike:.4f}, p-value = {p_value_qlike}" )
if p_value_qlike < 0.05 :
print( "Различие статистически значимо." )
else:
print( "Различие не является статистически значимым." )
1.5 Код
Весь исходный код есть на GitHub https://github.com/artrdon/DQuant_Research.
2 Результаты
Таблица 1
Сравнение MAE и QLIKE для BTC-USD
|
BTC-USD |
MAE |
QLIKE |
|
XGBoost |
0.00881 |
-6.45633 |
|
LightGBM |
0.00914 |
-6.45437 |
|
GARCH |
0.01289 |
-6.34743 |
|
EGARCH |
0.01323 |
-6.33964 |
|
GJR-GARCH |
0.01277 |
-6.35053 |
Результаты BTC-USD
По результатам MAE, для BTC-USD лучшая GARCH модель — GJR-GARCH, лучшая DQuant модель — XGBoost
MAE DM-тест: статистика = -14.6092, p-value = 0.0
Различие статистически значимо.
По результатам QLIKE, для BTC-USD лучшая GARCH модель — GJR-GARCH, лучшая DQuant модель — XGBoost
QLIKE DM-тест: статистика = -3.6280, p-value = 0.0002856594612836716
Различие статистически значимо.
Таблица 2
Сравнение MAE и QLIKE для ETH-USD
|
ETH-USD |
MAE |
QLIKE |
|
XGBoost |
0.00998 |
-6.21683 |
|
LightGBM |
0.00977 |
-6.16085 |
|
GARCH |
0.01531 |
-6.01800 |
|
EGARCH |
0.01463 |
-6.05071 |
|
GJR-GARCH |
0.01536 |
-6.01689 |
Результаты ETH-USD
По результатам MAE, для ETH-USD лучшая GARCH модель — EGARCH, лучшая DQuant модель — LightGBM
MAE DM-тест: статистика = -14.1022, p-value = 0.0
Различие статистически значимо.
По результатам QLIKE, для ETH-USD лучшая GARCH модель — EGARCH, лучшая DQuant модель — XGBoost
QLIKE DM-тест: статистика = -6.1102, p-value = 9.951197643687237e-10
Различие статистически значимо.
Таблица 3
Сравнение MAE и QLIKE для EURUSD=X
|
EURUSD=X |
MAE |
QLIKE |
|
XGBoost |
0.00113 |
-10.24095 |
|
LightGBM |
0.00109 |
-10.21435 |
|
GARCH |
0.00140 |
-10.21536 |
|
EGARCH |
0.00144 |
-10.20877 |
|
GJR-GARCH |
0.00139 |
-10.21929 |
Результаты EURUSD=X
По результатам MAE, для EURUSD=X лучшая GARCH модель — GJR-GARCH, лучшая DQuant модель — LightGBM
MAE DM-тест: статистика = -7.2213, p-value = 5.151434834260726e-13
Различие статистически значимо.
По результатам QLIKE, для EURUSD=X лучшая GARCH модель — GJR-GARCH, лучшая DQuant модель — XGBoost
QLIKE DM-тест: статистика = -1.1875, p-value = 0.23501267123755953
Различие не является статистически значимым.
Таблица 4
Сравнение MAE и QLIKE для BZ=F
|
BZ=F |
MAE |
QLIKE |
|
XGBoost |
0.00505 |
-7.21600 |
|
LightGBM |
0.00486 |
-7.20959 |
|
GARCH |
0.00588 |
-7.19007 |
|
EGARCH |
0.00627 |
-7.17082 |
|
GJR-GARCH |
0.00601 |
-7.18410 |
Результаты BZ=F
По результатам MAE, для BZ=F лучшая GARCH модель — GARCH, лучшая DQuant модель — LightGBM
MAE DM-тест: статистика = -5.5995, p-value = 2.149568145703995e-08
Различие статистически значимо.
По результатам QLIKE, для BZ=F лучшая GARCH модель — GARCH, лучшая DQuant модель — XGBoost
QLIKE DM-тест: статистика = -2.0917, p-value = 0.03646399315082749
Различие статистически значимо.
Таблица 5
Сравнение MAE и QLIKE для GC=F
|
GC=F |
MAE |
QLIKE |
|
XGBoost |
0.00282 |
-8.82288 |
|
LightGBM |
0.00281 |
-9.03464 |
|
GARCH |
0.00454 |
-8.94346 |
|
EGARCH |
0.00473 |
-8.92604 |
|
GJR-GARCH |
0.00454 |
-8.94765 |
Результаты GC=F
По результатам MAE, для GC=F лучшая GARCH модель — GARCH, лучшая DQuant модель — LightGBM
MAE DM-тест: статистика = -13.1531, p-value = 0.0
Различие статистически значимо.
По результатам QLIKE, для GC=F лучшая GARCH модель — GJR-GARCH, лучшая DQuant модель — LightGBM
QLIKE DM-тест: статистика = -1.0400, p-value = 0.2983307176417702
Различие не является статистически значимым.
Таблица 6
Сравнение MAE и QLIKE для SI=F
|
SI=F |
MAE |
QLIKE |
|
XGBoost |
0.00567 |
-7.32094 |
|
LightGBM |
0.00567 |
-6.85470 |
|
GARCH |
0.01110 |
-7.67624 |
|
EGARCH |
0.01156 |
-7.63753 |
|
GJR-GARCH |
0.01112 |
-7.67493 |
Результаты SI=F
По результатам MAE, для SI=F лучшая GARCH модель — GARCH, лучшая DQuant модель — LightGBM
MAE DM-тест: статистика = -13.1855, p-value = 0.0
Различие статистически значимо.
По результатам QLIKE, для SI=F лучшая GARCH модель — GARCH, лучшая DQuant модель — XGBoost
QLIKE DM-тест: статистика = 1.7410, p-value = 0.08168060171995584
Различие не является статистически значимым.
Таблица 7
Сравнение MAE и QLIKE для SPY
|
SPY |
MAE |
QLIKE |
|
XGBoost |
0.00189 |
-9.26830 |
|
LightGBM |
0.00175 |
-9.11701 |
|
GARCH |
0.00307 |
-9.10276 |
|
EGARCH |
0.00324 |
-9.08008 |
|
GJR-GARCH |
0.00295 |
-9.13928 |
Результаты SPY
По результатам MAE, для SPY лучшая GARCH модель — GJR-GARCH, лучшая DQuant модель — LightGBM
MAE DM-тест: статистика = -9.3965, p-value = 0.0
Различие статистически значимо.
По результатам QLIKE, для SPY лучшая GARCH модель — GJR-GARCH, лучшая DQuant модель — XGBoost
QLIKE DM-тест: статистика = -4.9066, p-value = 9.269222227548113e-07
Различие статистически значимо.
Заключение
В данном исследовании было проведено сравнение моделей условной гетероскедастичности, взятых из библиотеки arch и моделей машинного обучения из библиотеки dquant на 7 различных финансовых инструментах.
На тесте Диболда-Мариано, при использовании MAE в качестве функции потерь, модели градиентного бустинга показали статистически значимое преимущество на всех активах. Это показывает, что модели машинного обучения, в частности градиентного бустинга, могут улавливать нелинейные зависимости, которые не замечают модели семейства GARCH.
При использовании QLIKE в качестве функции потерь на тесте, статистическое преимущество было выявлено на 4 из 7 активах. На SI=F не было выявлено статистически значимого преимущества, но GARCH показал результаты лучше нежели XGBoost. На других активах модели DQuant показали результаты лучше моделей семейства GARCH.
Сравнение проводилось на дневных данных, результаты могут отличаться, если брать внутридневные данные.
Не проводилась оптимизация гиперпараметров градиентного бустинга, точность прогнозов моделей машинного обучения может быть выше, если использовать оптимальные гиперпараметры.
Не проводилась walk forward валидация, вместо этого было статическое разделение данных на тренировочные и валидационные выборки.
Литература:
- https://github.com/artrdon/dquant
- https://mlgu.ru/1778/?utm_source=yandex&utm_medium=organic
- https://real-statistics.com/time-series-analysis/forecasting-accuracy/diebold-mariano-test/
- https://elma365.com/ru/baza-znaniy/mse/
- https://public.econ.duke.edu/~ap172/Patton_vol_proxies_JoE_2011.pdf
- https://mlgu.ru/6807/?utm_source=yandex&utm_medium=organic
- https://blog.quantinsti.com/garch-gjr-garch-volatility-forecasting-python/
- https://ru.wikipedia.org/wiki/Волатильность
- https://public.econ.duke.edu/~boller/Published_Papers/joe_86.pdf

