Введение
Инфраструктуры больших данных долгое время строились вокруг хранилищ, вычислительных движков, ETL-процессов и специализированных аналитических инструментов. В такой архитектуре основной гарантией надежности выступали формальные элементы: схема данных, типы, ограничения, SQL-запросы, регламенты качества и заранее описанные метрики. Появление больших языковых моделей изменило не саму природу данных, а способ взаимодействия аналитика с ними: всё чаще работа начинается не с готового запроса, а с естественно-языкового намерения, которое затем должно быть переведено в формальную процедуру.
В современной литературе это направление описывается через связку LLM4Data и Data4LLM. Первая линия относится к применению больших языковых моделей для управления, очистки, поиска, интерпретации и анализа данных; вторая — к использованию методов управления данными для подготовки, обслуживания и инференса самих моделей [1]. Близкую по смыслу рамку задает данно-центричный искусственный интеллект: в нем качество, жизненный цикл и сопровождаемость данных рассматриваются не как второстепенное условие, а как самостоятельный предмет проектирования [2].
При этом LLM нельзя рассматривать как новое универсальное ядро аналитики. Работы по применению крупных языковых моделей в управлении данными показывают, что они полезны там, где требуется перевод между представлениями: текстом, таблицей, схемой, программным кодом, запросом и объяснением результата [3], [4]. Но в задачах строгого вычисления, контроля типов, соблюдения схемы и воспроизводимости модель должна опираться на внешние инструменты исполнения и проверки.
Цель статьи состоит в том, чтобы систематизировать роли LLM в конвейере больших данных и предложить простую теоретическую модель их применения. В статье не утверждается, что языковые модели способны заменить классические средства анализа. Напротив, основной тезис состоит в другом: наибольшую ценность LLM дают тогда, когда встроены в управляемый контур, где генерация отделена от верификации, а итоговый результат может быть проверен формальными средствами.
Концептуальная рамка LLM4Data и Data4LLM
Пара LLM4Data / Data4LLM удобна тем, что не смешивает две разные стороны одной проблемы. LLM4Data отвечает на вопрос, как языковые модели могут помогать при работе с данными: понимать таблицы, предлагать варианты очистки, связывать пользовательский вопрос со схемой, формировать SQL-запрос, описывать результат и готовить документацию. Data4LLM, в свою очередь, отвечает на вопрос, какие данные, индексы, контекст, кэши, векторные базы и контуры сервинга нужны для устойчивой работы самих моделей [1], [4].
Смысл такой рамки особенно заметен на табличных и схемо-ориентированных задачах. Исследования по обработке таблиц показывают, что LLM способны работать с табличными структурами, но их ответы чувствительны к способу представления таблицы, порядку полей, сериализации и полноте контекста [5], [6]. Поэтому табличная аналитика с участием LLM требует не только сильной модели, но и аккуратной подготовки схемы, метаданных и проверочных правил. Отдельные работы по задачам над таблицами прямо показывают, что использование LLM в таких сценариях становится самостоятельным направлением, а не частным случаем обычной обработки текста [7].
Отдельное место занимает Text-to-SQL — перевод естественно-языкового вопроса в формальный запрос к базе данных. Обзоры по этой теме фиксируют быстрый рост качества LLM-подходов, но одновременно подчеркивают зависимость результата от schema linking, примеров, подсказок и постпроверки [8]. Экспериментальные оценки показывают, что даже сильные модели могут давать синтаксически правдоподобные, но семантически неверные запросы, если контекст схемы неполон или бизнес-правила не зафиксированы явно [9].
В задачах очистки данных и подготовки признаков LLM полезны не столько как автоматический исполнитель, сколько как генератор гипотез. Они могут предлагать контекстные правила, восстанавливать неоднозначные значения, подсказывать преобразования и помогать в feature engineering [10], [11], [12]. Однако любое такое предложение должно проходить через формальные ограничения, тесты, журналирование изменений и, в спорных случаях, проверку человеком.
Еще одна линия исследований связана с документацией и прозрачностью наборов данных. Подходы Datasheets for Datasets и Data Cards показывают, что датасет должен сопровождаться сведениями о происхождении, составе, ограничениях, допустимых сценариях использования и возможных рисках [13], [14]. Языковые модели способны ускорить подготовку таких описаний, но не могут сами быть окончательным источником ответственности. Более поздние обзоры инструментов документации также показывают, что главная сложность состоит не только в написании текста, но и во встраивании документации в рабочий процесс [15].
Наконец, LLM заметно усиливают слой объяснения результатов. Исследования по data-to-text generation рассматривают преобразование структурированных данных в связное текстовое описание как отдельную задачу [16]. В прикладных сценариях вроде анализа логов языковые модели используются не только для обнаружения аномалий, но и для объяснения возможных причин их появления [17]. В более широком виде эта логика ведет к инструментально-усиленным LLM и агентным системам, где модель планирует действия, вызывает внешние инструменты, анализирует промежуточные результаты и передает итог человеку [18], [19].
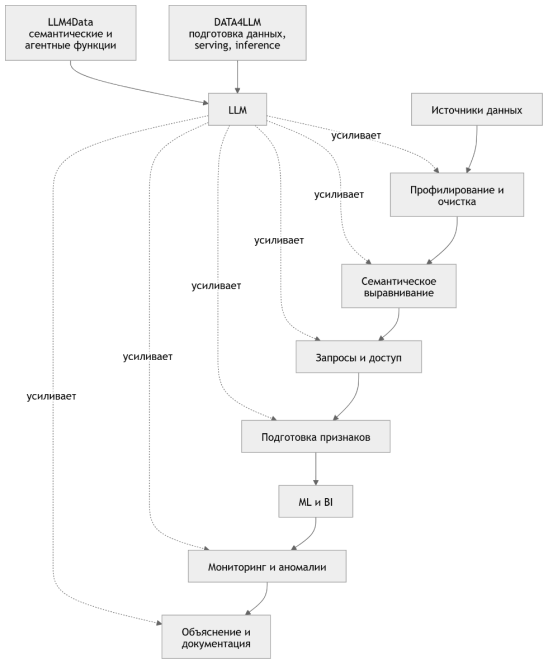
Рис. 1. Общая логика применения LLM в конвейере больших данных
Авторская классификация ролей LLM
Для описания места LLM в аналитическом pipeline предлагается не инструментальная, а функциональная классификация. Она исходит из того, на какой объект воздействует модель: сырые данные, схему, пользовательский вопрос, вычислительный результат или итоговый аналитический текст. По этому признаку можно выделить пять ролей.
Первая роль — ассистент очистки. В этой роли LLM помогают выявлять пропуски, дубли, неоднозначные категории, противоречивые единицы измерения и контекстные ошибки. Их ценность состоит в способности учитывать не только статистику распределений, но и смысловое окружение записи. В то же время именно здесь особенно опасны тихие ошибки: правдоподобная, но неверная правка может перейти во все последующие стадии анализа [10], [11]. Поэтому ассистент очистки должен предлагать варианты исправления, но не заменять проверяемую процедуру изменения данных.
Вторая роль — семантический интерпретатор. Она нужна там, где схема бедно описана, названия полей неполны, а источники содержат сочетание таблиц, кодов, текстов и доменных терминов. LLM может помочь связать формальную структуру с предметным смыслом: предложить описание поля, вероятный тип сущности, связь между таблицами или ограничение использования датасета. Но такая интерпретация должна подтверждаться владельцами данных и метаданными, иначе она превращается в догадку, оформленную как уверенное объяснение [5], [6], [13], [14].
Третья роль — агент генерации запросов. В этом режиме LLM переводит вопрос пользователя в SQL, NL2Viz-команду или другой формальный язык доступа. Эта роль особенно заметна в BI-сценариях, где необходимо снизить порог входа для пользователей, не владеющих языком запросов. Однако запрос, созданный LLM, должен исполняться в контролируемой среде и проверяться на соответствие схеме, правам доступа и допустимым агрегациям [8], [9].
Четвертая роль — контролер качества. В отличие от предыдущих ролей, она не столько создает новый артефакт, сколько проверяет уже полученный: сопоставляет текстовый вывод с агрегатами, ищет противоречия в рассуждении, проверяет типы и ограничения, требует повторного запуска инструмента и фиксирует происхождение результата. Эта роль принципиальна, потому что исследования по оценке LLM и галлюцинациям показывают: убедительная форма ответа не является доказательством его корректности [20], [21].
Пятая роль — интерпретатор результатов. Здесь LLM превращает таблицу, график, лог, набор метрик или результат модели в понятное объяснение для исследователя, руководителя или аудитора. Такая роль полезна при подготовке отчетов, пояснении аномалий и документировании выводов. Но и в этом случае текст должен быть привязан к исходным числам: языковая модель не должна свободно достраивать причины там, где данные показывают только корреляцию или описание [16], [17].
Матрицы применения ролей
Первую матрицу удобно построить по этапам аналитического pipeline. Она показывает, где роль LLM является основной, где вспомогательной, а где её использование допустимо только эпизодически. Важно, что одна роль может сопровождать несколько этапов, а один этап может включать несколько ролей.
Таблица 1
Матрица соответствия ролей LLM этапам аналитического pipeline
|
Этап |
Оч. |
Сем. |
Запр. |
Контр. |
Интерпр. |
|
Получение и профилирование |
△ |
○ |
— |
○ |
— |
|
Очистка и нормализация |
◎ |
○ |
— |
◎ |
— |
|
Семантическое выравнивание схем и метаданных |
○ |
◎ |
○ |
○ |
△ |
|
Доступ к данным и BI-запросы |
— |
○ |
◎ |
○ |
○ |
|
Подготовка признаков |
○ |
○ |
△ |
○ |
— |
|
ML-этап и оценка результатов |
— |
△ |
△ |
◎ |
○ |
|
Мониторинг и анализ аномалий |
○ |
○ |
— |
◎ |
◎ |
|
Объяснение, отчетность, документация |
— |
○ |
△ |
○ |
◎ |
Обозначения: ◎ — основная роль; ○ — вспомогательная роль; △ — эпизодическая роль; — — нецелесообразно использовать как основной механизм.
Из таблицы 1 следует, что LLM не стоит описывать одной общей формулой «аналитический помощник». На ранних стадиях они помогают прояснять смысл данных и предлагать варианты преобразований, но требуют жесткой проверки. На поздних стадиях их ценность смещается к объяснению, подготовке текста и поддержке коммуникации между аналитиком и пользователем.
Таблица 2
Матрица применения ролей LLM по архитектурным измерениям
|
Роль |
Тип данных |
Скорость обновления |
Требования к качеству |
|
Ассистент очистки |
Таблицы, логи, текстовые поля |
Низкая-средняя; потоковый режим только с правилами |
Очень высокие; обязательна внешняя проверка |
|
Семантический интерпретатор |
Схемы, метаданные, смешанные артефакты |
Средняя-высокая |
Высокие; допустима человеко-машинная редактура |
|
Агент генерации запросов |
Структурированные и полуструктурированные данные |
Высокая, интерактивная |
Очень высокие; нужна sandbox-проверка |
|
Контролер качества |
Все данные и промежуточные артефакты |
Любая, особенно непрерывная |
Критические |
|
Интерпретатор результатов |
Агрегаты, графики, логи, summary-артефакты |
Периодическая или интерактивная |
Высокие; обязателен числовой grounding |
Таблица 3
|
Роль |
Стоимость хранения |
BI-нагрузка |
ML-нагрузка |
Governance |
|
Ассистент очистки |
Средняя из-за версионирования и логов ремонта |
Средняя |
Высокая |
Очень высокие |
|
Семантический интерпретатор |
Низкая-средняя |
Высокая |
Средняя |
Высокие |
|
Агент генерации запросов |
Низкая |
Очень высокая |
Низкая-средняя |
Очень высокие |
|
Контролер качества |
Средняя-высокая из-за аудита и provenance |
Высокая |
Высокая |
Максимальные |
|
Интерпретатор результатов |
Низкая |
Очень высокая |
Средняя |
Высокие |
Таблицы 2 и 3 показывают, что выбор роли зависит не от популярности LLM как технологии, а от профиля нагрузки. Если доминирует интерактивная BI-аналитика, наиболее заметным становится агент генерации запросов, но его необходимо связывать с контролером качества. Если приоритетом являются ML-задачи и подготовка признаков, большее значение получают ассистент очистки и семантический интерпретатор. В регуляторно чувствительных контурах все роли должны подчиняться требованиям governance и аудита.
Риски и ограничения применения LLM
Использование LLM в аналитике больших данных порождает не только локальные ошибки, но и системные риски. Первый риск — галлюцинации. Модель может уверенно объяснить аномалию, предложить преобразование или сформировать запрос, который выглядит профессионально, но не подтверждается исходными данными [21]. Второй риск — утечка данных через prompts, retrieval, внешние API или запоминание фрагментов обучающих данных [22], [23], [24]. Третий риск — потеря воспроизводимости, когда результат зависит от версии модели, промпта, температуры вывода, состава контекста и загрязнения бенчмарков [20], [25], [26].
Поэтому зрелая архитектура LLM4Data должна строиться не как свободный чат с данными, а как контролируемый контур. Минимальный вариант такого контура включает retrieval и контекст схемы, инструменты исполнения, формальные проверки, участие человека и аудит происхождения результата. Именно эта логика отражена на рисунке 2.
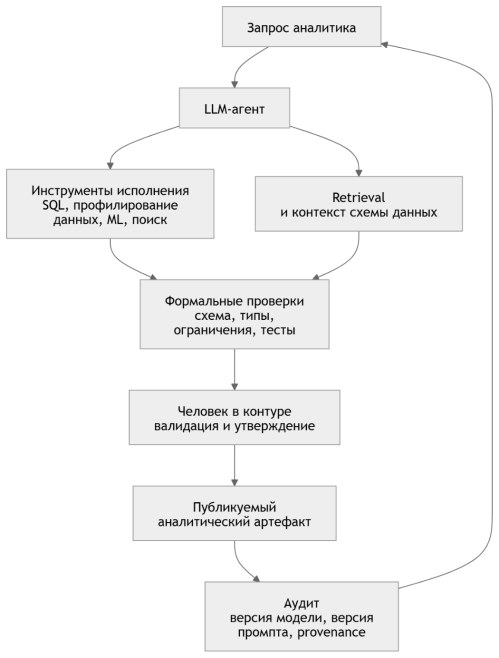
Рис. 2. Минимальный контур надежности LLM-аналитики
Таблица 4
Основные риски применения LLM в аналитике больших данных
|
Риск |
Где проявляется сильнее всего |
Теоретический эффект |
Минимальный контур снижения риска |
|
Галлюцинации |
Очистка, генерация запросов, объяснение результатов |
Ложные преобразования и интерпретации попадают в официальную аналитику |
Retrieval, schema-aware ограничения, sandbox-исполнение, self-check, human review |
|
Утечки данных |
Приватные датасеты, prompts с чувствительными полями, внешние API |
Нарушение конфиденциальности и нормативного соответствия |
Локальный inference, редактирование чувствительных атрибутов, журнал доступа, policy enforcement |
|
Потеря воспроизводимости |
Benchmarking, агентные цепочки, long-running analysis |
Невозможность повторить результат и проверить валидность вывода |
Версионирование модели и промптов, фиксированные инструменты, contamination-aware оценка, аудит |
Особенно важно, что перечисленные риски не устраняются простым запретом на «неправильные» промпты. Если в организации нет контроля доступа, версионирования, журналирования и политики работы с чувствительными признаками, LLM лишь делает уже существующие проблемы менее заметными. Приватность в LLM4Data связана не только с сетевой безопасностью, но и с тем, какие поля попадают в контекст модели, какие результаты сохраняются и кто может повторно использовать промежуточные артефакты [22], [23], [24].
Риск воспроизводимости также имеет академическое значение. Если одна и та же система в разные моменты времени генерирует разные правила очистки, разные SQL-запросы или разные текстовые выводы, то исследователь не может уверенно отделить устойчивый результат от случайной вариации модели. Поэтому LLM следует проектировать как вероятностного помощника, а не как самостоятельный источник аналитической истины [20], [25], [26].
Заключение
Проведенный анализ показывает, что большие языковые модели в конвейере больших данных следует рассматривать как слой семантического посредничества между человеком, данными и формальными инструментами вычисления. Они особенно полезны там, где требуется связать естественный язык с таблицей, схемой, запросом, метаданными или объяснением результата. Однако там, где требуется строгая корректность, LLM должны работать только вместе с внешней проверкой.
Предложенная классификация выделяет пять ролей LLM: ассистент очистки, семантический интерпретатор, агент генерации запросов, контролер качества и интерпретатор результатов. Эти роли не заменяют стадии pipeline, а накладываются на них и усиливают отдельные переходы между данными, формальными процедурами и аналитическим выводом.
Главный практический вывод состоит в том, что автоматизация аналитики с помощью LLM должна начинаться не с выбора модели, а с определения границ автономии. В одних случаях модель может только предлагать варианты, в других — формировать запрос для последующей проверки, в третьих — объяснять уже рассчитанные показатели. Чем выше требования к качеству, приватности и governance, тем меньше должно быть автономного исполнения и тем сильнее должен быть контур проверки.
Таким образом, LLM перспективны не как замена статистики, СУБД, BI-платформ или систем машинного обучения, а как управляемая надстройка над ними. Научная ценность предложенной рамки состоит в том, что она переводит обсуждение LLM в аналитике больших данных из общего утверждения о «полезности искусственного интеллекта» в более точный вопрос: какую роль модель выполняет, на каком этапе pipeline она подключается и каким способом проверяется ее результат.
Литература:
- Li G., Wang J., Zhang C., Wang J. Data+AI: LLM4Data and Data4LLM // Companion of the 2025 International Conference on Management of Data. 2025. DOI: 10.1145/3722212.3725641.
- Zha D., Bhat Z. P., Lai K.-H. et al. Data-centric Artificial Intelligence: A Survey // ACM Computing Surveys. 2025. Vol. 57, no. 5. P. 1–42. DOI: 10.1145/3711118.
- Trummer I. From BERT to GPT-3 Codex: Harnessing the Potential of Very Large Language Models for Data Management // Proceedings of the VLDB Endowment. 2022. Vol. 15, no. 12. P. 3770–3773. DOI: 10.14778/3554821.3554896.
- Li G., Zhou X., Zhao X. LLM for Data Management // Proceedings of the VLDB Endowment. 2024. DOI: 10.14778/3685800.3685838.
- Lu W., Zhang J., Fan J. et al. Large language model for table processing: a survey // Frontiers of Computer Science. 2025. DOI: 10.1007/s11704–024–40763–6.
- Liu T., Wang F., Chen M. Rethinking Tabular Data Understanding with Large Language Models // Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2024. P. 450–482. DOI: 10.18653/v1/2024.naacl-long.26.
- Dong Y., Oyamada M., Xiao C., Zhang H. On the Use of Large Language Models for Table Tasks // Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2024. DOI: 10.1145/3627673.3679100.
- Shi L., Tang Z., Zhang N., Zhang X., Yang Z. A Survey on Employing Large Language Models for Text-to-SQL Tasks // ACM Computing Surveys. 2025. DOI: 10.1145/3737873.
- Gao D., Wang H., Li Y. et al. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation // Proceedings of the VLDB Endowment. 2024. Vol. 17, no. 5. P. 1132–1145. DOI: 10.14778/3641204.3641221.
- Biester F., Abdelaal M., Del Gaudio D. LLMClean: Context-Aware Tabular Data Cleaning via LLM-Generated OFDs // New Trends in Database and Information Systems. 2024. DOI: 10.1007/978–3–031–70421–5_7.
- Naeem Z. A., Ahmad M. S., Eltabakh M., Ouzzani M., Tang N. RetClean: Retrieval-Based Data Cleaning Using LLMs and Data Lakes // Proceedings of the VLDB Endowment. 2024. DOI: 10.14778/3685800.3685890.
- Han S., Yoon J., Arik S. O., Pfister T. Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning // Proceedings of Machine Learning Research. 2024. DOI: 10.5555/3692070.3692765.
- Gebru T., Morgenstern J., Vecchione B. et al. Datasheets for Datasets // Communications of the ACM. 2021. DOI: 10.1145/3458723.
- Pushkarna M., Zaldivar A., Kjartansson O. et al. Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI // FAccT 2022. 2022. P. 1776–1826. DOI: 10.1145/3531146.3533231.
- Reynolds-Cuéllar P., Wong-Villacres M., Alvarado Garcia A., Precel H. From Reflection to Repair: A Scoping Review of Dataset Documentation Tools // CHI 2026. 2026. DOI: 10.1145/3772318.3791344.
- Sharma M., Gogineni A. K., Ramakrishnan N. Neural Methods for Data-to-text Generation // ACM Transactions on Intelligent Systems and Technology. 2024. DOI: 10.1145/3660639.
- Zhang Z., Li Y. et al. LLM-LADE: Large language model-based log anomaly detection with explanation // Knowledge-Based Systems. 2025. Vol. 326. Art. 114064. DOI: 10.1016/j.knosys.2025.114064.
- Essabri M. A., Rebii J., Erradi M. Tool Augmented LLMs for Big Data Analysis // Networked Systems. 2024. DOI: 10.1007/978–3–031–67321–4_7.
- Sun M., Han R., Jiang B. et al. A Survey on Large Language Model-based Agents for Statistics and Data Science // The American Statistician. 2025. DOI: 10.1080/00031305.2025.2561140.
- Chang Y., Wang X., Wang J. et al. A Survey on Evaluation of Large Language Models // ACM Transactions on Intelligent Systems and Technology. 2024. DOI: 10.1145/3641289.
- Huang L., Yu W., Ma W. et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions // ACM Transactions on Information Systems. 2025. Vol. 43, no. 2. P. 1–55. DOI: 10.1145/3703155.
- Das B. C., Amini M. H., Wu Y. Security and Privacy Challenges of Large Language Models: A Survey // ACM Computing Surveys. 2025. DOI: 10.1145/3712001.
- Yan B., Li K., Xu M. et al. On Protecting the Data Privacy of Large Language Models: A Survey // 2024 International Conference on Meta Computing. 2024. DOI: 10.1109/ICMC60390.2024.00008.
- Carlini N., Tramèr F., Wallace E. et al. Extracting Training Data from Large Language Models // 30th USENIX Security Symposium. 2021. DOI: 10.48550/arXiv.2012.07805.
- Chen S., Chen Y., Li Z. et al. Benchmarking Large Language Models Under Data Contamination: A Survey from Static to Dynamic Evaluation // Proceedings of EMNLP 2025. 2025. P. 10080–10098. DOI: 10.18653/v1/2025.emnlp-main.511.
- Zhang H., Lin Y., Wan X. PaCoST: Paired Confidence Significance Testing for Benchmark Contamination Detection in Large Language Models // Findings of ACL: EMNLP 2024. 2024. DOI: 10.18653/v1/2024.findings-emnlp.97.

