The article examines speech analysis tools — Praat and Librosa. Measures of quality like microphone sensitivity, sampling frequency and signal/noise ratio are considered. Ways to implement abovementioned tools, and their usage, are considered. Metrics analyzed by these tools are presented. The measurement speed and correlation between the tools for these metrics are evaluated. Based on these results, use cases for Praat and Librosa for analyzing speech, as well as minimum quality metric thresholds for speech analysis, are proposed.
Keywords: speech processing, sampling frequency, sensitivity, fundamental frequency, Mel-frequency cepstrum coefficients.
Такие средства, как Praat и Librosa, могут применяться для описания параметров голоса для использования в сравнении, в том числе в целях распознавания говорящего или распознавания патологии голоса [1–3]. Целью данной работы является исследование возможности целесообразности использования тех или иных программных средств. В рамках этой цели задачами данной работы являются проведение оценки скорости и соответствия результатов этих средств, а также обсуждаются показатели качества аудиозаписей, проверка которых необходима перед их анализом для возможного уменьшения неточностей анализа.
Одним из факторов, влияющих на звукозапись, является чувствительность микрофона. Чувствительность микрофона можно определить как уровень выходного сигнала при подаче некоторого входного эталонного (с частотой 1 кГц и уровнем звукового давления 94 дБ). Широко используются логарифмические единицы чувствительности дБ*В, которые определяются как отношение выходного напряжения в вольтах данного микрофона при подаче на него эталонного сигнала в сравнении с эталонным выходным напряжением в 1 В [4]. В общем случае, микрофоны имеют отрицательную чувствительность, то есть выходное напряжение меньше 1 В. Следовательно, чем меньше по модулю чувствительность рассматриваемого микрофона, тем больше считается его чувствительность. Чувствительность — существенный фактор, поскольку, хоть сигнал и возможно усилить, шум в этом случае также усиливается [5]. Существуют рекомендации к чувствительности микрофона не менее -60 дБ [5]. Тем не менее, устройства с различной чувствительностью пригодны для работы в различных условиях: устройства с большой чувствительностью пригодны в условиях, где звукозапись должна осуществляться с больших расстояний; при использовании подобного устройства на небольших расстояниях входной сигнал может достигнуть максимального уровня, определяемого чувствительностью, и может произойти искажение сигнала [4].
Частота дискретизации определяется как число дискретных значений в секунду, которыми представляется сигнал при оцифровывании. Эта частота должна быть, по меньшей мере, вдвое выше, чем самая высокая интересующая частота [6]. Так как частоты, отвечающие за разборчивость речи, сконцентрированы в основном в диапазоне 300 и 3400 Гц, считается, что речь человека при частоте дискретизации 8 кГц различима [7]. В работе [6] запись проводилась при частоте дискретизации 44.1 кГц с различными видами шума. Затем проводилось уменьшение частоты дискретизации до частоты в промежутке от 40 кГц до 10 кГц с шагом в 5 кГц. Результаты этого исследования показали, что, в зависимости от программного обеспечения, используемого для обработки сигнала, достаточна частота дискретизации в 26 кГц.
Есть факторы, зависящие не от используемых технических средств, а от среды, в которой находится записывающее устройство. В работе [5] из этих факторов рассматриваются расстояние микрофона от источника сигнала и угловую ориентацию микрофона. Сигнал в проводимых опытах генерировался на частотах 100 и 300 Гц, с отсутствием модуляций и при модуляциях частоты и амплитуды сигнала. Результаты опытов показывают, что ключевой из этих факторов — расстояние до микрофона. При небольших расстояниях (4 см) расхождения между заданной модуляцией и модуляцией, полученной из выходных записей микрофонов достаточно малы, тогда как при больших расстояниях (1 м) потребовалось значительное усиление входного сигнала, что привело к уменьшению отношения сигнал/шум и упомянутые расхождения значительно увеличились. При этом угол наклона микрофона к источнику сигнала оказал значительное влияние только в опытах на больших расстояниях. При увеличениях угла полученные меры модуляции были получены завышенные.
Такие факторы, как электромагнитные помехи, влажность, температура, механические колебания и т. д. также могут оказывать влияние на записывающие устройства, в особенности достаточно дешевые [8].
Различного рода шумы также могут мешать восприятию полезного сигнала. Существует отношение сигнал/шум, определяющееся по формуле (1) с использованием логарифмической шкалы и, соответственно, выражающееся в дБ.
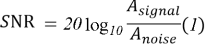
где:
SNR — отношение сигнал/шум;
А signal — среднеквадратичное значение амплитуды полезного сигнала;
А noise — среднеквадратичное значение амплитуды шума.
В работе [9] указываются рекомендованное и необходимое отношение сигнал/шум для качественной записи звука как 42 дБ и 30 дБ соответственно. Это высокие требования, предполагающие такой разности уровня звукового давления между шумом и сигналом. В связи с этим предпочтительно производить запись, в среде с наименьшим возможным уровнем шума. В условиях сильного шума использование более широкодоступных устройств поэтому может оказаться недостаточным и может потребоваться записывающее устройство, имеющее внутреннее шумоподавление.
Для анализа речевого сигнала возможно использование мел-кепстральных коэффициентов [7], получаемых с помощью быстрого преобразования Фурье или изображений, содержащих спектрограммы [10], помимо этого, в качестве отличительного признака речевого сигнала возможно использовать частоту основного тона [3, 7]. В Praat существует собственный сценарный язык. Этот язык позволяет открывать аудиозапись, читать аудиофайлы и текстовые файлы, записывать информацию в текстовые файлы. Praat возможно запускать и оперировать им из командной строки (и таким же образом возможно исполнение сценариев Praat), что позволяет интегрировать Praat в программные комплексы. Librosa является библиотекой Python, использующей также библиотеку numpy и matplotlib. Это подразумевает существование возможность взаимодействовать с текстовыми файлами, аудиофайлами с использованием Librosa. Для тестирования скорости и соответствия результатов работы программных средств была написана программа для каждого из тестируемых средств, позволяющая вывести в файл или несколько файлов 12 мел-кепстральных коэффициентов для преобразования Фурье с размером окна 4096 сэмплов и шагом в 16 сэмплов при частоте дискретизации 48000 Гц, а также среднюю частоту основного тона для 10 тестовых записей. В рамках проведения теста соответствия результатов был вычислен коэффициент корреляции Спирмена для вычисленных частот основного тона.
Было установлено, что время работы сценария Praat составило 21 секунду; время работы программы Python с использованием библиотеки Librosa составило 9.4 секунды. Несмотря на обработку небольшого количества записей (10) время работы обоих программ существенно вследствие необходимости вычисления и вывода мел-кепстральных коэффициентов по всем шагам вычисления, общее количество которых имеет порядок 104 в условиях данного теста. Полученный коэффициент Спирмена равен 0.757; p-значение равно 0.01123. При р-значении меньшим либо равным 0.05 можно сделать вывод о том, что статистическая взаимосвязь между двумя исследуемыми величинами (вычисленными частотами основного тона) существенна.
Такие показатели, как чувствительность микрофона, частота дискретизации и отношение сигнал/шум могут быть использованы для оценки качества используемых аудиозаписей и записывающих устройств. Существуют некоторые рекомендуемые показатели, такие как чувствительность -60 дБ или выше [5], частота дисретизации в 26 кГц или выше [6] отношение сигнал/шум в 42 дБ [9]. По результатам проделанных тестов над Praat и Librosa видно, что использование Praat и Librosa возможно для исследования параметров голоса ввиду возможности их интеграции, а также наличии статистической взаимосвязи между вычисленными ими частотами основного тона. Тем не менее, использование этих средств в условиях, представленных ранее, может не являться целесообразным для практических целей ввиду траты существенного количества времени (~101 секунд) и, таким образом, является более приемлемым для исследования речи в лабораторных условиях.
Литература:
- Teixeira J. P., Gonçalves A. Algorithm for jitter and shimmer measurement in pathologic voices //Procedia Computer Science. — 2016. — Т. 100. — С. 271–279.
- Azadi H. et al. Evaluating the effect of Parkinson's disease on jitter and shimmer speech features //Advanced Biomedical Research. — 2021. — Т. 10. — №. 1. — С. 54.
- Fernandes J. et al. Harmonic to noise ratio measurement-selection of window and length //Procedia computer science. — 2018. — Т. 138. — С. 280–285.
- Льюис Д. Чувствительность микрофона-что это значит? //Компоненты и технологии. — 2012. — №. 9. — С. 57–60.
- Titze I. R., Winholtz W. S. Effect of microphone type and placement on voice perturbation measurements //Journal of Speech, Language, and Hearing Research. — 1993. — Т. 36. — №. 6. — С. 1177–1190.
- Deliyski D. D., Shaw H. S., Evans M. K. Influence of sampling rate on accuracy and reliability of acoustic voice analysis //Logopedics Phoniatrics Vocology. — 2005. — Т. 30. — №. 2. — С. 55–62.
- Сулавко А. Е. Высоконадёжная двухфакторная биометрическая аутентификация по рукописным и голосовым паролям на основе гибких нейронных сетей. Компьютерная оптика , 2020, Т. 44, №. 1, с. 82–91.
- Deliyski D. D., Evans M. K., Shaw H. S. Influence of data acquisition environment on accuracy of acoustic voice quality measurements //Journal of Voice. — 2005. — Т. 19. — №. 2. — С. 176–186.
- Deliyski D. D., Shaw H. S., Evans M. K. Adverse effects of environmental noise on acoustic voice quality measurements //Journal of Voice. — 2005. — Т. 19. — №. 1. — С. 15–28.
- Lukic Y. et al. Speaker identification and clustering using convolutional neural networks. 2016 IEEE 26th international workshop on machine learning for signal processing (MLSP) , IEEE, 2016, pp. 1–6.

