В статье автор описывает процесс автоматизированной разметки набора текстовых данных посвящённых тематике вакцинации с применением больших языковых моделей.
Ключевые слова: анализ больших данных, компьютерная лингвистика, большие языковые модели, llm-модели.
В рамках работы с большими текстовыми данными частой проблемой является получение размеченных данных. Первичные данные могут содержать тексты, тематика которых не соответствует требованиям исследования. Существует несколько способов разметки данных. Таким способом может быть ручная разметка. Эксперт или несколько экспертов вручную размечают набор текстовых данных, принимая решение об их релевантности. Этот способ, пускай и может считаться надёжным, обладает рядом ограничений, которые осложняют его применение для большого объёма данных.
Альтернативой ручной разметке может быть автоматизированная разметка. В настоящее время большие языковые модели (LLM-модели) могут упростить и ускорить разметку текстов. Разметка текста является задачей классификации, которую LLM-модели решают весьма успешно [1] [3].
В рамках магистерского исследования была проведена автоматизированная разметка датасета, собранного на основе открытых данных социальной сети «Вконтакте». Часть набора данных представлена на рисунке 1.
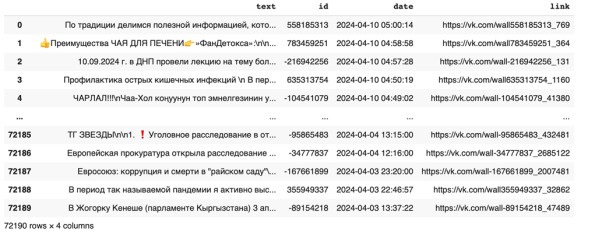
Рис. 1. Набор данных из социальной сети «Вконтакте»
Набор данных собирался с помощью запросов по ключевым словам с помощью API Вконтакте. В наборе данных присутствуют как тексты, посвящённые тематике вакцинации, так и тексты, которые тематике не соответствуют.
Для верификации тематики использовалась llm-модель mixtral-8x7b, размещённая на ресурсах сервиса Groq Cloud. В архитектуре mistral, на которой основывается вышеупомянутая llm-модель, используются технологии сосредоточенного внимания по группам запросов (Grouped-query attention, GQA) и скользящего окна внимания (Sliding window attention, SWA), что позволяет обрабатывать большие запросы с меньшими затратами на вычисление [2].
Для того, чтобы обеспечить работоспособность модели был создан технический промпт — набор инструкций, который определяет ожидаемый результат работы модели. Технический промпт представлен на рисунке 2.

Рис. 2. Технический промпт для llm-модели mixtral-8x7b
Данный промпт указывает модели, что тексты необходимо сортировать по 6 категориям в зависимости от содержания текстов, а также что модели необходимо объяснить, почему была выбрана именно это категория. Результат необходимо оформить как json.
Запросы к Groq Cloud отправляются с помощью библиотеки groq и библиотеки requests для языка программирования python. Листинг запроса представлен на рисунке 3.
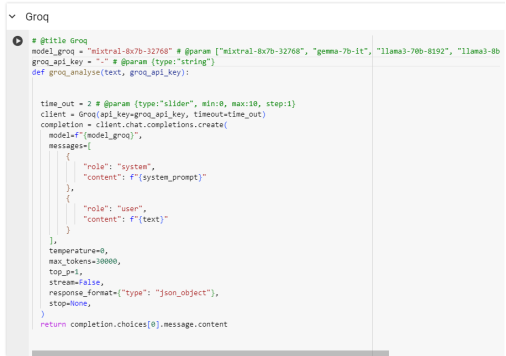
Рис. 3. Запрос к Groq Cloud
При работе с API существует вероятность ошибок. Именно поэтому был написан алгоритм обработки ошибок, представленный на рисунке 4.
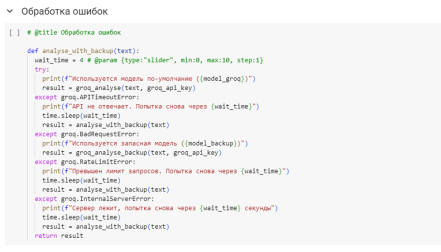
Рис. 4. Алгоритм обработки ошибок
Алгоритм верификации построен следующим образом. На вход модели подаётся pandas-датафрейм, содержащий не более 14400 строк, итеративно обрабатываются строки: извлекается текстовая информация, которая вместе с системным промптом формирует запрос к llm-модели. На выходе получается либо ошибка, в таком случае запрос отправляется снова спустя какое-то время, либо ответ в формате json, который в свою очередь добавляется в результирующий датафрейм. Датафрейм сохраняется на Google Drive автоматически. Также реализована возможность продолжить обработку с итерации, на которой обработка прервалась даже спустя продолжительное время. Листинг алгоритма верификации представлен на рисунке 5.
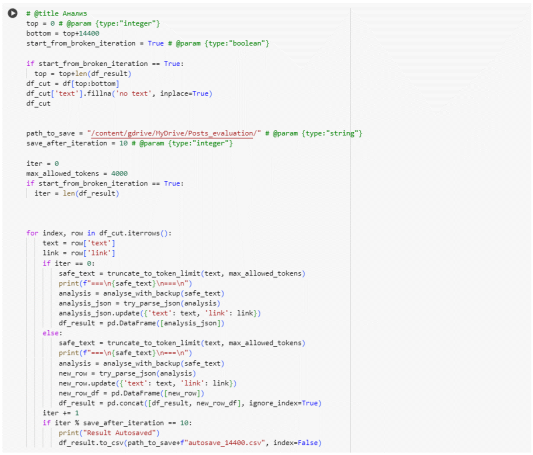
Рис. 5. Алгоритм выставления метки
Обработка набора данных заняла около 504 часов. Результирующий датасет представлен на рисунке 6.

Рис. 6. Список постов с меткой релевантности
Основным фактором, влияющим на скорость обработки, были ограничения платформы google colab, на которых запускался алгоритм и ошибками на стороне серверов Groq Cloud.
Литература:
1. Chae Y., Davidson T. Large Language Models for Text Classification: From Zero-Shot Learning to Fine-Tuning [Электронный ресурс]. — 2023. — URL: https://doi.org/10.31235/osf.io/sthwk (дата обращения: 28.05.2024)
2. Jiang A. Q., Sablayrolles A. и др. Mistral 7B [Электронный ресурс] / Jiang A. Q., Sablayrolles A., Mensch A., Bamford C., Chaplot D. S., de las Casas D., Bressand F., Lengyel G., Lample G., Saulnier L., Lavaud L. R. L., Lachaux M.-A., Stock P., Le Scao T., Lavril T., Wang T., Lacroix T., El Sayed W. / arXiv:2310.06825 [cs.CL], 2023. — Электрон. дан. —. Режим доступа: https://arxiv.org/abs/2310.06825 (дата обращения: 24.04.2024).
3. Zhang Y., Wang M., Ren C., Li Q., Tiwari P., Wang B., Qin J. Pushing The Lim-it of LLM Capacity for Text Classification [Электронный ресурс] // arXiv preprint arXiv:2402.07470. — 2024. URL: https://arxiv.org/abs/2402.07470 (дата обращения: 20.05.2024).

